
Produktanalysverktyg som Amplitude och Mixpanel har funnits i över ett decennium, och de föregick den moderna datastack som blir allt vanligare nu. Det finns nu en koppling mellan den värld som dessa analysverktyg byggdes för och verkligheten för hur team arbetar med företagsdata idag. Detta leder till en viktig fråga: hur bör produktanalys utvecklas för att passa in i den moderna datastacken?
För att svara på det måste vi börja med att ta itu med en grundläggande fråga: Vad är den moderna datastacken?
Den moderna datastacken
När det gäller analys definierar vi den moderna datastacken med hjälp av följande egenskaper:
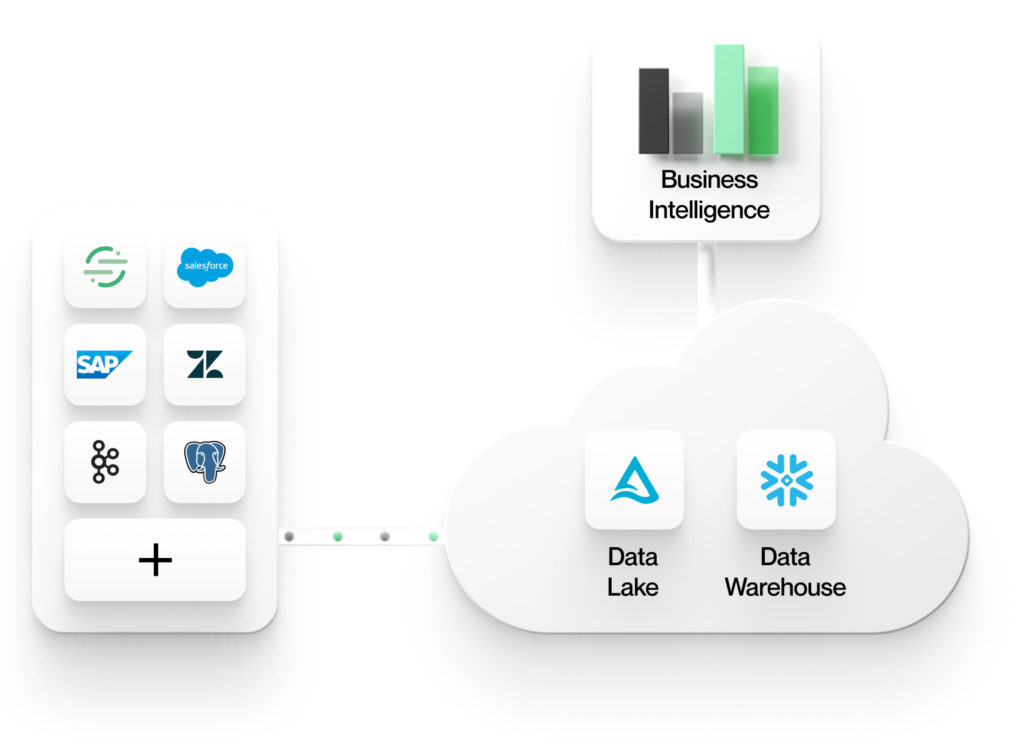
1. Alla data kommer till en gemensam central datalagring i molnet för hela företaget
Detta lager kan vara en datasjö som bygger på ett objektlager som AWS S3, eller det kan vara ett datalager som Snowflake. Oavsett om man använder en lakehouse- eller warehouse-arkitektur standardiserar företagen att all data ska finnas i centrala butiker. En gemensam central lagring ger fördelar när det gäller konsekvens, säkerhet, styrning och hanterbarhet.
2. Analysverktygen arbetar direkt med data i dessa butiker
Analysverktyg i den moderna datastacken, t.ex. för Business Intelligence (BI) eller AI/ML, behöver inte ETL:a data ut till andra åtskilda datalager. Detta garanterar en enda sanningskälla för dina data och ger konsekventa analytiska insikter i hela företaget. Genom att använda öppna format i datasjön eller datalagret blir dina data tillgängliga för alla verktyg, så att du kan undvika leverantörslåsning. Att arbeta direkt i ett centralt lager gör det också lättare att lära sig av dina data och agera utifrån dem. Allt sammanhang du behöver finns samlat på ett ställe, istället för att vara uppdelat i flera åtskilda delar.
