
The "Model Wars" have entered a new phase. In the early days of generative AI, success was measured by who had the most parameters or the lowest latency. But as AI moves from the lab into enterprise product stacks, a new challenge has emerged: delivery.
It's no longer enough to have a great model. You need a way to deploy it, test it, and govern it without breaking your product.
To scale AI, you don't just need better GPUs; you need agentic infrastructure. At the center of that infrastructure is a critical component that most teams are overlooking: the feature flag.
In traditional software, feature flags control whether code runs. In AI systems, feature flags control how intelligence behaves.
 Image source: Optimizely
Image source: Optimizely
The delivery layer: Scaling beyond the model
We are moving away from monolithic AI, where a single model powers an entire feature, to agentic systems where multiple models, prompts, and tools interact dynamically. The model is just one part of the equation.
The real bottleneck is the delivery layer. How do you roll out a new AI-powered search feature to 10% of your users to see if it actually improves conversion? How do you swap a backend LLM without your users noticing a change in latency?
Scaling AI requires a governance layer that separates the "logic" of the model from the "delivery" of the feature. This is exactly what Optimizely Feature Experimentation (FX) provides.
Model A/B testing: The objective measure of business impact
The assumption that "more powerful equals better" is often wrong in AI. GPT-4o might be superior for creative reasoning, but Claude 3.5 Sonnet might outperform it on cost-efficiency for your specific use case. Without a way to compare in real-world production environments, you're just guessing.
Optimizely FX enables Model A/B Testing at the code level, and it's the only objective way to measure the true business impact of LLM-driven capabilities. By using flag variables, you can bucket users into different model configurations concurrently and measure what actually moves the needle: revenue per user, task completion rate, and conversion. Not "chat accuracy."
The model is no longer the product. The configuration is. A single flag can control the entire AI stack:
{
"model_id": "gpt-4o",
"system_prompt_variant": "concise-assistant-v2",
"temperature": 0.3,
"retrieval_profile": "semantic-v2",
"tool_policy": "search-only",
"fallback_behavior": "rule-based",
"token_budget": 1200
}
This means AI Engineers can experiment on how a model is instructed, constrained, and equipped, not just which model runs. That's where FX stops being a deployment tool and starts being a full AI control plane.
Managing risk: Guardrails and progressive rollouts
The biggest fear for any CTO or VP of Product is the AI hallucination that goes viral. Feature flags address this at two levels: alerting and rollout control.
Tiered alerting means you don't wait for a crisis. Well-instrumented AI deployments fire notifications at three severity levels before you ever touch the kill switch:
- Informational: A slight uptick in latency or token usage. Monitor closely.
- Warning: Hallucination rate crossing a threshold, CSAT dipping. Investigate.
- Critical: Conversion drop, error spike, model failing silently. Act now.
This connects directly to your observability tooling. When your LLM starts negatively impacting user experience, you need to know before your users do.
The kill switch remains your last line of defence. If an AI feature starts behaving unexpectedly, you flip the switch in the Optimizely UI to revert to a stable version or disable the feature entirely. No emergency PR required.
Progressive rollouts give you the confidence to move fast without breaking things. Rather than binary on/off, each stage is a gate: internal team first, then 1%, 5%, 10%, 25%, 100%.
