Historien bak statistikkmotoren vår

Klassiske statistiske teknikker, som t-testen, er grunnfjellet i optimaliseringsbransjen, og hjelper bedrifter med å ta datadrevne beslutninger. Etter hvert som eksperimentering på nettet har eksplodert, er det nå klart at disse tradisjonelle statistiske metodene ikke passer for digitale data: Å bruke klassisk statistikk på A/B-testing kan føre til feilprosenter som er mye høyere enn de fleste eksperimentatorer forventer.
Både bransjeeksperter og akademiske eksperter har vendt seg til utdanning som løsningen. Ikke kikk! Bruk en kalkulator for utvalgsstørrelse! Unngå å teste for mange mål og variasjoner på en gang!
Men vi har konkludert med at det erpå tide at statistikken, og ikke kundene, endrer seg. Si farvel til den klassiske t-testen. Det er på tide med statistikk som er enkel å bruke, og som er tilpasset hvordan virksomheter faktisk fungerer.
I samarbeid med et team av Stanford-statistikere har vi utviklet Stats Engine, et nytt statistisk rammeverk for A/B-testing. Vi er glade for å kunne kunngjøre at fra og med 21. januar 2015 gir det resultater for alle Optimizely-kunder.
Dette blogginnlegget er langt, fordi vi ønsker å være helt åpne om hvorfor vi gjør disse endringene, hva endringene faktisk innebærer og hva dette betyr for A/B-testing i sin helhet. Følg med oss til slutten, så får du vite mer:
- Hvorfor vi laget Stats Engine: Internett gjør det enkelt å evaluere eksperimentresultater når som helst og kjøre tester med mange mål og variasjoner. Når disse intuitive handlingene kombineres med klassisk statistikk, kan de øke sjansen for å feilaktig erklære en vinner- eller tapervariant med over 5 ganger.
- Slik fungerer det: Vi kombinerer sekvensiell test og kontroll av falsk oppdagelsesrate for å levere resultater som er gyldige uavhengig av utvalgsstørrelse, og som samsvarer med feilraten vi rapporterer, til den feilen bedriftene bryr seg om.
- Hvorfor det er bedre: Stats Engine kan redusere sjansen for å feilaktig erklære en vinnende eller tapende variant fra 30 % til 5 % uten at det går på bekostning av hastigheten.
Hvorfor vi har laget en ny statistikkmotor
Tradisjonell statistikk er uintuitiv, lett å misbruke og gir penger på bordet.
For å få gyldige resultater fra A/B-tester som kjøres med klassisk statistikk, følger nøye eksperimentatorer et strengt sett med retningslinjer: Sett en minste påvisbar effekt og utvalgsstørrelse på forhånd, ikke kikk på resultatene, ikke test for mange mål og variasjoner samtidig.
Disse retningslinjene kan være tungvinte, og hvis du ikke følger dem nøye, kan du ubevisst introdusere feil i testene dine. Det er disse problemene med disse retningslinjene vi har forsøkt å løse med Stats Engine:
- Det er ineffektivt og lite intuitivt å forplikte seg til en påvisbar effekt og utvalgsstørrelse på forhånd.
- Hvis du ser på resultatene før du har nådd utvalgsstørrelsen, kan det oppstå feil i resultatene, og du kan komme til å handle på falske vinnere.
- Å teste for mange mål og variasjoner på en gang øker feilene på grunn av falske oppdagelser - en feilrate som kan være mye større enn den falske positivraten.
Å forplikte seg til en utvalgsstørrelse og en påvisbar effekt kan bremse deg.
Ved å fastsette en utvalgsstørrelse i forkant av en test unngår du å gjøre feil med tradisjonelle statistiske metoder. For å fastsette en utvalgsstørrelse må du også gjette hvilken minimum detekterbar effekt (MDE), eller forventet økning i konverteringsfrekvensen, du ønsker å se fra testen din. Hvis du gjetter feil, kan det få store konsekvenser for hvor raskt du tester.