Tillståndet för produktanalys
I motsats till det centrala lager som används av moderna datasystem är de flesta produktanalysverktyg som finns tillgängliga idag åtskilda, proprietära, muromgärdade system.
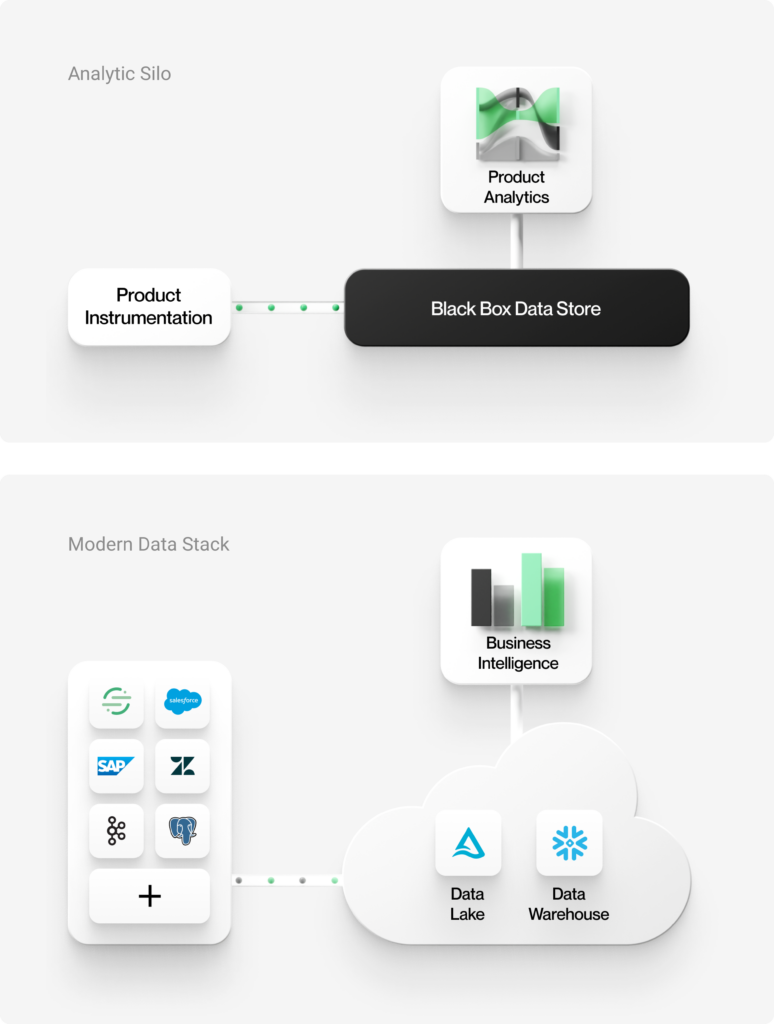
Åtskilda data
Vanligtvis arbetar produktanalysverktyg med åtskilda data. De har implementerade produktinstrumentbibliotek som samlar in och lagrar data i svarta lådor inom en sluten plattform. Även om du använder ett frikopplat instrumentbibliotek från en tredjepartsleverantör måste dina data skickas till verktygets svarta lådor för att du ska kunna använda ett analysverktyg.
Eftersom dessa produktanalysverktyg är beroende av åtskilda system kan de bara arbeta med en delmängd av dina data, utan koppling till den stora majoriteten av företagsdata i ditt centrala lager. I bästa fall kan du ta in en liten uppsättning egenskaper från ett datalager eller en datasjö med hjälp av "omvänd ETL"-verktyg. Tyvärr kommer dessa att hämtas in som enkla egenskaper med ett enda värde och måste tvingas in i en förplanerad datamodell.
