Historien bakom vår Stats Engine

Klassiska statistiska tekniker, som t-testet, är grunden för optimeringsbranschen och hjälper företag att fatta datadrivna beslut. I takt med att experimentering på nätet har exploderat står det nu klart att dessa traditionella statistiska metoder inte är rätt för digitala data: Att tillämpa klassisk statistik på A/B-testning kan leda till felfrekvenser som är mycket högre än vad de flesta experimentörer förväntar sig.
Både bransch- och akademiska experter har vänt sig till utbildning som lösningen. Kika inte! Använd en kalkylator för urvalsstorlek! Undvik att testa för många mål och variationer på en gång!
Men vi har kommit fram till att det är dags för statistik, inte kunder, attförändras. Säg adjö till det klassiska t-testet. Det är dags för statistik som är enkel att använda och som fungerar med hur företag faktiskt arbetar.
Tillsammans med ett team av Stanford-statistiker har vi utvecklat Stats Engine, ett nytt statistiskt ramverk för A/B-testning. Vi är glada över att kunna meddela att från och med den 21 januari 2015 ger det resultat för alla Optimizely One-kunder.
Det här blogginlägget är långt, eftersom vi vill vara helt transparenta med varför vi gör dessa förändringar, vad förändringarna faktiskt är och vad det betyder för A/B-testning i stort. Håll dig till oss till slutet så får du lära dig:
- Varför vi gjorde Stats Engine: Internet gör det enkelt att utvärdera resultat från experiment när som helst och köra tester med många mål och variationer. I kombination med klassisk statistik kan dessa intuitiva åtgärder öka risken för att felaktigt förklara en vinnande eller förlorande variation med över 5x.
- Hur det fungerar: Vi kombinerar sekventiell testning och kontroller av falsk upptäcktsfrekvens för att leverera resultat som är giltiga oavsett urvalsstorlek och matchar den felprocent vi rapporterar till den felprocent som företagen bryr sig om.
- Varför det är bättre: Stats Engine kan minska risken för att felaktigt förklara en vinnande eller förlorande variation från 30% till 5% utan att offra hastigheten.
Varför vi skapade en ny Stats Engine
Traditionell statistik är ointuitiv, lätt att missbruka och lämnar pengar på bordet.
För att få giltiga resultat från A/B-testningar som körs med klassisk statistik måste noggranna experimentörer följa en strikt uppsättning riktlinjer: Ställ in en minsta detekterbar effekt och urvalsstorlek i förväg, kika inte på resultaten, testa inte för många mål och variationer samtidigt.
Dessa riktlinjer kan vara besvärliga, och om du inte följer dem noggrant kan du omedvetet införa fel i dina tester. Det är problemen med dessa riktlinjer som vi ville ta itu med med Stats Engine:
- Att i förväg binda sig för en påvisbar effekt och urvalsstorlek är ineffektivt och inte intuitivt.
- Om du tittar på resultaten innan du har uppnått denna urvalsstorlek kan det leda till fel i resultaten, och du kan vidta åtgärder på falska vinnare.
- Testning av för många mål och variationer samtidigt ökar felen på grund av falska upptäckter - en felfrekvens som kan vara mycket större än den falska positivfrekvensen.
Att binda sig till en urvalsstorlek och en detekterbar effekt kan sakta ner dig.
Att fastställa en urvalsstorlek innan du kör ett test hjälper dig att undvika misstag med traditionella statistiska metoder, För att fastställa en urvalsstorlek måste du också gissa vilken minsta detekterbara effekt (MDE), eller förväntad ökning av konverteringsgraden, du vill se från ditt test. Om du gissar fel kan det få stora konsekvenser för din testhastighet.
Om du anger en liten effekt måste du vänta på ett stort urval för att veta om dina resultat är signifikanta. Om du anger en större effekt riskerar du att gå miste om mindre förbättringar. Det här är inte bara ineffektivt, det är inte heller realistiskt. De flesta människor gör tester för att de inte vet vad som kan hända, och att i förväg binda sig vid ett hypotetiskt lyft är helt enkelt inte särskilt vettigt.
Att kika på dina resultat ökar din felfrekvens.
När data flödar in i ditt experiment i realtid är det frestande att ständigt kontrollera dina resultat. Du vill implementera en vinnare så snart du kan för att förbättra din verksamhet, eller stoppa ett ofullständigt eller förlorande test så tidigt som möjligt så att du kan gå vidare och testa fler hypoteser.