Hvis du angir en liten effekt, må du vente på et stort utvalg for å få vite om resultatene er signifikante. Hvis du setter en større effekt, risikerer du å gå glipp av mindre forbedringer. Dette er ikke bare ineffektivt, det er heller ikke realistisk. De fleste kjører tester fordi de ikke vet hva som kan skje, og å forplikte seg på forhånd til et hypotetisk løft gir ikke mye mening.
Å kikke på resultatene øker feilprosenten.
Når data strømmer inn i eksperimentet ditt i sanntid, er det fristende å sjekke resultatene hele tiden. Du ønsker å implementere en vinner så snart du kan for å forbedre virksomheten din, eller stoppe en ufullstendig eller tapende test så tidlig som mulig, slik at du kan gå videre for å teste flere hypoteser.
Statistikere kaller denne konstante kikkingen for "kontinuerlig overvåking", og det øker sjansen for at du finner et vinnerresultat når det faktisk ikke finnes noe (selvfølgelig er kontinuerlig overvåking bare problematisk når du faktisk stopper testen tidlig, men du skjønner poenget). Å finne en insignifikant vinner kalles en falsk positiv, eller type I-feil.
Enhver test for statistisk signifikans du kjører, vil ha en viss sjanse for feil. Hvis du kjører en test med 95 % statistisk signifikans (med andre ord en t-test med en alfaverdi på 0,05), betyr det at du aksepterer en 5 % sjanse for at testen ville vist et signifikant resultat hvis dette var en A/A-test uten noen faktisk forskjell mellom variasjonene.
For å illustrere hvor farlig kontinuerlig overvåking kan være, simulerte vi millioner av A/A-tester med 5000 besøkende, og evaluerte sjansen for å gjøre en feil under ulike typer retningslinjer for kontinuerlig overvåking. Vi fant ut at selv konservative retningslinjer kan øke feilraten fra et mål på 5 % til over 25 %.
I vår undersøkelse erklærte mer enn 57 % av de simulerte A/A-testene feilaktig en vinner eller taper minst én gang i løpet av forløpet, selv om det bare var kortvarig. Med andre ord, hvis du hadde sett på disse testene, ville du kanskje ha lurt på hvorfor A/A-testresultatene utropte en vinner. Økningen i feilprosent er fortsatt meningsfull selv om du ikke ser etter hver besøkende. Hvis du ser etter hver 500. besøkende, øker sjansen for å avgi en falsk erklæring til 26 %, mens hvis du ser etter hver 1000. besøkende, øker den samme sjansen til 20 %.
