Produktanalys + datalager: en perfekt matchning

Första generationens produktanalysverktyg som Mixpanel och Amplitude innehåller en anpassad dataplattform under huven för lagring och analys av produktinstrumentdata. Dessa plattformar påstår sig vara speciellt optimerade för användningsmönster för produktanalys, men de begränsar allvarligt användarens förmåga att göra ad hoc-utforskning på grund av stel modellering, begränsade frågefunktioner och saknat sammanhang.
Som någon som har byggt flera databaser och analysmotorer som betjänar miljontals användare (se Ytterligare resurser i slutet av den här bloggen för några av mina samtal), tror jag bestämt att:
Det moderna molndatalagret kan betjäna produktanalysarbetsbelastningar lika effektivt som alla andra system, utan att skapa datasilor eller offra SQL-generaliteten.
I det här inlägget kommer jag att lista de kritiska tekniska kraven för en produktanalysapplikation och beskriva varför datalager är perfekt utrustade för att ta itu med dessa utmaningar.
Produktanalys - En extremt kortfattad teknisk översikt
Innan jag presenterar mina argument, låt oss gå igenom en kort uppdatering av produktanalys.
Produktanalys är analys av produktanvändnings- och prestandadata. Produktanvändningsdata inkluderar användaråtgärder som klick, tangenttryckningar och applikationshändelser som sidladdningar, API-fel, långsamma förfrågningar etc. Dessa data kallas även för händelsedata. Händelsedata samlas oftast in i halvstrukturerat format och skickas till analysplattformen för vidare bearbetning och analys.
{ "event_name": "checkout", "event_time": 1662313719000, // Millis sedan epok för Sep 04, 2022 "user_id": "some_user" "property0": "value®" "property1": "valuel" ... och så vidare ... }Det finns tre grundläggande egenskaper som finns i någon form i alla händelser:
- event_name - Namn på händelsen eller användaråtgärden
- event_time - Tidpunkt då händelsen inträffade
- user_id - Id för den användare som initierade händelsen
Händelsetid sammanställer alla händelser från en användare för att ge en global ordning över alla källor för den användaren. Verktyg för produktanalys aggregerar och visualiserar denna ström av användaråtgärder ordnade efter event_time för att förstå beteende, engagemang, attribution, drivkrafter etc.
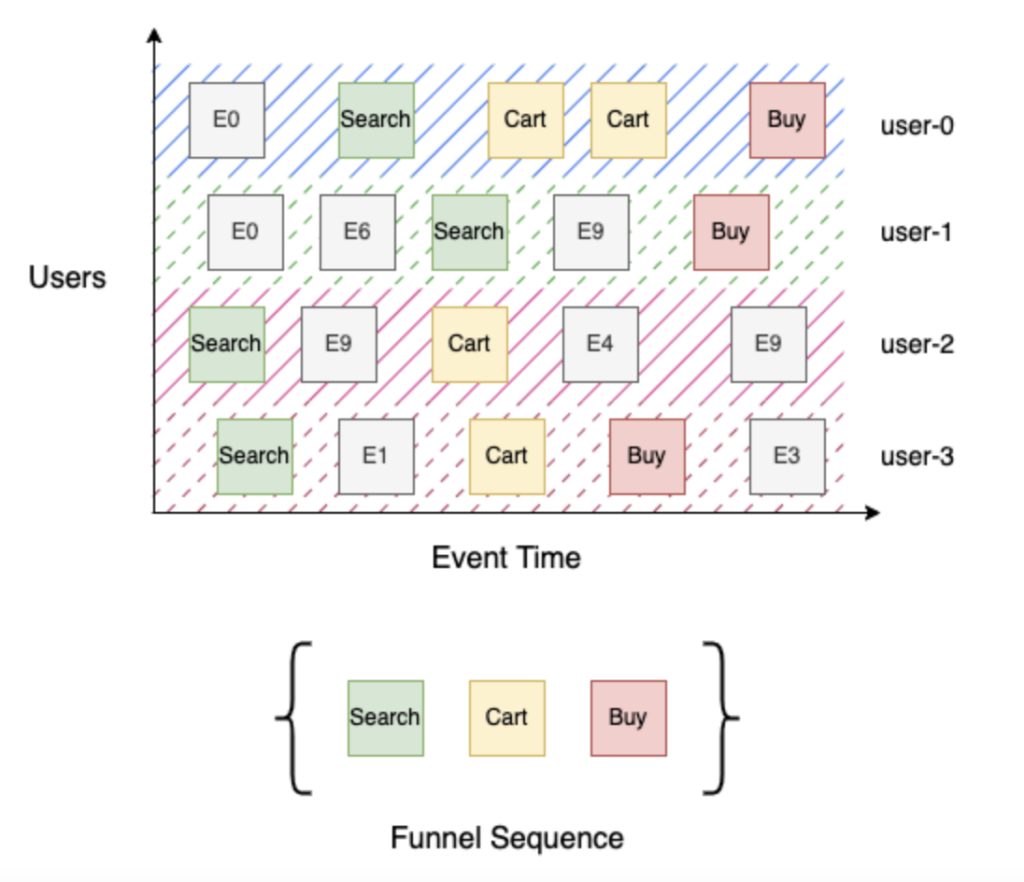
Låt oss titta på en enkel köptratt i tre steg med stegen Sök, Kundvagn och Köp. Search (steg 1) identifierar alla användare som sökt efter produkten, Cart (steg 2) identifierar alla användare som sökt efter en produkt och lagt den i varukorgen, och slutligen Buy (steg 3) identifierar alla användare som sökt efter en produkt, lagt den i varukorgen och checkat ut. Att bygga den här tratten är enkelt med tanke på ett sorterat flöde av användarhändelser efter händelsetid - för varje användare itererar du genom händelsesekvensen för att spåra deras framsteg genom tratten och aggregerar sedan distinkta användare efter steg. I exemplet ovan nådde "user-0" och "user-3" fram till Buy (steg 3), och "user-1" nådde Search (steg 1) eftersom det inte finns någon Cart-händelse i deras händelseström, och "user-2" nådde Cart (steg 2).