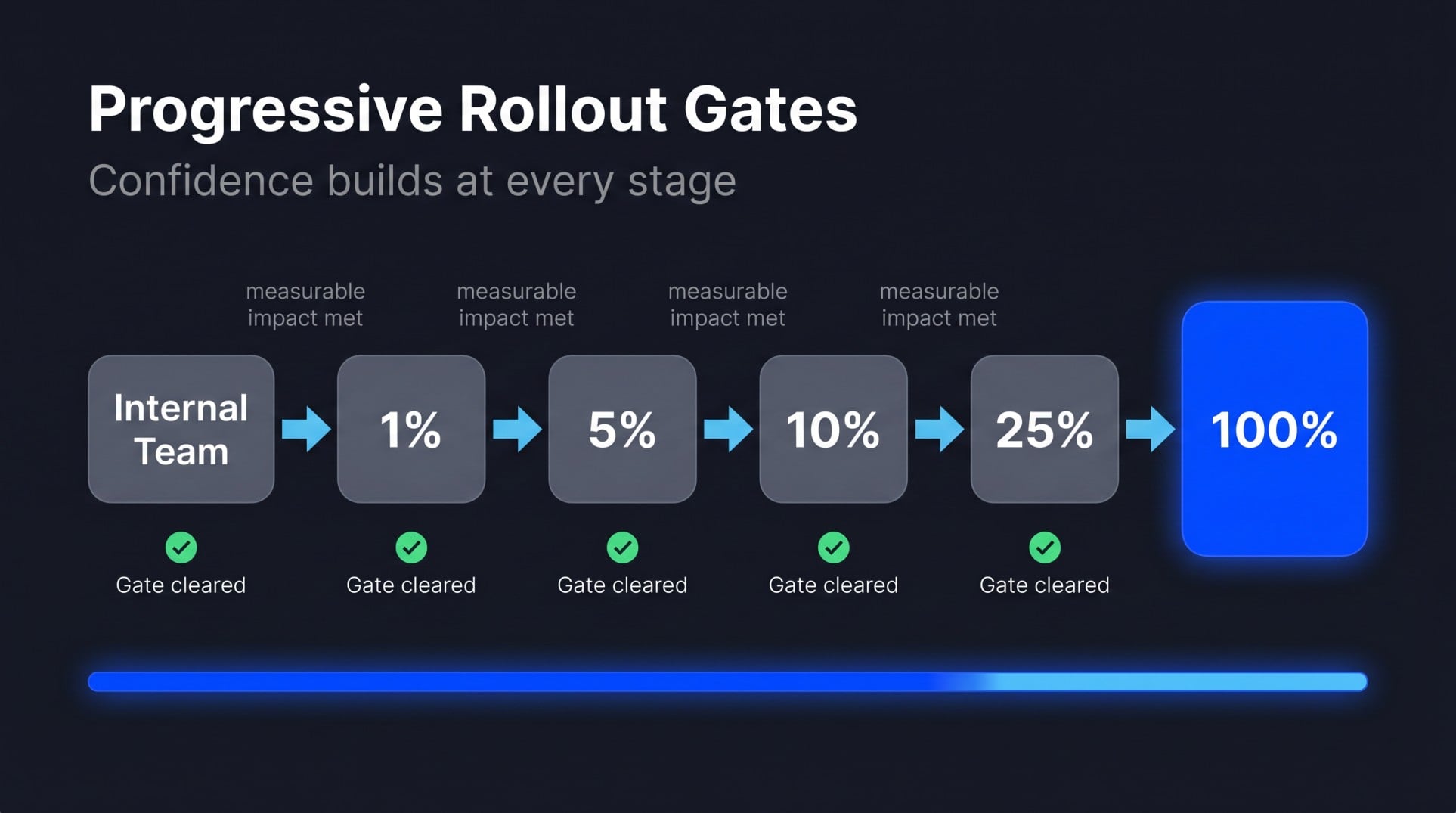 Image source: Optimizely
Image source: Optimizely
You only clear each gate when measurable impact at that audience size meets your threshold. Confidence builds with every stage.
Evals vs. feature flags: What's the difference? Evals assess the quality of your model's outputs, catching hallucinations, scoring coherence, and flagging when LLM responses go off the rails. They're your early warning system at the model layer. Feature flags operate at the delivery layer: controlling who sees what, running A/B tests to measure business impact, and giving you rollout control in production. Both are essential. Evals tell you if something is wrong; feature flags let you act on it.
For AI specifically, teams should be tracking at every rollout stage:
- Hallucination rate: via human eval sample or automated scoring tools
- Task completion rate: did users actually accomplish what they came to do?
- Latency p50/p95: model swaps carry hidden latency costs that compound at scale
- Revenue per user / conversion rate: the business KPI that validates everything else
- Error rate and fallback triggers: how often is the model failing silently?
- User satisfaction (CSAT/thumbs): qualitative signal captured at scale
The agentic feedback loop: Today and where we're heading
The vision for AI infrastructure is self-optimizing: agents that learn from how their output performs in production.