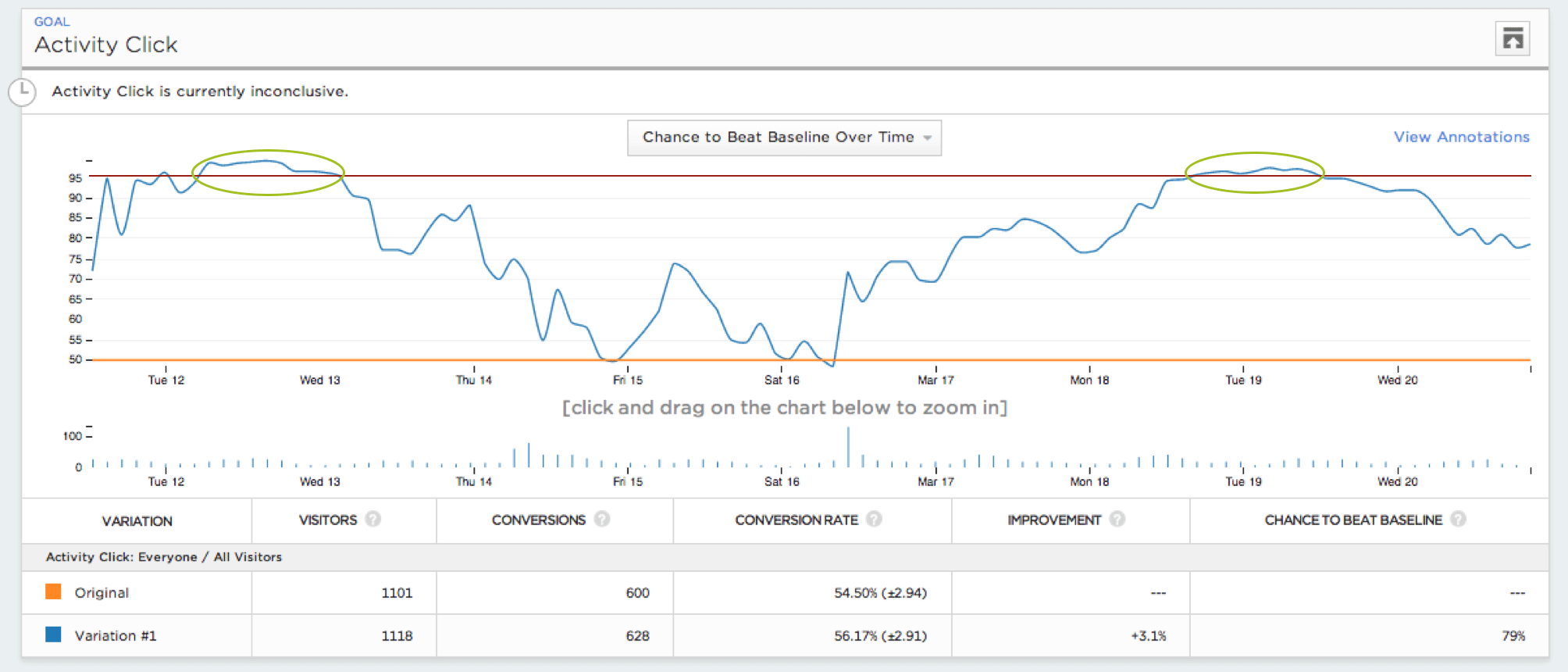
Denne grafen over det statistiske signifikansnivået for en A/A-test over tid viser hvor eksperimentatoren ville ha sett et signifikant resultat hvis hun hadde overvåket testen kontinuerlig.
Selv om du er klar over dette problemet, kan fornuftige "løsninger" fortsatt føre til høye feilprosenter. Anta for eksempel at du ikke stoler på et signifikant resultat for A/B-testen din. I likhet med mange Optimizely-brukere bruker du kanskje en kalkulator for utvalgsstørrelse mens testen allerede er i gang, for å avgjøre om testen har kjørt lenge nok. Å bruke kalkulatoren til å justere utvalgsstørrelsen mens testen kjører, er det som kalles en "post-hoc-beregning", og selv om det reduserer risikoen ved kontinuerlig overvåking, fører det fortsatt til feilprosenter på rundt 25 %.
Frem til nå har den eneste måten å beskytte seg mot disse feilene på vært å bruke utvalgsstørrelseskalkulatoren før du starter testen, og deretter vente til testen har nådd utvalgsstørrelsen før du tar beslutninger basert på resultatene.
Den gode nyheten er at det faktisk finnes en ganske enkel, men elegant statistisk løsning som lar deg se resultater som alltid er gyldige, når som helst, uten at du trenger å gjette deg til en minste påvisbar effekt på forhånd. Det kalles sekvensiell test, og vi skal diskutere det mer i detalj senere.
Å teste mange mål og variasjoner samtidig fører til flere feil enn du kanskje tror.
En annen fallgruve ved bruk av tradisjonell statistikk er å teste mange mål og variasjoner samtidig ("multiple comparisons" eller "multiple testing problem.") Dette skjer fordi tradisjonell statistikk kontrollerer feil ved å kontrollere for falsk positiv rate. Men denne feilen, den du setter i signifikansgrensen din, samsvarer ikke med sjansen for å ta en feil forretningsbeslutning.