Som ett resultat av detta åtskilda tillvägagångssätt är det svårt att knyta insikter från produktanvändningsdata till den bredare affärspåverkan. Dessa system kan bara utföra analyser av en enda kanal och saknar sammanhang från andra affärssystem som försäljning, support, Voice of Customer och finans.
Fragmenterad analys
Den åtskilda arkitekturen resulterar i fragmenterade analyser. Användarna får analyser som är begränsade till användningen av produkten genom dessa traditionella verktyg för produktanalys. När de vill ha mer detaljerade insikter om kundbeteende utanför produkten måste de vända sig till sina datateknik- och BI-team för att bygga anpassade rapporter. Att genomföra den här analysen kan ta flera veckor. Analytikerna måste ETL:a data från black box-lagren, skriva komplexa SQL-frågor och anpassa BI-verktyg som inte är anpassade för den här typen av analyser.
Det är inte bara komplicerat och kostsamt att göra detta, utan du har nu också analyser i två separata system utan möjlighet att dela sammanhang eller sömlöst flytta fram och tillbaka mellan dem. Ofta är datapipelines inte anslutna, vilket gör att analytiker måste arbeta med ögonblicksbilder (enstaka anpassade rapporter). Att ha flera åtskilda datasilos är ett enormt TCO-problem för företagen.
Det finns också problem med säkerhet och integritet. Det blir allt viktigare att kunddata stannar inom ramarna för företagskontrollerade butiker istället för att förvaras någon annanstans i potentiellt osäkra och icke-kompatibla miljöer.
Produktanalys i den moderna datastacken
Låt oss nu se hur produktanalys bör se ut när den bygger på en modern datastack.
