CUPED: Reducing variance in A/B testing isn't new but most are getting it wrong

TIME...
is the culprit of why well-designed experiments sometimes do not reach statistical significance.
Many A/B tests end up in the "inconclusive" graveyard, hovering just below the significance threshold. Between slow data collection and high-variance metrics, detecting real effects in your website redesign or pricing strategy can be frustratingly elusive.
What if you could tighten your confidence intervals and increase the statistical power of your experiments using data you already have?
That's where CUPED comes in. It stands for Controlled-experiment Using Pre-Existing Data, a statistical approach to reduce variance.
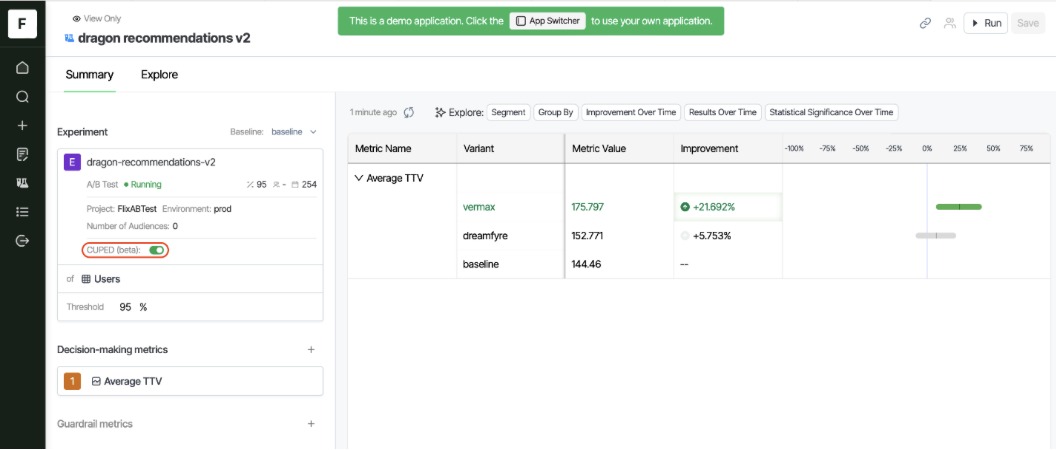
Image source: Optimizely
And the best part? You can use it too! Let's see how. 👇
The experimentation efficiency gap
The challenge of experimentation timing varies by industry:
- E-commerce sites typically run tests for several weeks
- SaaS products often require longer test periods
- Media sites may see faster results due to higher traffic volumes
And that's if they conclude at all. Many simply get abandoned when results stay inconclusive.
Why does this happen? Three main reasons:
- High variance in metrics data: Engagement metrics naturally fluctuate a lot between users, making it hard to spot true effects.
- Limited traffic: Not every company is Google. Most businesses struggle to get enough users through an experiment.
- Opportunity cost: Every week an experiment runs is another week you're delaying decisions and potential improvements. Longer experiments mean fewer tests you can run in a given timeframe, slowing down your overall learning velocity and product evolution.
High variance in a metric requires a larger sample size to reach statistical significance, which can take weeks consideringthe visitor traffic. When metrics fluctuate widely between users, you need more data to distinguish true difference from a pure chance.
CUPED makes a critical difference by reducing this variance using pre-experiment data. This allows you to reach statistical significance with smaller sample sizes, extracting clearer signals from the data you already have instead of simply collecting more.
This transforms a painfully slow learning cycle into a more efficient experimentation program. This is the experimentation efficiency gap that CUPED helps bridge.
Let's dive deeper into where CUPED came from and how it works.
How CUPED turns your existing data into faster wins
Microsoft Research published a paper in 2013 that introduced CUPED: Controlled-experiment Using Pre-Existing Data.
A statistical method that makes your A/B tests more efficient by using data you already have.
Early adopters at Microsoft reported significant improvements in their testing capabilities. Companies like Netflix and Airbnb have since implemented similar approaches with impressive results.
What makes CUPED different is its elegant simplicity. It uses pre-experiment data as a covariate to reduce variance in your metrics.
If you want to measure how a new feature affects user spending, wouldn't it be helpful to account for how much those users were spending before your experiment?
That's exactly how CUPED filters out the noise so you can see the signal more clearly.
To truly appreciate CUPED's value, we need to understand its nemesis aka variance.
Variance is why two seemingly identical users can have wildly different behaviors:
- One spends $10 on your site
- Another spends $150
- And you're trying to detect a 5% improvement in average order value
See the problem?
With naturally high variance metrics like revenue or engagement, small treatment effects get buried under mountains of statistical noise. It's like trying to hear a whisper at a rock concert.
CUPED works by incorporating pre-experiment data as a covariate in your analysis.
This tightening of confidence intervals is what makes CUPED so effective. Same data and the same effect size, but suddenly you can see it.
Now that we understand how CUPED works, let's look at where it delivers the most impact.
Not all metrics benefit equally from CUPED...
Here's what you need to know:
1. Special considerations: Revenue metrics
Revenue metrics often have extremely high variance. Some users might spend $5 while others spend $500.
When applied to revenue metrics, CUPED looks for a correlation between past spending and current spending. Thus, CUPED will not be effective for new users, where we don't have past spending data.
A common implementation mistake is using covariates that are influenced by the treatment, which can lead to biased results. A best practice is to choose covariates that are measured before the experiment starts.