Feilraten du egentlig ønsker å kontrollere for å korrigere for problemet med multiple tester, er den falske oppdagelsesraten. I eksempelet nedenfor viser vi hvordan det å kontrollere for 10 % falske positive resultater (90 % statistisk signifikans) kan føre til en 50 % sjanse for å ta en feil forretningsbeslutning på grunn av falske funn.
Tenk deg at du tester 5 varianter av produktet eller nettstedet ditt, som hver har 2 mål som suksessfaktorer. En av disse variantene gjør det bedre enn referansealternativet og blir korrekt erklært som vinner. Ved en ren tilfeldighet ville vi forvente å se ytterligere én variant som feilaktig blir erklært som vinner (10 % av de 9 gjenværende mål-variasjonskombinasjonene). Vi har nå to variasjoner som erklæres som vinnere.
Selv om vi har kontrollert for 10 % falske positive resultater (1 falsk positiv), har vi et mye høyere (50 %) forhold mellom falske og gode resultater, noe som øker sjansen for å ta feil beslutning betraktelig.

I dette eksperimentet er det to vinnere av ti målvariasjonskombinasjoner som er testet. Bare én av disse vinnerne er faktisk forskjellig fra grunnlinjen, mens den andre er en falsk positiv.
Det er farlig å kontrollere for andelen falske positive, fordi eksperimentlederen ubevisst blir straffet for å teste mange mål og variasjoner. Hvis du ikke er forsiktig, påtar du deg en større praktisk risiko enn du er klar over. For å unngå dette problemet i tradisjonell A/B-testing må du alltid huske på antall eksperimenter som kjøres. Ett avgjørende resultat fra 10 tester er noe annet enn ett fra 2 tester.
Heldigvis finnes det en prinsipiell måte å få feilprosenten i eksperimentet til å samsvare med den feilprosenten du tror du får. Stats Engine oppnår dette ved å kontrollere feil som kalles falske funn. Feilraten du angir i signifikansgrensen med Stats Engine, vil gjenspeile den reelle sjansen for å ta en feil forretningsbeslutning.
Slik fungerer Stats Engine
Stats Engine kombinerer innovative statistiske metoder for å gi deg pålitelige data raskere.
I løpet av de siste fire årene har vi hørt fra kundene våre om de ovennevnte problemene, og vi visste at det måtte finnes en bedre måte å løse dem på enn en kalkulator for utvalgsstørrelse og flere pedagogiske artikler.
Vi inngikk et samarbeid med statistikere fra Stanford for å utvikle et nytt statistisk rammeverk for A/B-testing som er kraftig, nøyaktig og, viktigst av alt, uanstrengt. Denne nye statistikkmotoren består av to metoder: sekvensiell test og kontroll av falsk oppdagelsesrate.
Sekvensiell test: Ta beslutninger så snart du ser en vinner.
I motsetning til Fixed Horizon-testing, som forutsetter at du bare vil evaluere eksperimentdataene dine på ett tidspunkt, med en bestemt utvalgsstørrelse, er sekvensiell testing designet for å evaluere eksperimentdata etter hvert som de samles inn. Sekvensielle tester kan stoppes når som helst med gyldige resultater.
Eksperimentatorer har sjelden en fast utvalgsstørrelse tilgjengelig, og målet deres er vanligvis å få en pålitelig slutning så raskt som mulig. Stats Engine oppfyller disse målene med en implementering av sekvensiell testing som beregner et gjennomsnittlig sannsynlighetsforhold - den relative sannsynligheten for at variasjonen er forskjellig fra grunnlinjen - hver gang en ny besøkende utløser en hendelse. P-verdien til en test representerer nå sjansen for at testen noen gang vil nå den signifikansgrensen du velger. Det er en analog til en tradisjonell p-verdi for en verden der utvalgsstørrelsen er dynamisk. Dette kalles en test med styrke én, og den passer bedre enn en tradisjonell t-test for A/B-testeres mål.