Vad är det som gör produktanalys svårt?
Extrem skala upp
Data om produktanvändning kan vara extremt omfattande. De genereras vid varje användarinteraktion med produkten och är vanligtvis denormaliserade och extremt rika på kontextuella attribut. Dessutom växer dessa data över tid med ökande produktanvändning. Tänk dig bara antalet dagliga interaktioner (klick, tryckningar, tangenttryckningar etc.) du har med din favoritprodukt och multiplicera det sedan med antalet användare som använder den! Dessa storskaliga data måste lagras och hämtas på ett effektivt sätt för att kunna analyseras inom loppet av en sekund.
Förfrågningar om händelsesekvenser
Produktanalysberäkningar är i allmänhet betydligt mer komplexa än traditionella "slice and dice"-frågor som är typiska för business intelligence-verktyg som Tableau och Looker. Som förklaras i inledningen ovan kräver beräkningar att man följer en sekvens av händelser för att förstå användarnas beteende. Systemet måste vara effektivt i den här kombinationen av hög komplexitet och skala upp. Interaktiv prestanda är avgörande för alla självbetjäningslösningar för produktanalys, så att slutanvändaren kan utforska data och snabbt komma fram till värdefulla insikter.
Inläsning i realtid
Produktteam behöver snabb insyn i produktanvändningsdata för att kunna göra snabba iterationer av produktfunktioner, särskilt i samband med lanseringar eller för att stödja experiment. Produktanvändningsdata genereras kontinuerligt och förväntas vara tillgängliga för analys inom några minuter. Ofta kan huvuddelen av data produceras i korta intervall som är anpassade till externa händelser eller tid på dygnet. Systemet måste snabbt kunna ta in dessa tidsstämplade händelsedata och organisera och indexera dem på ett beständigt lagringsmedium för att möjliggöra effektiva realtidsfrågor.
Kontinuerligt utvecklande schema
Produktanvändningsdata kan förses med kontextspecifika attribut för att underlätta analys. Dessa annoteringar behöver inte deklareras i förväg utan läggs till vid behov i takt med att kraven förändras. Användarna kan till exempel bestämma sig för att kommentera köphändelsen i exemplet med tratten med totalpriset och bara inkludera händelser som har ett totalpris på mer än 5 USD. Enkelt uttryckt har händelsedata ingen fördefinierad struktur eller schema och utvecklas kontinuerligt med förändrade produktkrav.
Datalagret till undsättning
Att utveckla en plattform för produktanalys är utan tvekan ett svårt systemproblem. Lyckligtvis har databasforskarna arbetat aktivt med de problemområden som anges ovan i årtionden.