2. When to use CUPED
✅ Best for: High-variance numeric metrics
- Revenue per visitor
- Average order value
- Session duration
These metrics see the biggest improvement with CUPED because they typically have:
- High natural variance between users
- Strong correlation between pre-experiment and during-experiment values
🚫 Less effective for: Binary conversion metrics
- Conversion rate (yes/no)
- Clickthrough rate (click/no click)
How to flip the CUPED switch in Optimizely
Optimizely makes using CUPED straightforward:
- Compatible metrics: Works with numeric metrics (revenue, engagement counts) but not binary conversion metrics
- Pre-experiment data: Uses pre-experiment values of your target metrics as covariates
- Supported in Optimizely Analytics: Functions on Snowflake, BigQuery, and Databricks
- Implementation: Simple toggle in experiment settings, no complex calculations needed
- Data requirements: Needs historical data for analyzed metrics; no effect on new metrics without history
- Expected outcome: Reduces variance, potentially cutting sample size requirements for metrics correlated to historical behavior
Here's how it looks with and without CUPED.
Without CUPED
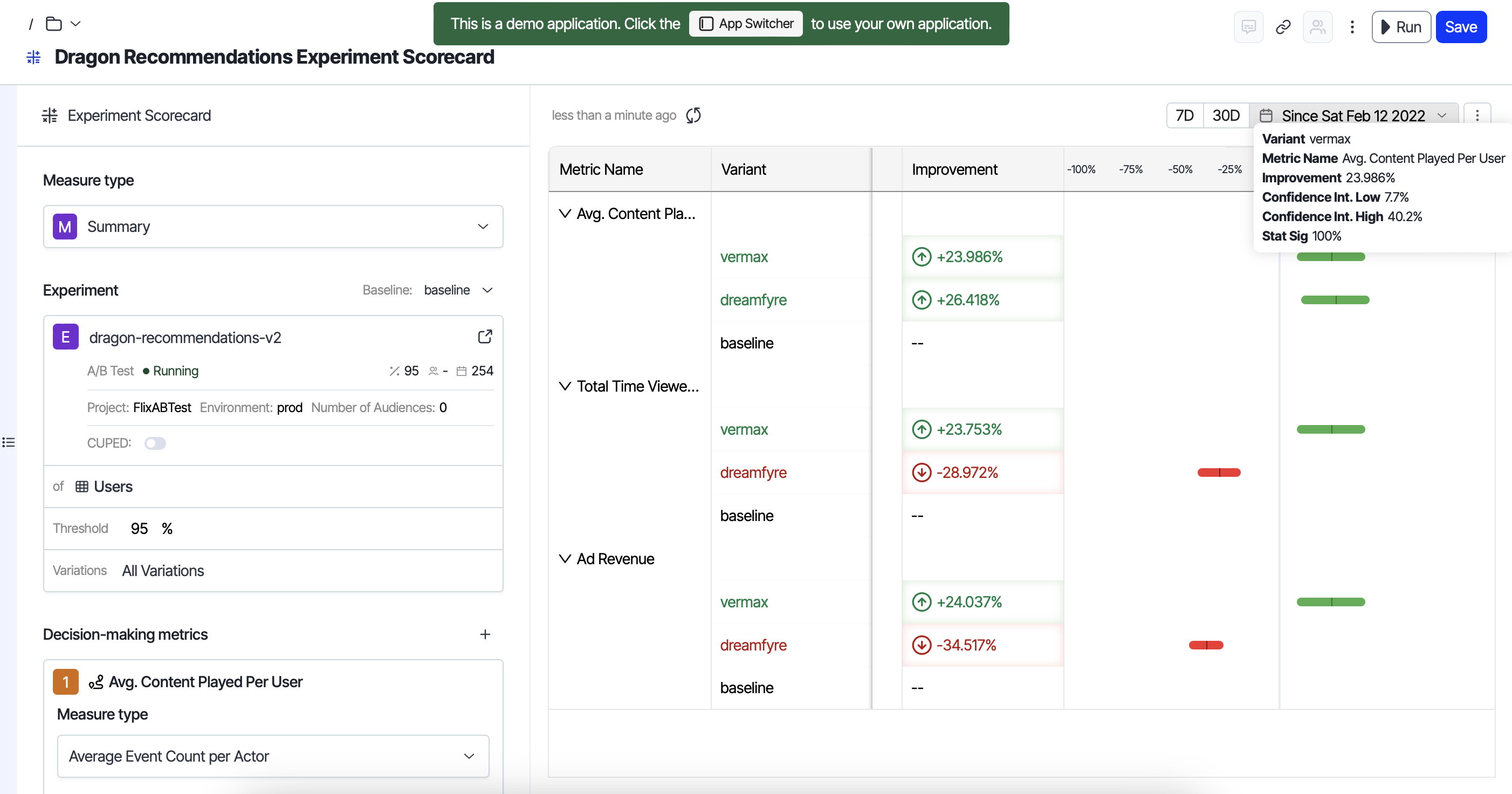
Image source: Optimizely
Now, with CUPED, there's a difference in the length of the confidence interval.
Image source: Optimizely
Three takeaways...
The future of experimentation isn't just about running more tests, it's about running smarter tests. CUPED is your first step in that direction.
- Increased efficiency: You have a higher chance of seeing significant results with the same sample size.
- Not all metrics benefit equally: Focus CUPED implementation on high-variance numeric metrics where you'll see the biggest gains.
- Implementation complexity varies: There are different ways of implementing CUPED and different covariates that can be chosen. Optimizely's implementation uses historical metric data which fits the majority of our customer's use cases.
Ready to run smarter tests?
Start by identifying one high-variance metric in your experimentation program. Run a side-by-side comparison between your traditional analysis and a CUPED-enhanced test.
You'll likely see tighter confidence intervals, clearer results, and potentially reach statistical significance for a test that would have been inconclusive otherwise.
The path to more efficient experimentation begins with this simple step. Your future self will wonder how you ever tested without it.

- Last modified:2025-04-26 00:17:51