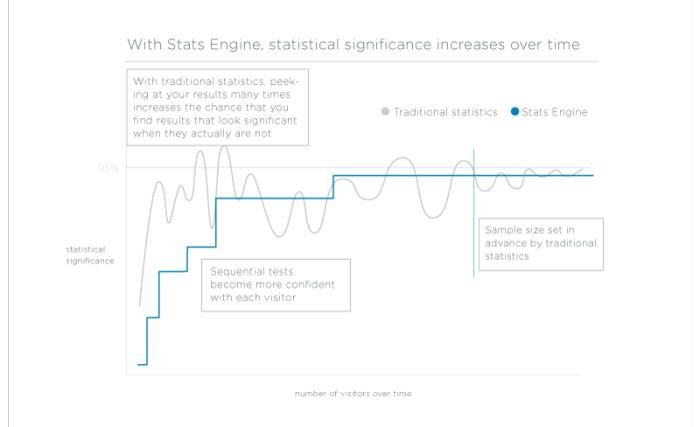
Det betyr at du får pålitelige, gyldige konklusjoner så snart de er tilgjengelige, uten å måtte fastsette en minste påvisbar effekt på forhånd eller vente på å nå en fast utvalgsstørrelse.
Kontroll av falsk oppdagelsesrate: Test mange mål og variasjoner med garantert nøyaktighet.
Rapportering av en falsk oppdagelsesrate på 10 % betyr at "høyst 10 % av vinnerne og taperne ikke har noen forskjell mellom variasjonen og baseline", noe som er nøyaktig sjansen for å ta en feil forretningsbeslutning.
Med Stats Engine rapporterer Optimizely nå vinnere og tapere med lav falsk oppdagelsesrate i stedet for lav falsk positiv rate. Etter hvert som du legger til mål og variasjoner i eksperimentet, vil Optimizely korrigere mer for falske oppdagelser og bli mer konservativ når det gjelder å utpeke en vinner eller taper. Selv om det totalt sett rapporteres færre vinnere og tapere (vi fant omtrent 20 % færre i vår historiske database*), kan en eksperimentator implementere dem med full kjennskap til risikoen som er involvert.
Når den kombineres med sekvensiell testing, gir kontroll av falsk oppdagelsesrate en nøyaktig oversikt over sjansen for feil når som helst når du ser på resultatene av testen. Kontrollen gir deg en transparent vurdering av risikoen for å ta en feil beslutning.
Dette betyr at du kan teste så mange mål og variasjoner du vil med garantert nøyaktighet.
* På et stort, representativt utvalg av historiske A/B-tester fra Optimizely-kunder fant vi ut at det var omtrent 20 % færre variasjoner med falsk oppdagelsesrate under 0,1 sammenlignet med falsk positiv rate på samme nivå.
Hvordan det er bedre
Optimizelys statistikkmotor reduserer antall feil uten at det går på bekostning av hastigheten.
Vi kjørte 48 000* historiske eksperimenter på nytt med Stats Engine, og resultatene er tydelige: Stats Engine gir mer nøyaktige og handlingsrettede resultater uten at det går på bekostning av hastigheten.
Ha større tillit til vinnere og tapere.
Fixed Horizon-statistikk erklærte en vinner eller taper i 36 % av testene (når testen ble stoppet.) I det samme datasettet erklærte Stats Engine vinnere eller tapere i 22 % av testene.
Stats Engine avdekket 39 % færre avgjørende testresultater enn tradisjonell statistikk. Selv om dette tallet kan virke alarmerende (og til å begynne med var det alarmerende for oss også!), fant vi ut at mange av disse avbrutte eksperimentene sannsynligvis ble stoppet for tidlig.