Moderna datalager använder olika banbrytande tekniker för att leverera kostnadseffektiv prestanda i skala upp för produktanalys.
I det här avsnittet kommer jag att lista några viktiga designdetaljer för datalager som tar itu med ovanstående utmaningar.
Kolumnär lagring: Till skillnad från lagringsformat med radmajoritet minimerar kolumnlagring antalet bytes som berörs av en fråga genom att endast komma åt data för nödvändiga kolumner. Analytiska databaser har experimenterat med kolumnlagring så tidigt som på 1970-talet. I artikeln "C-Store" (Stonebreaker et al., 2005) visades betydande prestandaförbättringar för analytiska arbetsbelastningar. Alla analytiska system använder idag kolumnlagring för att förbättra prestandan.
Effektiv komprimering för tidsseriedata: En mängd olika tekniker har utvecklats över tiden för datakomprimering i databaser för att minska kostnaderna och förbättra prestandan. Förutom att implementera alla de välkända grundläggande algoritmerna som ordbokskodning, RLE- och LZW-varianter, Delta-kodning etc. investerar lager kontinuerligt i detta område för att skapa innovation - Google publicerade Capacitor-formatet som beskriver kolumnordning för bättre komprimeringsförhållande, Gorilla-papper av Pelkonen et al., 2015 från Facebook beskriver ett komprimeringsschema för tidsseriedata. De flesta av dessa tekniker används av alla större leverantörer av datalager idag.
Massivt parallell bearbetning: Distribuerade databaser distribuerar bearbetning över en bank av beräkningsnoder, där bearbetningen sker parallellt och utdata från varje nod slutligen monteras för att producera en slutlig resultatuppsättning. Goetz Graffe föreslog i sitt "Volcano"-dokument modeller för att parallellisera arbetet i SQL-exekveringsmotorer över trådar och noder. System som Teradata och Netezza var banbrytande när det gäller att parallellisera så mycket arbete som möjligt så tidigt som möjligt och populariserade termen MPP. Idag bearbetar mogna databaser terabyte med data på några sekunder med hjälp av denna arkitektur.
Klustrad datalayout: Klustrade index har använts i databaser under mycket lång tid för att snabba upp olika relationsoperationer som - sortera, aggregera, delta i osv. Detta är särskilt användbart för analys av händelsesekvenser för att påskynda frågor genom att hålla händelsedata försorterade i händelsetidsordning. De flesta större datalager, inklusive Snowflake (datakluster ), BigQuery (klustrade tabeller), Redshift (sorteringsnyckel) och SQL Server (klustrade och icke klustrade index), tillåter anpassad klustring för att justera prestanda.
Vektorisering eller JIT: Databasimplementeringar är kraftigt optimerade och strävar efter att uppnå prestanda som ligger nära anpassade handskrivna program för varje fråga. Det finns två allmänt kända tekniker som möjliggör sådan prestanda - vektorisering som banades väg av Vectorwise och JIT-kodgenerering som banades väg av HyPer. Båda idéerna är föremål för omfattande forskning, och de flesta moderna implementeringar använder idéer från båda paradigmen (se Ytterligare resurser nedan för mitt föredrag inom detta område).
Fönsterfunktion för händelsesekvenser: Window Functions (eller Analytic Functions) lades till i SQL 2003 och möjliggör de flesta frågemönster på tidsseriedata som kräver åtkomst till angränsande rader. Sedan dess har användningen av denna operator blivit genomgripande i alla datalager, vilket har resulterat i mycket forskning och optimering av dess implementering - t.ex. "Efficient Processing of Window Functions" av Leis et al., 2015 och"Incremental Computation of Common Windowed Holistic Aggregerates" av Wesley et al., 2016. Verktyg för produktanalys kan i stor utsträckning använda fönsterfunktioner för att ställa frågor om händelsesekvenser. Det här är ett område som är moget för innovation. Jag kommer att gå in på mer detaljer i senare inlägg.
Semistrukturerade typer: Annoterade med kontextspecifika attribut som inte behöver deklareras på förhand utan som läggs till vid behov i takt med att kraven förändras. Slutanvändaren kan till exempel bestämma sig för att kommentera Buy-händelsen i exemplet med tratten ovan med inköpspriset och endast inkludera händelser som har ett pris på mer än 5 USD. Händelsedata har inte en fördefinierad struktur eller ett schema. Den utvecklas kontinuerligt i takt med att kraven förändras. 2010 publicerade Google "Dremel"-dokumentet som beskrev ett lagringsformat för interaktiv ad hoc-lagring av nästlade semistrukturerade data. Detta dokument blev grunden för det välkända Apache Drill-projektet. Idag använder alla stora datalager i molnet idéer från den här artikeln för att stödja JSON och liknande nästlade typer som ständigt förändras med minimal prestandaförlust.
