
Produktanalyseverktøy som Amplitude og Mixpanel har eksistert i over ti år, og de ble utviklet før den moderne datastakken som begynner å bli vanlig nå. Det er nå et gap mellom den verdenen disse analyseverktøyene ble utviklet for, og hvordan team jobber med bedriftsdata i dag. Dette fører til et viktig spørsmål: Hvordan bør produktanalyse utvikles for å passe inn i den moderne datastakken?
For å svare på det må vi begynne med å ta opp et grunnleggende spørsmål: Hva er den moderne datastakken?
Den moderne datastakken
Når det gjelder analyse, definerer vi den moderne datastakken ved hjelp av følgende egenskaper:
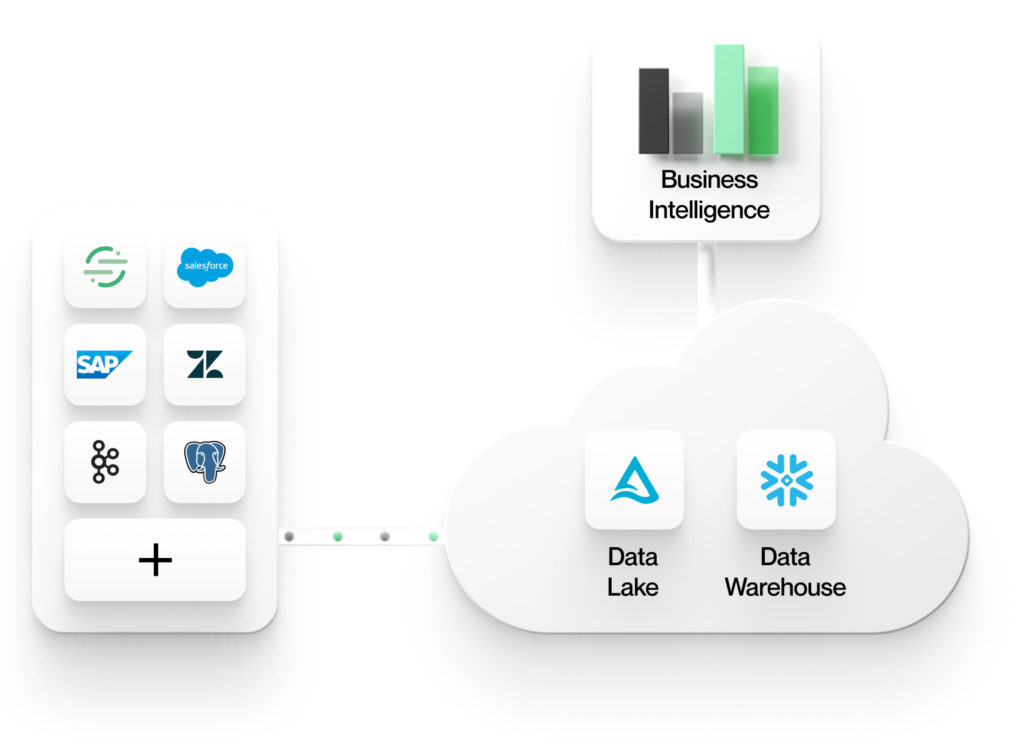
1. Alle data kommer til et felles, sentralt datalager i skyen
Dette lageret kan være en datasjø bygget på et objektlager som AWS S3, eller det kan være et datavarehus som Snowflake. Uansett om man bruker en lakehouse- eller warehouse-arkitektur, standardiserer bedriftene det å ha alle data i sentrale lagre. Et felles sentrallager gir fordeler når det gjelder konsistens, sikkerhet, styring og administrasjon.
2. Analyseverktøyene jobber direkte med data i disse lagrene
Analyseverktøy i den moderne datastakken, for eksempel verktøy for Business Intelligence (BI) eller AI/ML, trenger ikke å ETL-behandle dataene ut i andre datasiloer. Dette garanterer én enkelt sannhetskilde for dataene og gir konsistent analytisk innsikt på tvers av hele virksomheten. Ved å bruke åpne formater i datasjøen eller datalageret blir dataene tilgjengelige for alle verktøy, slik at du unngår leverandørinnlåsing. Å jobbe direkte i et sentralt lager gjør det også enklere å lære av dataene og handle på grunnlag av dem. All konteksten du trenger, er samlet på ett sted, i stedet for å være fordelt på flere siloer.