For å komme frem til dette resultatet brukte vi en metode som ligner på den kundene bruker når de manipulerer utvalgsstørrelseskalkulatoren for å avgjøre om en test har power (sannsynligheten for at du vil oppdage en effekt hvis den faktisk eksisterer) etter at den har startet - en post-hoc power-beregning. Å kjøre tester med for lav styrke tyder på at det ikke er nok informasjon i dataene til å skille skarpt mellom falske positive og sanne positive. Hvis vi bruker 80 % som standard for styrke, var de fleste (80 %) av eksperimentene som Stats Engine ikke lenger kalte avgjørende, understyrte, mens de fleste (77 %) av eksperimentene som Stats Engine beholdt, var styrkede.
Stabile anbefalinger du kan stole på.
Fixed Horizon-statistikken endret sin erklæring om vinner eller taper i 44 % av våre historiske eksperimenter. Stats Engine endret erklæringer i 6 % av disse testene.
Med Fixed Horizon-statistikk kunne du se en vinner den ene dagen, og et uklart resultat den neste. Den eneste gyldige erklæringen var den som var gyldig ved den forhåndsbestemte utvalgsstørrelsen. Med Stats Engine er resultatene alltid gyldige, og det er usannsynlig at de vil endre et konklusivt resultat.
Med Stats Engine falt andelen falske positive resultater fra >20 % til <5 %.
Husk simuleringene våre av A/A-tester (hver test ble kjørt på 5000 besøkende) da vi diskuterte farene ved å kikke. I disse simuleringene kjørte vi tester med 95 % signifikans og fant:
- Hvis du så på resultatene etter hver nye besøkende i eksperimentet, var det 57 % sjanse for å kåre en vinner eller en taper.
- Hvis du ser på resultatene for hver 500. besøkende, er det 26 % sjanse for en falsk erklæring.
- Hvis du sjekker hver 1000. besøkende, er det 20 % sjanse for en falsk erklæring.
- Med sekvensiell test (hvor man ser etter hver besøkende), synker det samme feiltallet til 3 %.
Hvis vi kjører disse simuleringene på større utvalgsstørrelser (for eksempel 10 000 eller til og med 1 000 000 besøkende), øker sjansen for en falsk erklæring med tradisjonell statistikk (lett over 70 % avhengig av utvalgsstørrelsen), uansett hvor ofte du ser på resultatene dine. Med sekvensiell test øker også denne feilraten, men den er begrenset til 5 %.
Det er ingen hake: Nøyaktige og handlingsrettede resultater trenger ikke å gå på bekostning av hastighet.
Når du har lest så langt, spør du kanskje: Hva er haken? Det er det ikke.
Her er grunnen til det: Å velge riktig utvalgsstørrelse betyr å velge en minste detekterbar effekt på forhånd. Som vi har vært inne på tidligere, er det en vanskelig oppgave. Hvis du for hvert eksperiment (før du kjører det) setter MDE innenfor 5 % av det faktiske løftet i eksperimentet, vil den sekvensielle testen i gjennomsnitt være 60 % langsommere.
I virkeligheten velger imidlertid utøverne en MDE som er utformet slik at den er lavere enn de observerte løftene. Det gjenspeiler hvor lenge de er villige til å kjøre et eksperiment. Med Stats Engine vil du kunne gjennomføre testen raskere når det sanne løftet er større enn MDE-en din.
Vi fant ut at hvis løftet i A/B-testen din ender opp 5 prosentpoeng (relativt) høyere enn MDE-en din, vil Stats Engine kjøre like raskt som Fixed Horizon-statistikken. Så snart forbedringen overstiger MDE med så mye som 7,5 prosentpoeng, er Stats Engine nærmere 75 % raskere. For større eksperimenter (>50 000 besøkende) er gevinsten enda høyere, og Stats Engine kan utpeke en vinner eller taper opptil 2,5 ganger så raskt.