Bearbetning och inläsning i realtid: System som Druid och Pinot populariserade nyligen realtidsinmatning med hjälp av Lambda-arkitekturen. Kappa-arkitekturen som används av Flink och Spark, förenklade ytterligare streaminginmatning och har anammats av de flesta moderna datalager - BigQuery har ett streaming Storage Write API som kan mata in med hög genomströmning (~ 10 GB / sek) med en färskhetslatens på 2-3 minuter. På samma sätt implementerar Redshift med Amazon Kinesis Data Firehose för att ta in och göra dataflödet live på mindre än en minut. Snowpipe hanterar kontinuerlig datainmatning till Snowflake med datafriskhet på ett par minuter för scenarier med hög genomströmning.
Slutsatser
Datalager i molnet har inte bara kommit utan exploderat under det senaste decenniet. Det kan ha varit vettigt att skapa en anpassad plattform 2010 när Mixpanel och Amplitude grundades, men den arkitekturen är föråldrad idag.
Med Optimizely Warehouse-native Analytics tror vi att användning av ett datalager för att köra produktanalysfrågor inte bara är prestanda och kostnadseffektivt utan också låser upp nya typer av analyser som inte är möjliga i befintliga produktanalysverktyg som - berika användarhändelsedata med affärskontexten i salesforce, kombinera flera händelsekällor för att bättre förstå produktanvändning etc.