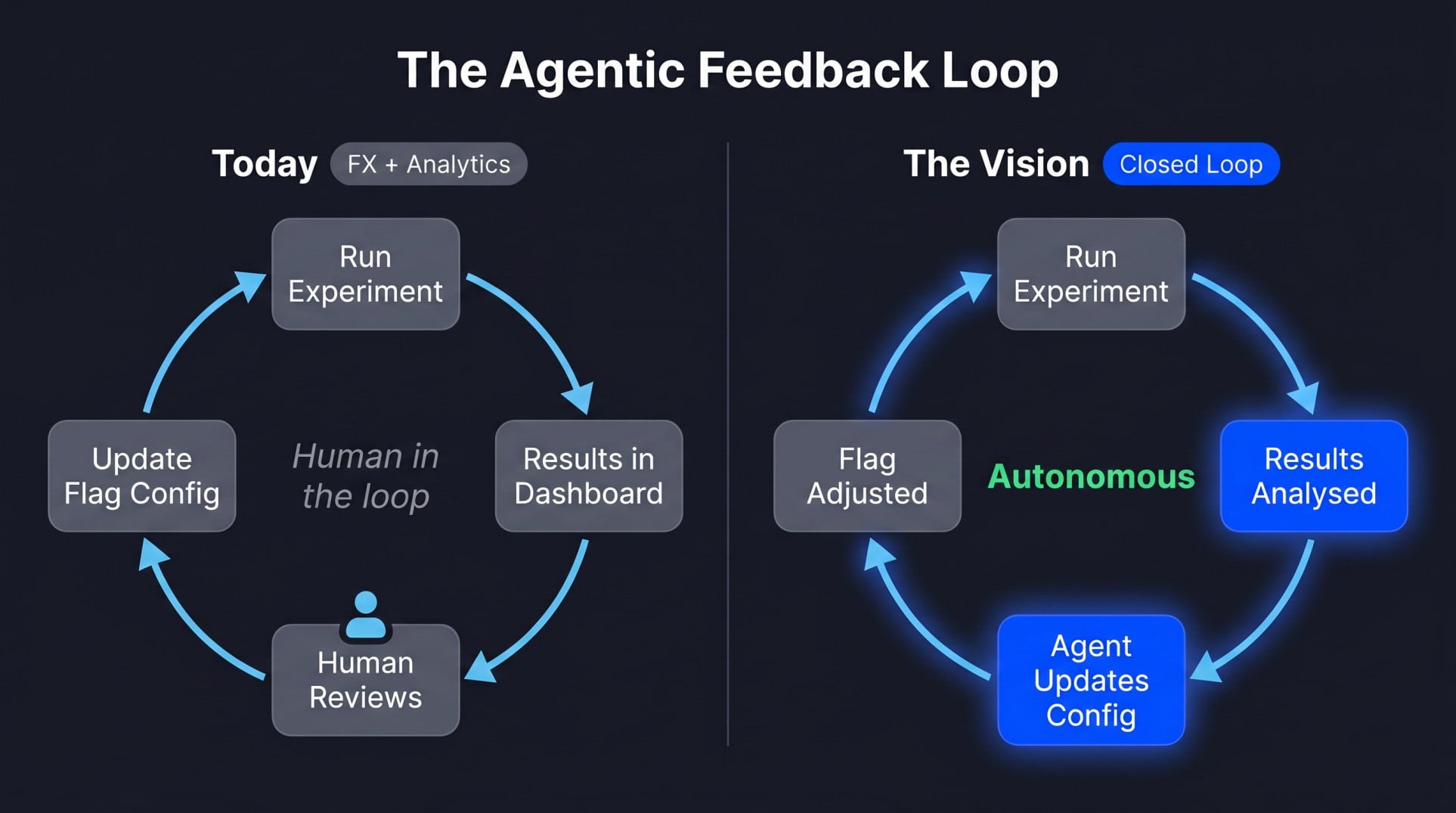 Image source: Optimizely
Image source: Optimizely
- Today with FX + analytics: Experiment results, including click-through rates, conversions, and engagement signals, are surfaced in Optimizely dashboards. Teams review which configuration produced the winning outcome and manually update flag configurations. The feedback loop exists, but requires a human in it. That's the right model for most teams right now.
- The vision: Agents that can read experiment outcomes and autonomously adjust their own configuration, updating a system prompt, adjusting a retrieval strategy, or shifting traffic toward a winning variant, without human intervention. A truly closed loop. This is where the industry is heading, and where Optimizely is building toward.
Being explicit about this distinction builds more trust with a technical audience than overpromising. Engineers want to know what ships today. The roadmap earns credibility when it's framed honestly.
Conclusion: The Essential Layer
The companies that win the AI race won't just be the ones with the smartest models. They'll be the ones with the most resilient, testable, and governed infrastructure.
The competitive advantage in AI is no longer just the model you choose. It's the infrastructure you build around it. Feature flags are the foundational control plane that makes AI safe to ship, testable at scale, and governable in production.
Treat your AI stack like a software delivery problem, not a research problem. Optimizely FX is the bridge.
Ready to build your agentic infrastructure? Learn more about Optimizely Feature Experimentation.



- Sist oppdatert:22.05.2026 03:35:47