Hur man fattar statistiskt korrekta beslut med hjälp av konfidensintervall

Som experimentator kan pressen att fatta ett beslut efter att du har kört en A/B-testning leda till några ganska knäppa tolkningar av icke-signifikanta experimentresultat. När allt kommer omkring, vad betyder det ens för något att vara "trender i riktning mot statistisk signifikans" (en fras som faktiskt uttalades med säkerhet under en nyligen genomförd experimentgranskning på Optimizely)?
I det här inlägget kommer jag att prata om hur du kan använda konfidensintervall för att minska risken för beslut som baseras på icke-signifikanta resultat från A/B-testning utan att kompromissa med din intellektuella integritet.
Rimligt klingande men felaktiga uttalanden som hörs på Optimizely's Experiment Review
Mitt favoritmöte på Optimizely är vår veckovisa Experiment Review. Det är en plats där människor samlas för att finslipa idéer om produktexperiment och dela resultaten från tidigare experiment. Det är ett bra ställe att ge och ta emot feedback, och jag ser fram emot det varje vecka.
Men jag, liksom många experimentörer, har varit i den föga avundsvärda positionen att presentera ett experiment där ingen av mätvärdena nådde statistisk signifikans. I det ögonblicket kan trycket att få ut något av värde från experimentet vara extremt högt. För att komma till den här punkten var din idé tvungen att slå ut otaliga andra fantastiska idéer för att hamna högst upp i backloggen. En ingenjör tillbringade värdefulla cykler med att koda upp den. Den kördes i flera veckor. Och nu förväntar sig teamet att du ska fatta ett datadrivet beslut om produktens riktning. 😬
Det fruktade "havet av grått" slår till igen!
Att se den mentala gymnastik som experimentörer går igenom i den här situationen är en av de verkliga glädjeämnena med Experiment Review. Här är några av de rimliga klingande men i slutändan felaktiga tolkningarna av icke-statiskt signifikanta resultat jag har hört:
- "Riktningsmässigt presterar variation A bättre än kontrollen"
- "Variation A tenderar i riktning mot en vinst"
- "Variation A har den högsta signifikansen av alla variationer, så det är ett gott tecken"
- "Om du höll en pistol mot mitt huvud, skulle jag nog välja variant A."
Vi vet alla att det intellektuellt hederliga vore att fokusera vår energi på att utforma nästa iteration av testet, vilket skulle vara mer sannolikt att nå signifikans. När man arbetar med p-värden bör statistiken vara svartvit: antingen visar resultaten en statistiskt signifikant effekt eller så gör de inte det. Eller för att ge det en mer poetisk formulering:

När jag kommer på mig själv med att prata om "riktningsresultat" tröstar jag mig med att jag inte är ensam. Faktum är att Probable Error (Matthew Hankins humoristiska statistikblogg) sammanställde en lista över kreativa språk för "icke-signifikanta resultat" som finns i peer-reviewed akademiska tidskrifter. Några av mina favoriter inkluderar:
- "En icke-signifikant trend mot signifikans"
- "Tittar på randen till signifikans"
- "Inte signifikant i ordets snäva bemärkelse"
- "Närmar sig men misslyckas med att uppnå en sedvanlig nivå av statistisk signifikans" 🤔
Så om även akademiker i karriären är benägna att använda den här typen av bristfällig logik, vad ska vi vanliga dödliga inom experimentering göra när vi ställs inför icke-signifikanta resultat?
Ange konfidensintervallet
Konfidensintervall uttrycker ett intervall av möjliga förbättringsvärden för dina mätvärden. För mätvärden som inte har uppnått signifikans kommer detta intervall att vara ganska stort och inkludera 0 (dvs. det finns en chans att nollhypotesen är sann). Den goda nyheten är att detta intervall av värden ger dig en uppfattning om de övre och nedre gränserna för den verkliga förbättring som du skulle se om ditt test var mer kraftfullt. På resultatsidan för Optimizely One kommer den "sanna" förbättringen för ett mått med en signifikanströskel på 90 % att ha 90 % chans att finnas inom konfidensintervallet.
Detta gör att du kan säga saker som "Variation A:s konverteringsgrad är sannolikt inte X% sämre än baslinjens konverteringsgrad." Det kan räcka för att fatta ett beslut om ditt mål helt enkelt är att inte försämra prestandan genom att göra en förändring, och det låter mycket bättre än att kalla det "en riktningsvinnare".
Jag har själv stött på den här situationen. Ta till exempel ett test som jag körde på sidan Optimizely Experiment Overview. Hypotesen: Genom att visa besöksantal för varje experiment på den här sidan blir det lättare för användarna att hitta relevanta data utan att behöva klicka sig in på resultatsidan för varje test:
Idén är enkel, valideras av kundfeedback och är intuitivt vettig. Problemet är: hur fattar man ett datadrivet beslut om att lansera det? Vissa i teamet trodde att användare som utsattes för behandlingen skulle visa färre resultatsidor, medan andra trodde att det skulle kunna öka antalet visningar av resultatsidor (eftersom användare som annars inte skulle visa resultat blev nyfikna). Och om vissa användare ökade konsumtionen av resultatsidan medan andra minskade sin konsumtion, hur skulle vi då kunna avgöra från våra testresultat vilka som kunde vara platta?
I slutändan bestämde vi oss för att den enda anledningen till att vi inte skulle vilja göra den här ändringen var om vi såg en stor minskning av konsumtionen av resultatsidan över hela linjen.
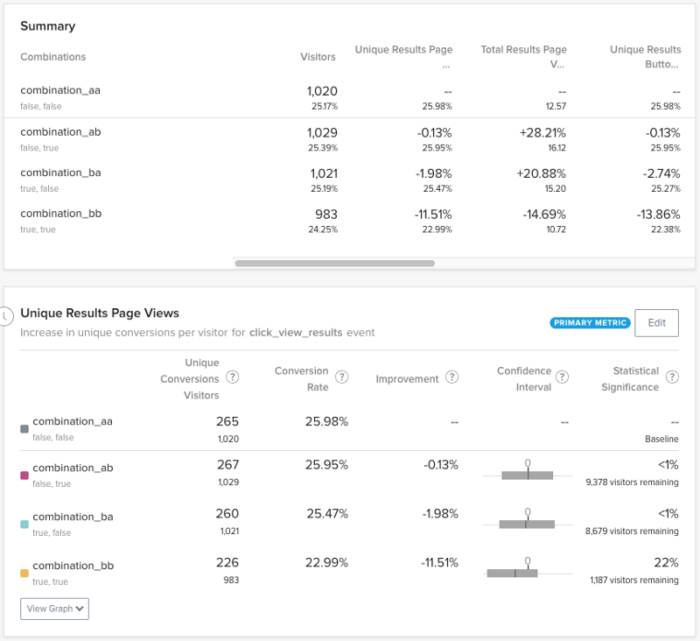
Efter att ha kört experimentet i över en månad var det dags att analysera resultaten. Som vi hade befarat hade vårt primära mätvärde inte uppnått signifikans, och vi behövde fatta ett beslut om vad vi skulle göra härnäst. Genom att undersöka konfidensintervallet för variationen "Experiment Visitors" kunde vi fastställa en "nedre gräns" för förbättring:

Även om konfidensintervallet är ganska brett hjälpte det oss att förstå vilken risknivå vi tog när vi genomförde den här förändringen. Med andra ord var det värsta tänkbara scenariot att den här förändringen skulle minska konverteringen till resultatsidan med ~22%. Med tanke på att det faktum att det blir lättare att hitta relevanta resultat från experimentet rimligen kan minska antalet irrelevanta resultatsidor som visas, verkade detta vara en acceptabel avvägning.
Möjlighet att fatta ett statistiskt korrekt beslut med icke-signifikanta mätvärden? Check! Tack konfidensintervall!

Evan är Product Manager för Analytics på Optimizely. Han brinner för att göra det möjligt för våra kunder att lära sig av och agera på sina data.
- Last modified:2025-04-26 00:14:56