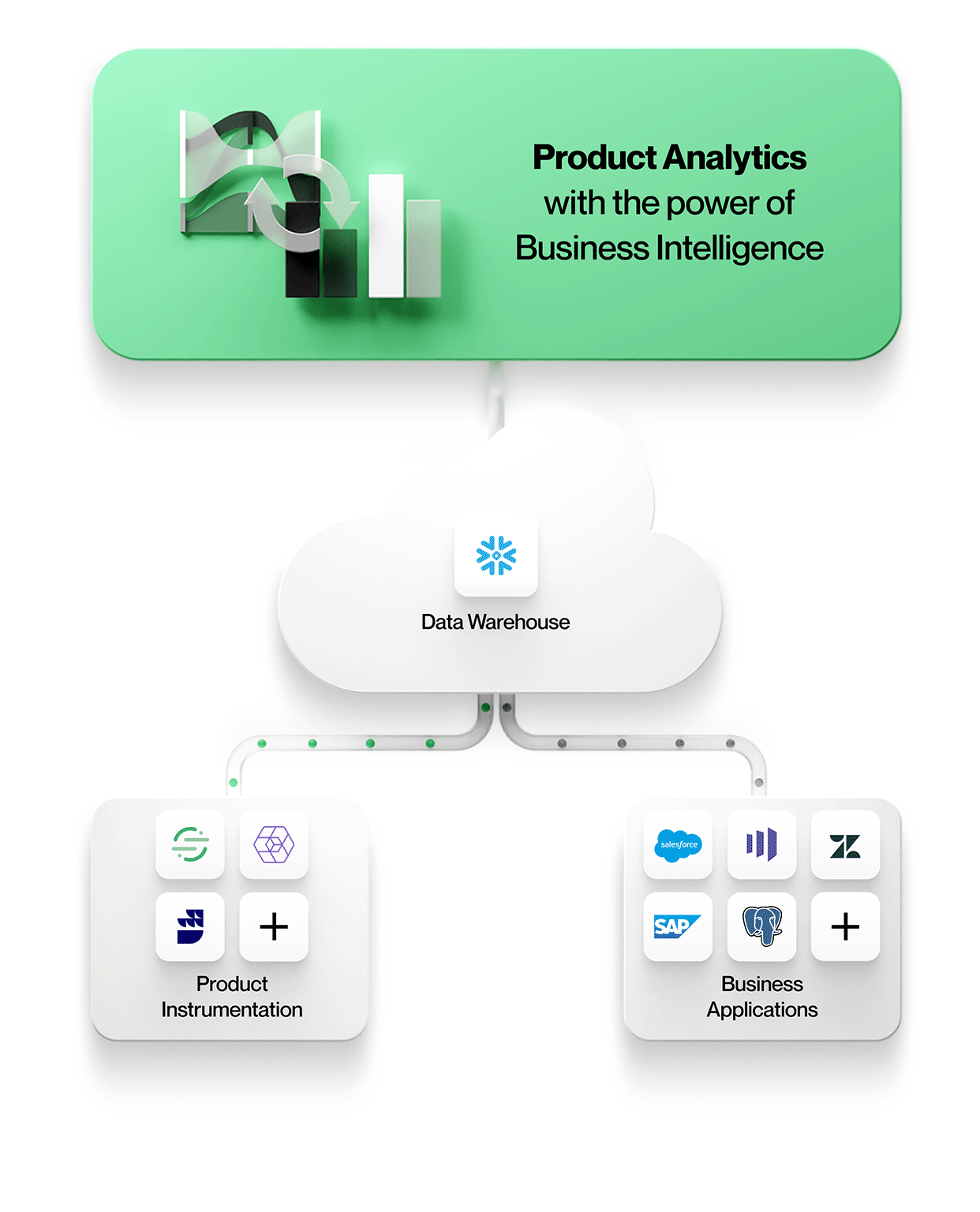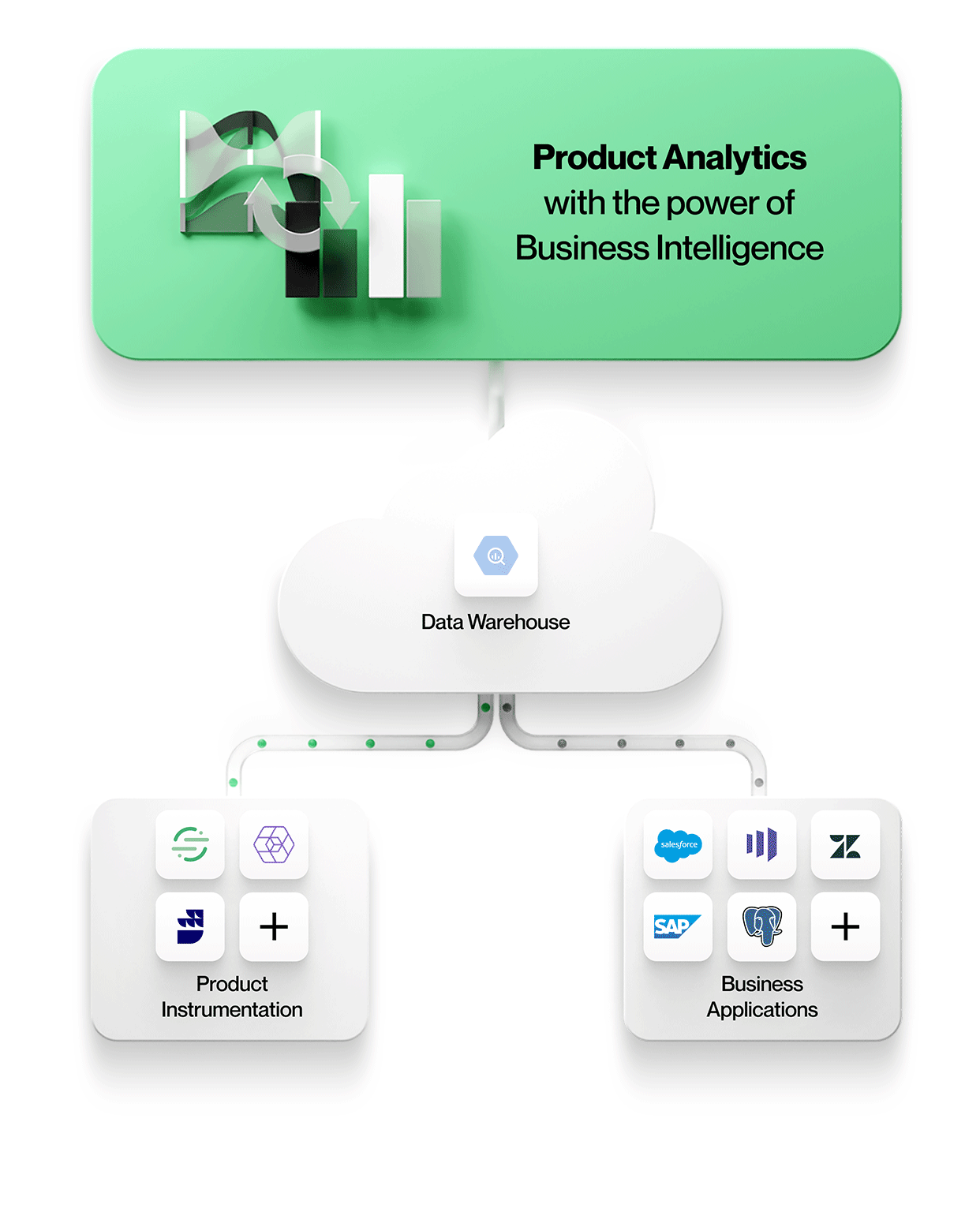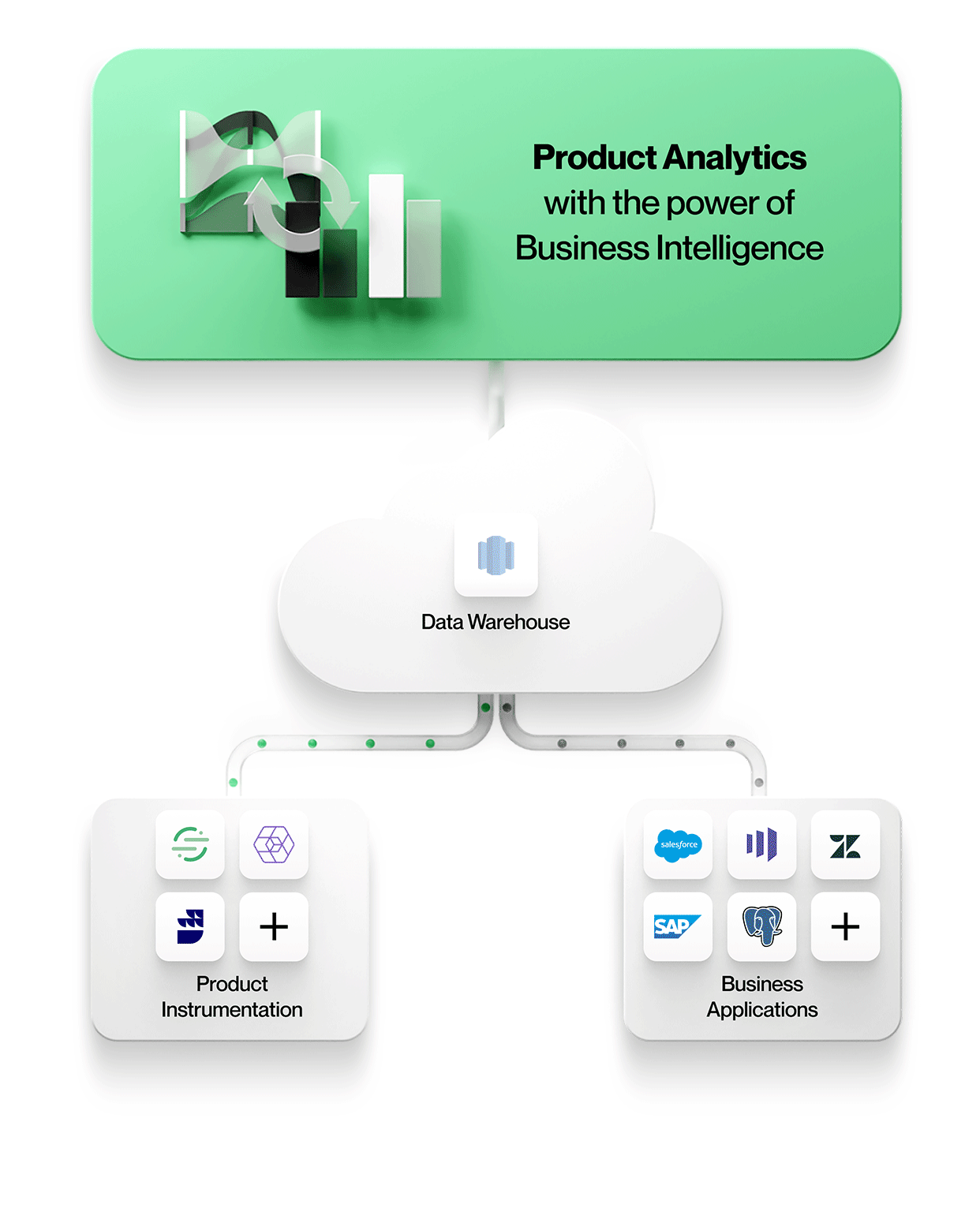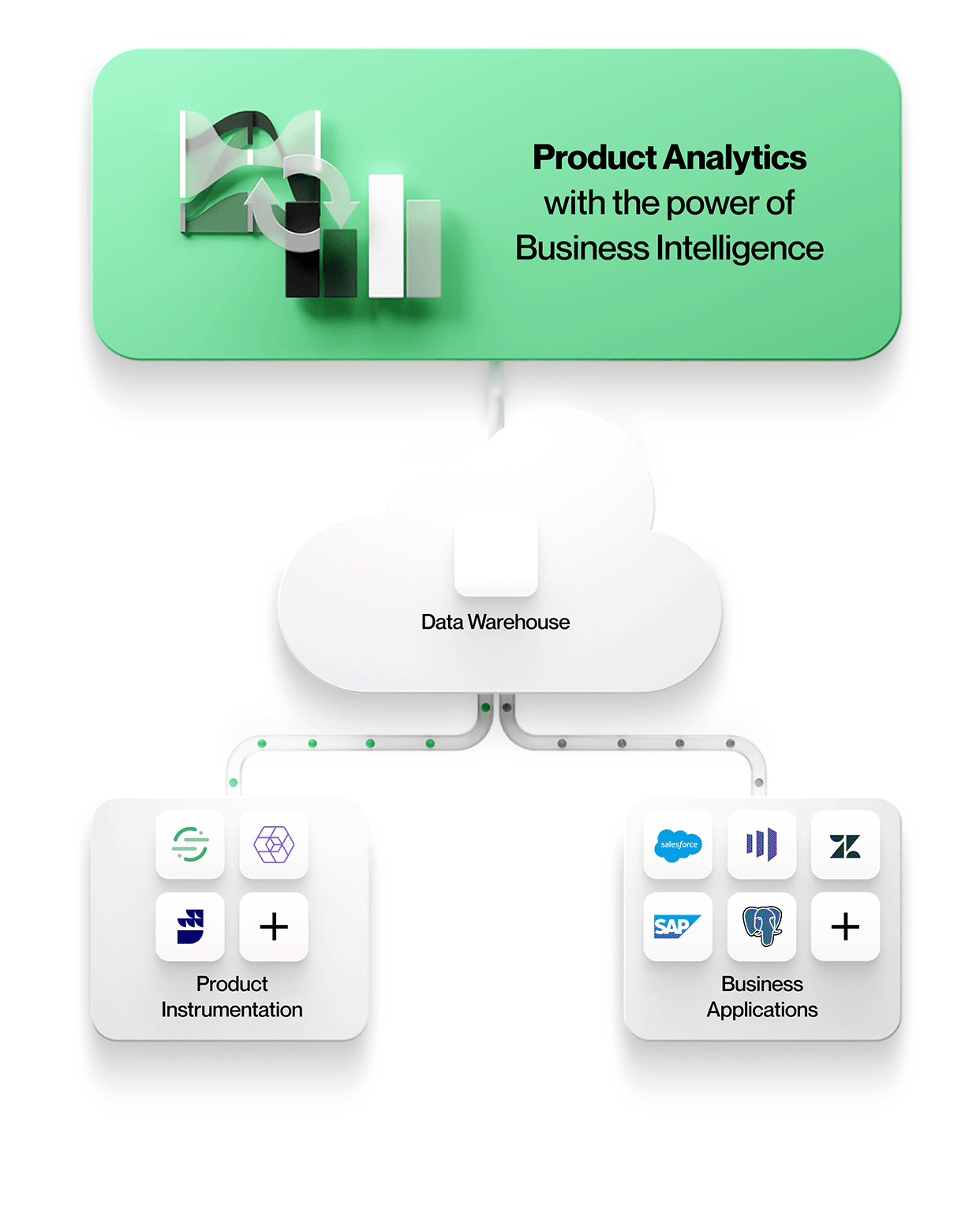
Optimizely Warehouse-native Analytics kan ansluta till alla större leverantörer av molnbaserade datalager, inklusive Snowflake®, Google BigQuery™, Amazon Redshift och Databricks, för att tillhandahålla en digital upplevelseanalys i världsklass genom att använda de bästa lösningarna för varje arbetsflöde.

- Last modified:2025-04-26 00:16:46