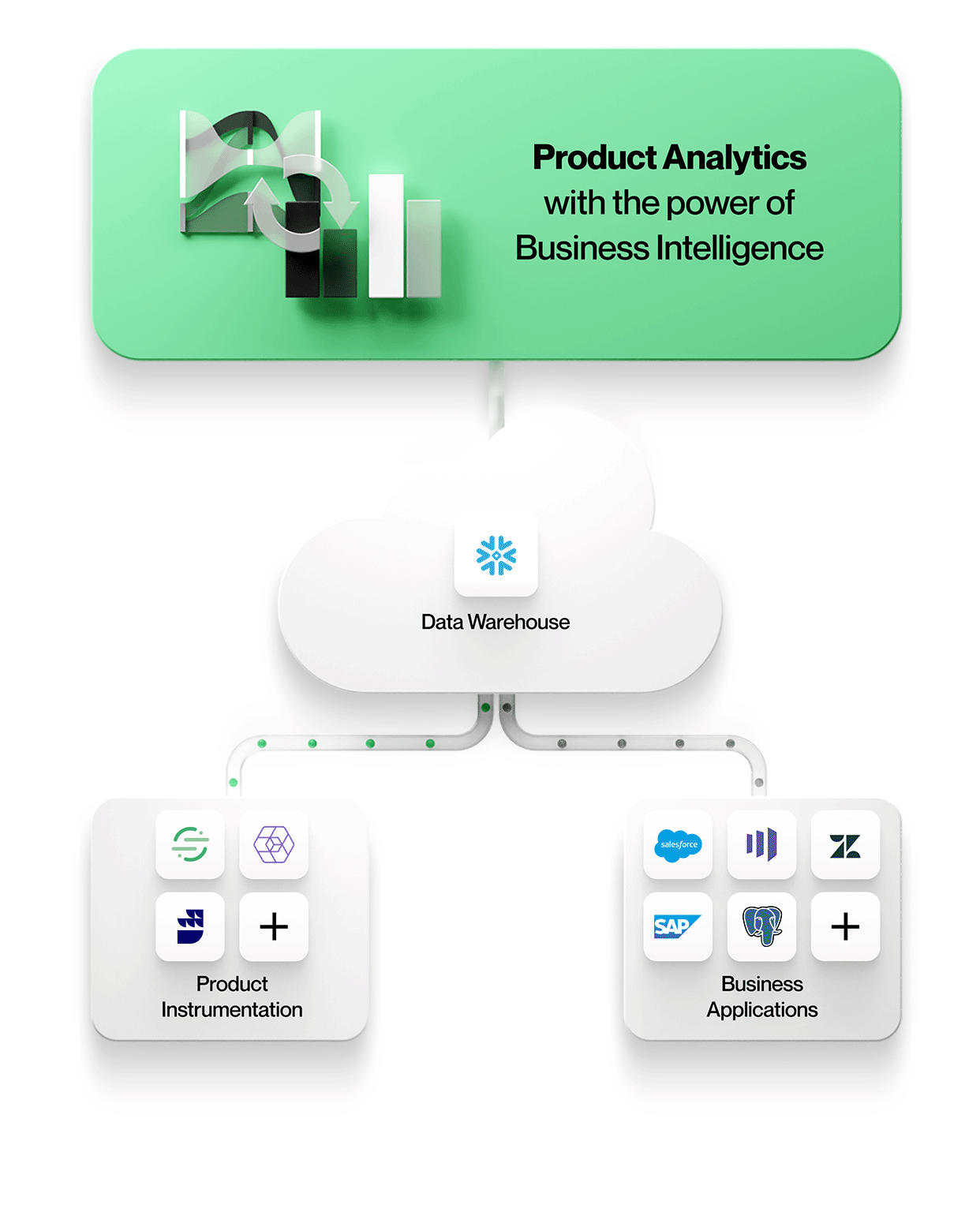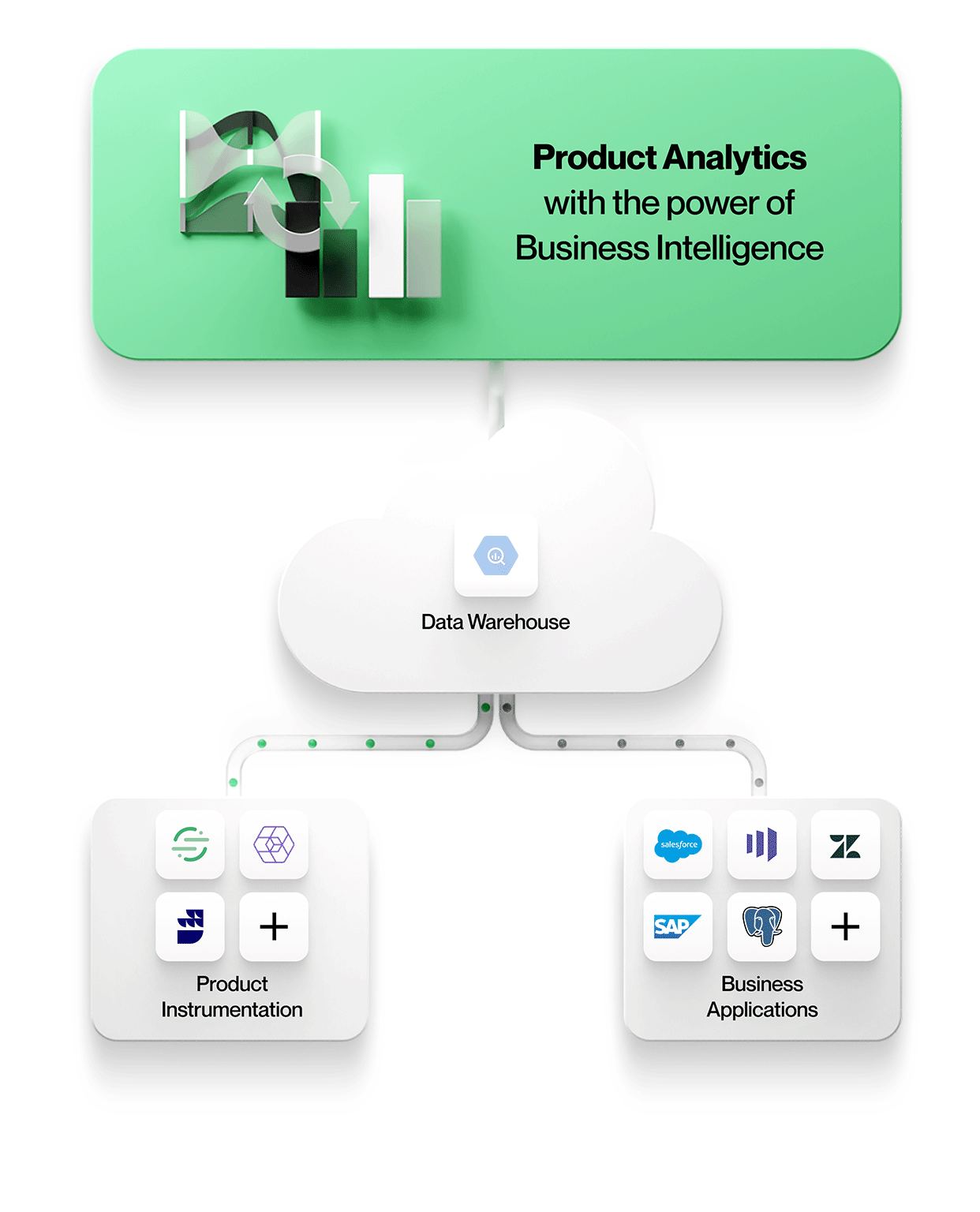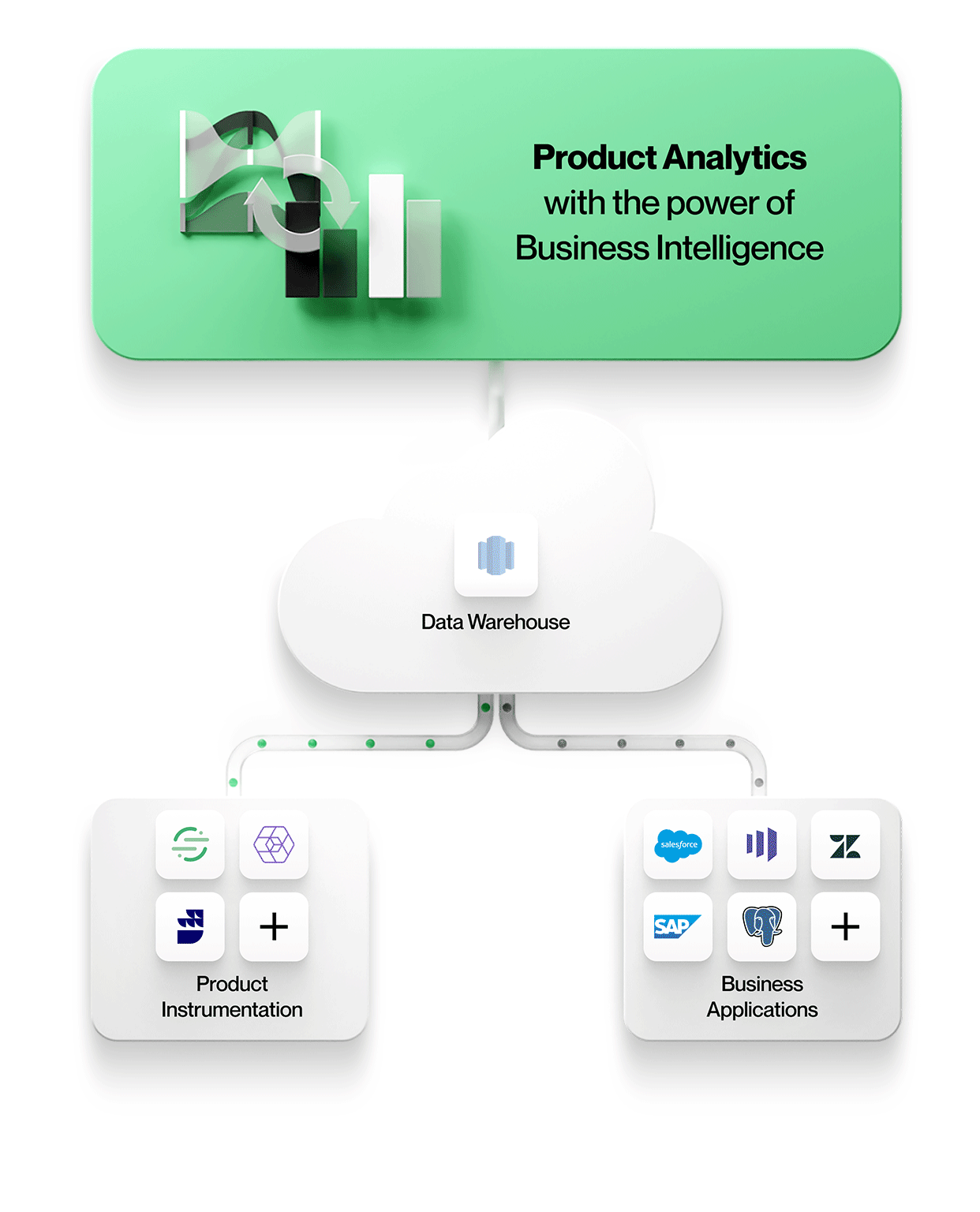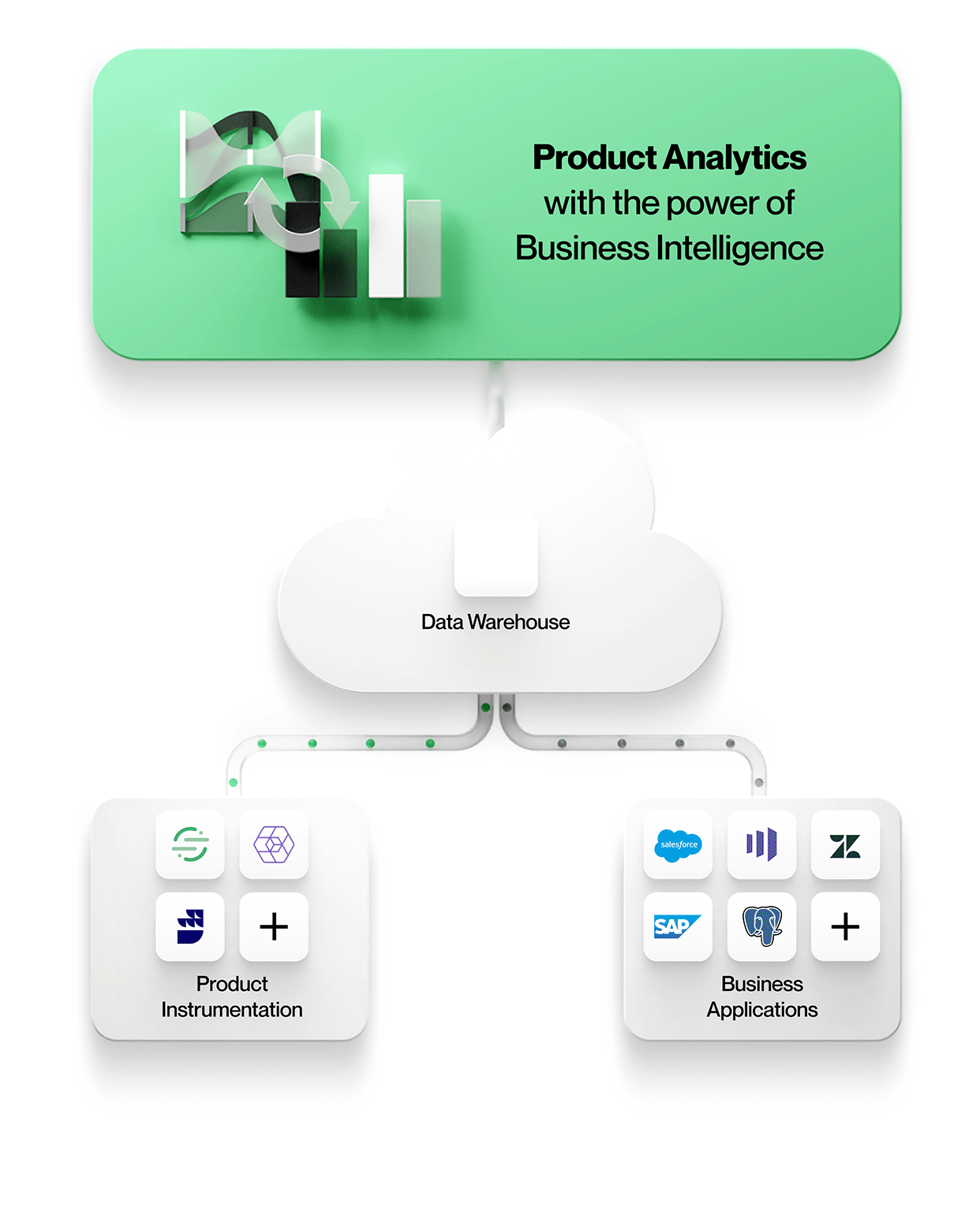
-
Data från produktinstrumentering lagras tillsammans med all annan företagsdata
Alla data, inklusive produktinstrumentering, hamnar i samma centrala datasjö eller lager. Detta förenklar hanteringen med en säker, styrd lagring och gör att man undviker åtskilda data. -
Produktinstrumentering är frikopplad från analys
Produktinstrumentering är opåverkad. Den dikterar inte någon särskild datamodell och tvingar dig inte heller att använda ett särskilt analysverktyg.
Med frikopplad och obunden instrumentering kan du modellera din unika verksamhet på ett korrekt sätt, istället för att tvingas använda en datamodell som dikteras av en leverantör. Det gör också att den instrumenterade datan kan användas av alla analysverktyg. Produkter som Snowplow och RudderStack möjliggör en sådan frikopplad instrumentering. -