Status for produktanalyse
I motsetning til det sentrale datalageret som brukes av moderne datasystemer, er de fleste produktanalyseverktøyene som er tilgjengelige i dag, proprietære, inngjerdede silosystemer.
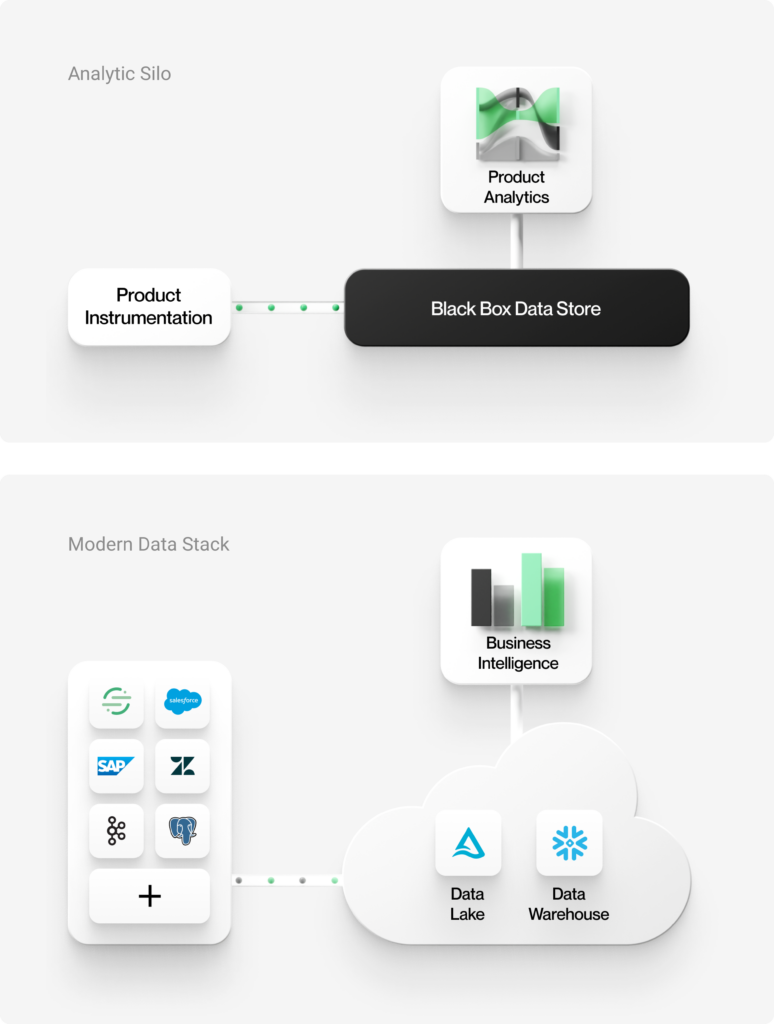
Data i siloer
Produktanalyseverktøyene jobber vanligvis med data i siloer. De har integrerte produktinstrumenteringsbiblioteker som samler inn og lagrer data i svarte bokser innenfor en lukket plattform. Selv om du bruker et frikoblet tredjeparts instrumentasjonsbibliotek, må dataene dine sendes til verktøyets black box-lagre for å kunne bruke et analyseverktøy.
Fordi disse produktanalyseverktøyene baserer seg på siloer, kan de bare arbeide med en delmengde av dataene dine, frakoblet fra det store flertallet av bedriftsdata i det sentrale datalageret ditt. I beste fall kan du hente inn et lite sett med egenskaper fra et datavarehus eller en datasjø ved hjelp av "omvendt ETL"-verktøy. Dessverre vil disse egenskapene bli hentet inn som enkle egenskaper med én verdi, og de må tvinges inn i en forhåndsinnstilt datamodell.