Statistiker kallar detta ständiga tittande för "kontinuerlig övervakning", och det ökar chansen att du hittar ett vinnande resultat när det faktiskt inte finns något (naturligtvis är kontinuerlig övervakning bara problematisk när du faktiskt stoppar testet tidigt, men du förstår poängen). Att hitta en obetydlig vinnare kallas en falsk positiv, eller typ I-fel.
Alla test för statistisk signifikans som du kör kommer att ha en viss risk för fel. Om du kör ett test med 95 % statistisk signifikans (med andra ord ett t-test med ett alfavärde på 0,05) innebär det att du accepterar 5 % risk för att testet skulle visa ett signifikant resultat om det vore ett A/A-test utan någon faktisk skillnad mellan variationerna.
För att illustrera hur farlig kontinuerlig övervakning kan vara simulerade vi miljontals A/A-testningar med 5.000 besökare och utvärderade risken att göra ett fel med olika typer av policyer för kontinuerlig övervakning. Vi fann att även konservativa policies kan öka felfrekvensen från en målgruppsinriktning på 5% till över 25%.
I vår undersökning utsåg mer än 57% av de simulerade A/A-testningarna felaktigt en vinnare eller förlorare minst en gång under testets gång, även om det bara var för en kort stund. Med andra ord, om du hade tittat på dessa tester skulle du kanske ha undrat varför dina A/A-testresultat utsåg en vinnare. Ökningen av felprocenten är fortfarande meningsfull även om du inte tittar på varje besökare. Om du tittar på var 500:e besökare ökar risken för en falsk deklaration till 26 %, medan risken ökar till 20 % om du tittar på var 1000:e besökare.
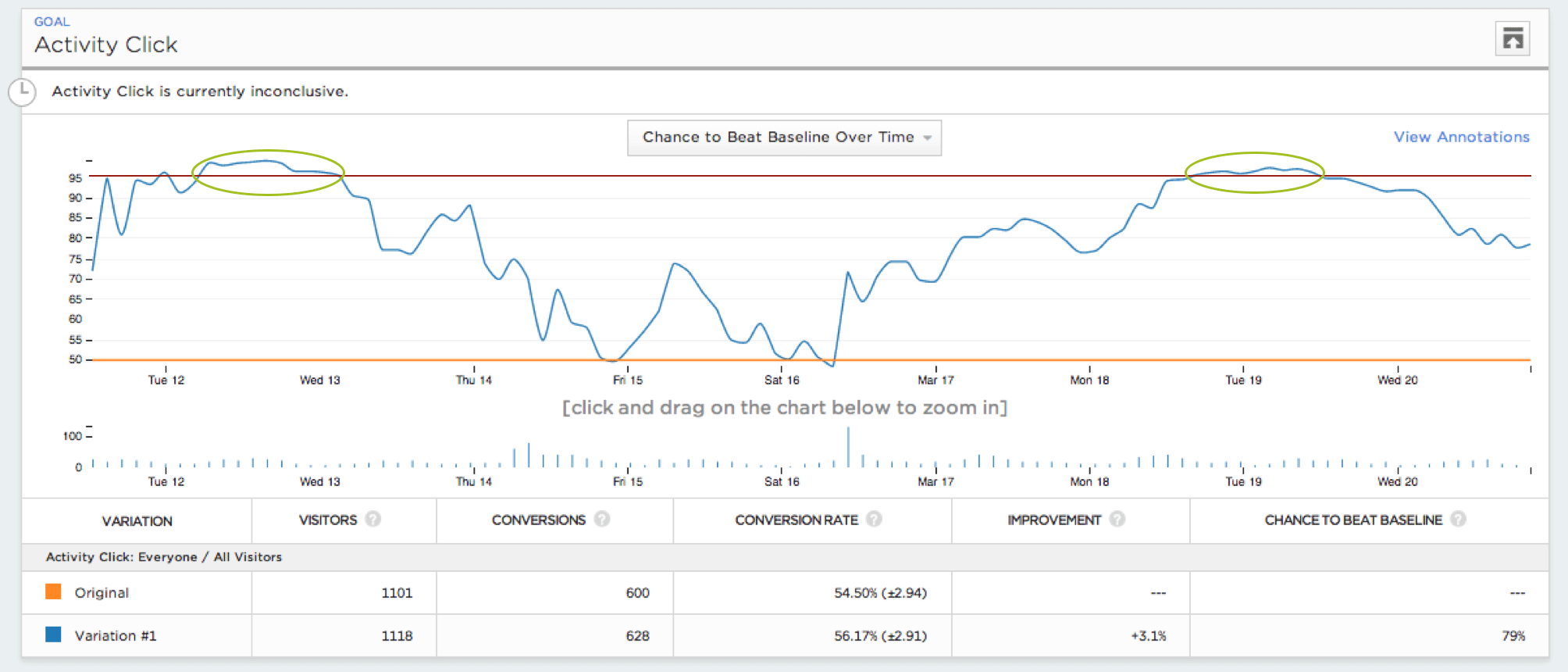
Det här diagrammet över den statistiska signifikansen för en A/A-testning över tid visar var experimentören skulle ha sett ett signifikant resultat om hon hade övervakat testet kontinuerligt.