Verktyg för produktanalys arbetar direkt med data i den centrala datasjön eller lagerbutiken
För att möjliggöra kontextrik produktanalys måste verktygen integrera data från andra affärssystem i sin ursprungliga form. Det innebär att man arbetar med enheter och deras relationer exakt som de ser ut i affärssystemen, t.ex. med enheter som konton, kontrakt, intäkter och leads från Salesforce, tickets, SLA:er och tasks från Zendesk eller kunder, projekt och nivåer från NetSuite. Produktanalys kan förstås i sitt sammanhang och korreleras med affärsresultat, vilket gör din analys mer värdefull och relevant för alla i organisationen.
Produktanalysdata bör också transformeras och sökas på samma sätt som andra data: till exempel genom att använda DBT för att göra datatransformationer eller SQL för att söka data med en relationsmodell. På så sätt kan du utnyttja den expertis och de verktyg som redan används inom företaget. Det gör också att alla verktyg, t.ex. ett AI/ML-verktyg eller en anpassad applikation, enkelt kan utnyttja dessa data.
Sammantaget resulterar denna moderna arkitektur för produktanalys i lägre TCO och högre affärseffekt. Att förstå dina data med alla dess sammanhang är framtiden för produktanalys.
Vill du lägga till modern produktanalys i din datastack?
Optimizely Warehouse-Native Analytics erbjuder en nästa generations plattform för produkt- och beteendeanalys som är specialbyggd för den moderna datastacken.

Entreprenör, chef och produktledare med dokumenterad erfarenhet av att utforma och bygga innovativa, framgångsrika och storskaliga mjukvarusystem Företagsbyggare...
- Last modified:2025-04-26 00:16:45