Som et resultat av denne silotilnærmingen er det vanskelig å knytte innsikt fra produktbruksdata til den bredere forretningseffekten. Disse systemene kan bare utføre analyser av én enkelt kanal, og mangler kontekst fra andre forretningssystemer som salg, support, Voice of Customer og økonomi.
Fragmentert analyse
Denne siloarkitekturen resulterer i fragmenterte analyser. Brukerne får analyser som er begrenset til bruk i produktet gjennom disse tradisjonelle produktanalyseverktøyene. Når de ønsker mer detaljert innsikt i kundeatferd utenfor produktet, må de kontakte datateknikk- og BI-teamene sine for å lage tilpassede rapporter. Det kan ta flere uker å kjøre denne analysen. Analytikerne må ETL-transformere data fra black box-lagrene, skrive komplekse SQL-spørringer og tilpasse BI-verktøy som ikke er skreddersydd for denne typen analyser.
Ikke bare er dette komplekst og kostbart, men du har nå analyser i to separate systemer uten mulighet til å dele kontekst eller sømløst flytte frem og tilbake mellom dem. Ofte er ikke datarørledninger koblet sammen, noe som gjør at analytikerne må jobbe med øyeblikksbilder (enkeltstående, tilpassede rapporter). Å ha flere datasiloer er et enormt TCO-problem for bedrifter.
I tillegg kommer bekymringer knyttet til sikkerhet og personvern. Det blir stadig viktigere at kundedata forblir innenfor rammene av bedriftskontrollerte lagre i stedet for å oppbevares andre steder i potensielt usikre og ikke-kompatible miljøer.
Produktanalyse i den moderne datastakken
La oss nå se hvordan produktanalyse bør se ut når den bygger på en moderne datastack.
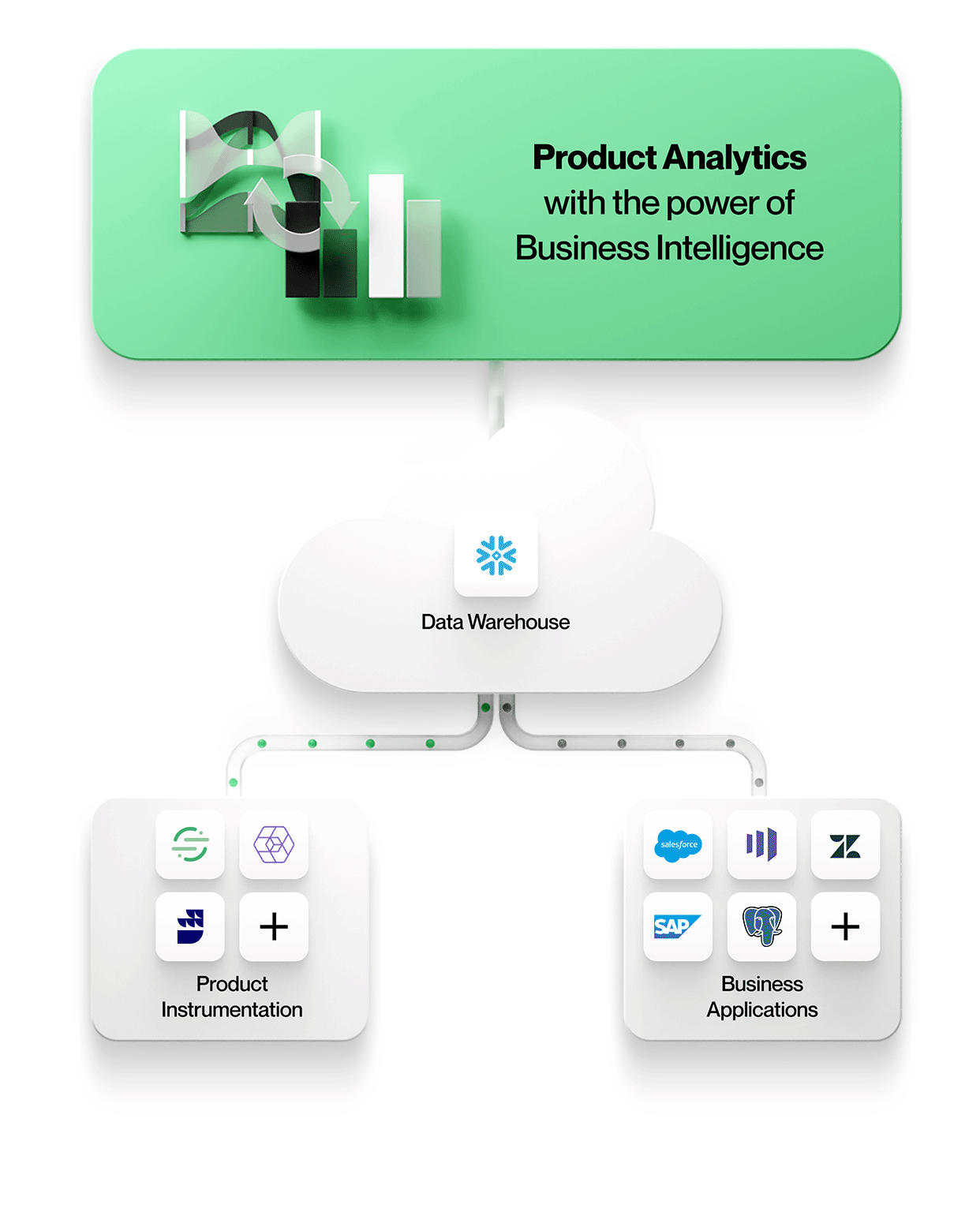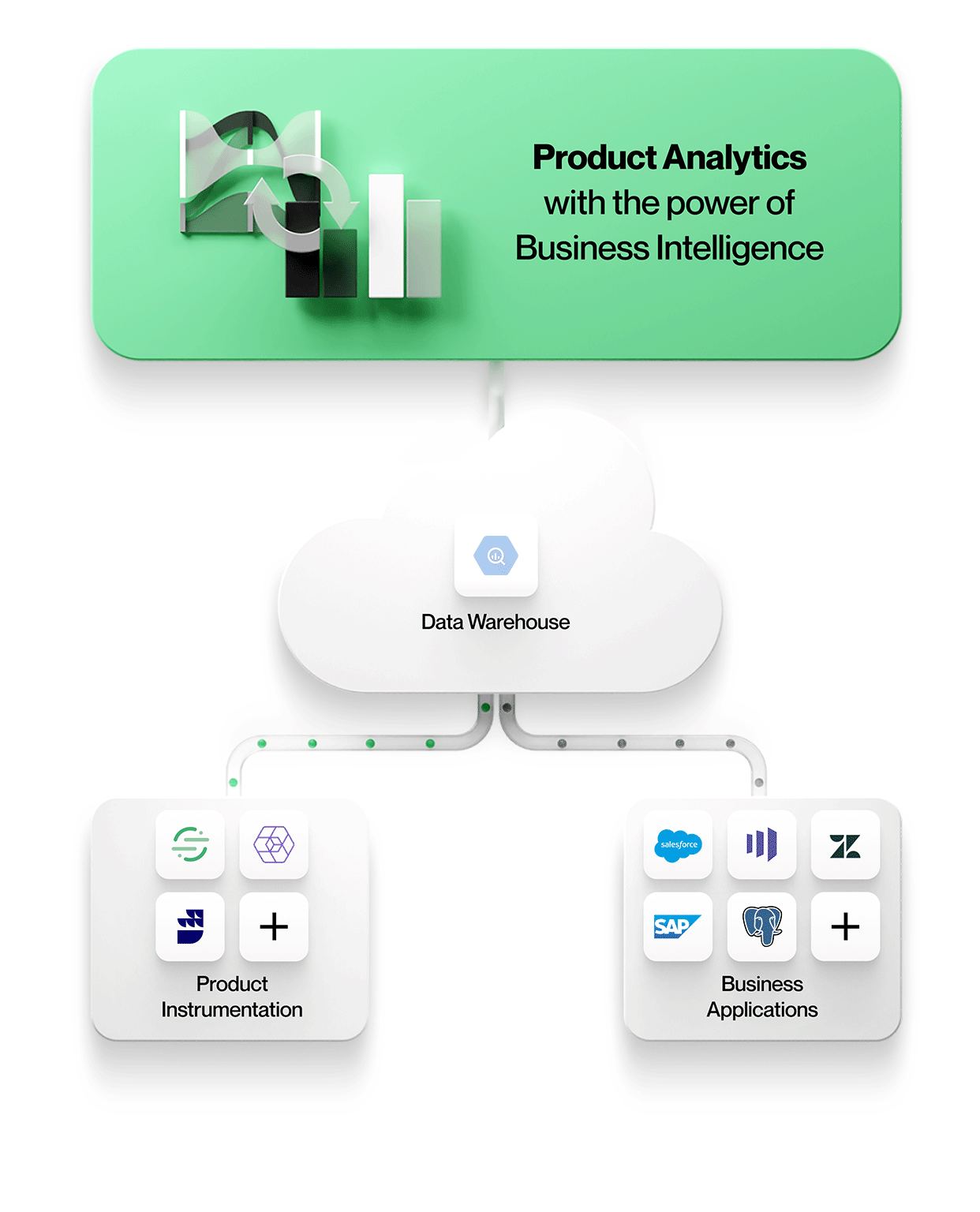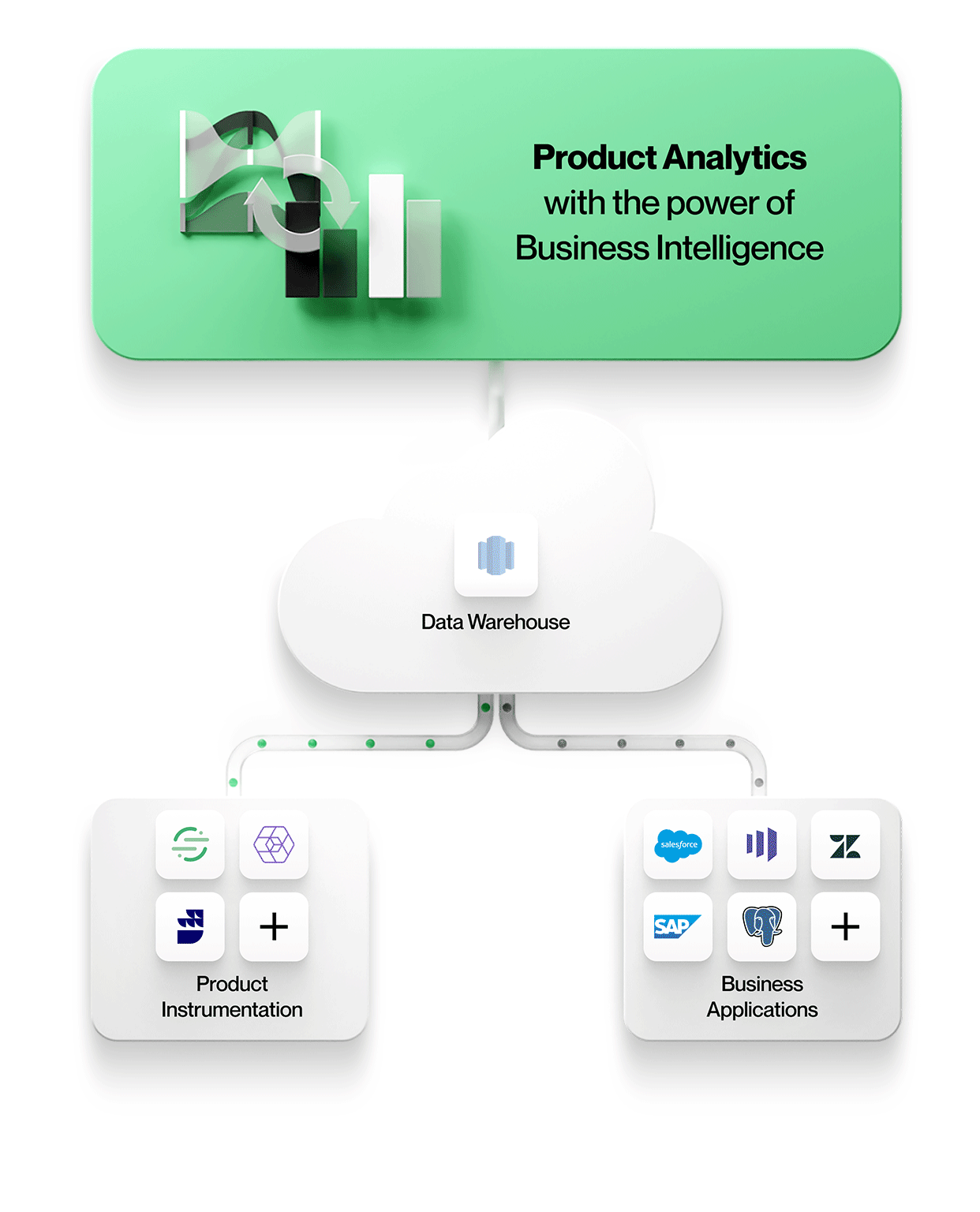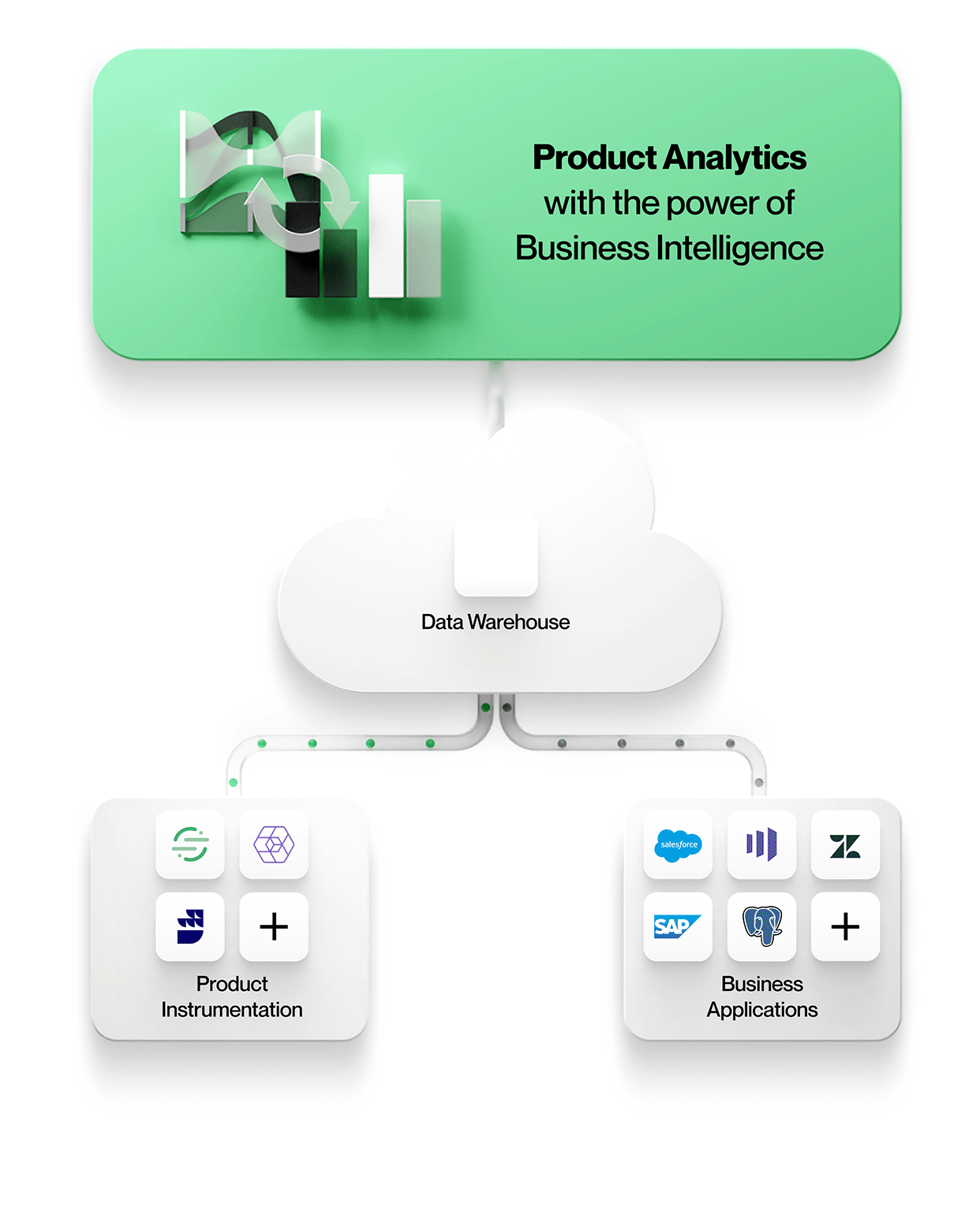