Evnen til å få tester til å kjøre på rimelig tid er en av de vanskeligste oppgavene ved å bruke sekvensiell testing til A/B-testing og optimalisering. Vår store database med historiske eksperimenter gjør det mulig for oss å justere Stats Engine ut fra tidligere informasjon. Ved å utnytte vår omfattende eksperimentdatabase kan Optimizely levere de teoretiske fordelene med sekvensiell testing og FDR-kontroll uten å påføre praktiske kostnader.
*En merknad om dataene: Datasettet vi testet hadde eksperimenter med en median på 10 000 besøkende. Tester med et lavere antall besøkende hadde et lavere antall erklæringer i både Fixed Horizon Testing og Stats Engine, et tilsvarende antall endrede erklæringer, men vi er raskere til å vise hastighetsgevinster for sekvensiell testing.
Hva dette betyr for alle tester som er kjørt frem til i dag
La oss avklare én ting: Tradisjonell statistikk kontrollerer feil i forventet grad når den brukes riktig. Det betyr at hvis du har brukt en kalkulator for utvalgsstørrelse og holder deg til anbefalingene, trenger du sannsynligvis ikke å bekymre deg for tester du har kjørt tidligere. På samme måte, hvis du pleier å ta forretningsbeslutninger kun basert på primære konverteringsmålinger, reduseres forskjellen mellom falsk oppdagelse og falsk positiv rate. For Optimizely-brukere som allerede tok disse forholdsreglene, vil Stats Engine gi en mer intuitiv arbeidsflyt og redusere innsatsen med å kjøre tester.
Vi vet også at det er mange der ute som sannsynligvis ikke gjorde nøyaktig det som kalkulatoren for utvalgsstørrelse fortalte deg at du skulle gjøre. Men digitale eksperimentatorer er en kunnskapsrik og skeptisk gjeng. Du har kanskje ventet et bestemt antall dager før du ringte resultatene, ventet lenger hvis det så mistenkelig ut, eller kjørt beregningen av utvalgsstørrelsen på nytt hver gang du kikket for å se hvor mye lenger du skulle vente. Alle disse fremgangsmåtene bidrar til å redusere risikoen for å gjøre feil. Selv om feilprosenten din sannsynligvis er høyere enn 5 %, er den sannsynligvis heller ikke over 30 %. Hvis du tilhører denne gruppen, frigjør Stats Engine deg fra disse fremgangsmåtene og gir deg i stedet nøyaktige forventninger om feilraten du kan forvente.
Et lite skritt for Optimizely, et stort sprang for nettoptimalisering
Optimizelys misjon er å gjøre det mulig for verden å omsette data til handling. For fem år siden tok vi vårt første skritt mot dette målet ved å gjøre A/B-testing tilgjengelig for ikke-ingeniører med vår Visual Editor. Nå har titusenvis av organisasjoner omfavnet en filosofi om å integrere data i alle beslutninger.
I dag, med Stats Engine, ønsker vi å ta bransjen ett skritt videre ved å fjerne enda en barriere for å bli en datadrevet organisasjon. Ved å gjøre det mulig for hvem som helst å analysere resultater med kraftfull statistikk, har vi som mål å gjøre det mulig for virksomheter å støtte enda flere viktige beslutninger med data.
Riktig statistikk er avgjørende for å kunne ta datadrevne beslutninger, og vi er opptatt av å utvikle statistikken vår for å støtte kundene våre. Vi gleder oss til å samarbeide med deg om å skrive det neste kapittelet om optimalisering på nettet.
Vi ser frem til dine tilbakemeldinger og tanker om statistikk. La oss få vite hva du mener i kommentarfeltet!
Vil du lære mer? Vi har laget en rekke tilleggsressurser for å hjelpe deg med å komme i gang med statistikk med Optimizely:

Leo har en doktorgrad i statistikk fra Stanford, og er Optimizelys første interne statistiker. Han brenner for å gjøre det mulig for alle å høste fordelene av eksperimentering...
- Sist oppdatert:25.04.2025 21:15:06