-
Produktinstrumenteringsdata lagres sammen med alle andre bedriftsdata
Alle data, inkludert produktinstrumentering, havner i samme sentrale datasjø eller datalager. Dette forenkler administrasjonen med ett sikkert, styrt lager, og man unngår datasiloer. -
Produktinstrumentering er frikoblet fra analyse
Produktinstrumentering er ikke meningsstyrt. Den dikterer ingen bestemt datamodell, og den tvinger deg heller ikke til å bruke ett bestemt verktøy for analyse.
Med frikoblet og upartisk instrumentering kan du modellere din unike virksomhet nøyaktig, i stedet for å tvinge deg til å bruke en leverandørdiktert datamodell. Det gjør også at de instrumenterte dataene kan brukes av alle analyseverktøy. Produkter som Snowplow og RudderStack muliggjør slik frikoblet instrumentering. -
Produktanalyseverktøyene arbeider direkte med data i den sentrale datasjøen eller datalageret i bedriften
For å muliggjøre kontekstrik produktanalyse må verktøyene innlemme data fra andre forretningssystemer i deres opprinnelige form. Dette betyr at man kan jobbe med enheter og deres relasjoner nøyaktig slik de vises i disse forretningssystemene, for eksempel med enheter som kontoer, kontrakter, inntekter og potensielle kunder fra Salesforce, billetter, SLA-er og oppgaver fra Zendesk eller kunder, prosjekter og nivåer fra NetSuite. Produktanalyser kan forstås i en kontekst og korreleres med forretningsresultater, noe som gjør analysene mer verdifulle og relevante for alle i organisasjonen.
Produktanalysedata bør også transformeres og spørres etter på samme måte som alle andre data, for eksempel ved å bruke DBT til datatransformasjon eller SQL til å spørre etter data med en relasjonsmodell. På denne måten kan du utnytte ekspertisen og verktøyene som allerede er i bruk i bedriften. Det gjør det også mulig for et hvilket som helst verktøy, for eksempel et AI/ML-verktøy eller en tilpasset applikasjon, å utnytte dataene på en enkel måte.
Alt i alt gir denne moderne arkitekturen for produktanalyse lavere TCO og større forretningseffekt. Fremtiden for produktanalyse er å forstå dataene dine med all deres kontekst.
Ønsker du å legge til moderne produktanalyse i datastakken din?
Optimizely Warehouse-Native Analytics tilbyr en neste generasjons plattform for produkt- og atferdsanalyse som er spesialbygget for den moderne datastakken.

Entreprenør, leder og produktleder med dokumentert erfaring med å utvikle og bygge innovative, vellykkede programvaresystemer i stor skala Selskapsbygger som har...
- Sist oppdatert:25.04.2025 21:30:35