Även om du är medveten om det här problemet kan rimliga "korrigeringar" fortfarande leda till höga felfrekvenser. Anta till exempel att du inte litar på ett signifikant resultat för din A/B-testning. Som många Optimizely-användare kanske du använder en kalkylator för urvalsstorlek medan ditt test redan körs för att avgöra om ditt test har körts tillräckligt länge. Att använda kalkylatorn för att justera urvalsstorleken när testet körs är vad som kallas en "post-hoc-beräkning", och även om det minskar risken för kontinuerlig övervakning leder det fortfarande till felfrekvenser som ligger runt 25%.
Hittills har det enda sättet att skydda sig mot dessa fel varit att använda kalkylatorn för urvalsstorlek innan man påbörjar testet och sedan vänta tills testet når sin urvalsstorlek innan man fattar beslut baserat på resultaten.
Den goda nyheten är att det faktiskt finns en ganska enkel men elegant statistisk lösning som gör att du kan se resultat som alltid är giltiga, när du än tittar, utan att behöva gissa på en minsta detekterbar effekt i förväg. Det kallas sekventiell testning, och vi kommer att diskutera det mer i detalj senare.
Att testa många mål och variationer samtidigt leder till fler fel än du kanske tror.
En annan fallgrop när man använder traditionell statistik är att testa många mål och variationer samtidigt (problemet med "multipla jämförelser" eller "multipel testning".) Detta händer eftersom traditionell statistik kontrollerar fel genom att kontrollera andelen falska positiva resultat. Men det här felet, det som du anger i din signifikanströskel, motsvarar inte risken för att fatta ett felaktigt affärsbeslut.
Den felfrekvens som du verkligen vill kontrollera för att korrigera för problemet med multipel testning är den falska upptäcktsfrekvensen. I exemplet nedan visar vi hur en kontroll av 10% falskt positiva resultat (90% statistisk signifikans) kan leda till 50% risk att fatta ett felaktigt affärsbeslut på grund av falska upptäckter.
Tänk dig att du testar 5 varianter av din produkt eller webbplats, som var och en har 2 mål som framgångsmått. En av dessa variationer överträffar baslinjen och förklaras korrekt som vinnare. Av ren slump skulle vi förvänta oss att ytterligare en variant felaktigt utsågs till vinnare (10 % av de 9 återstående kombinationerna av mål och variationer). Vi har nu 2 variationer som förklaras som vinnare.
Även om vi kontrollerade för en 10-procentig andel falska positiva resultat (1 falskt positiv) har vi ett mycket högre (50 %) förhållande mellan falska och bra resultat, vilket kraftigt ökar risken för att fatta fel beslut.

I det här experimentet finns det två vinnare av tio testade kombinationer av målvariationer. Endast en av dessa vinnare skiljer sig faktiskt från baslinjen, medan den andra är ett falskt positivt resultat.
Att kontrollera för falska positiva resultat är farligt eftersom experimentören omedvetet straffas för att testa många mål och variationer. Om du inte är försiktig tar du på dig en större praktisk risk än du är medveten om. För att undvika detta problem i traditionell A/B-testning måste du alltid komma ihåg antalet experiment som körs. Ett avgörande resultat från 10 tester är annorlunda än ett från 2 tester.
Lyckligtvis finns det ett principiellt sätt att få felfrekvensen i ditt experiment att matcha den felfrekvens du tror att du får. Stats Engine åstadkommer detta genom att kontrollera fel som kallas falska upptäckter. Den felfrekvens som du ställer in i din signifikanströskel med Stats Engine kommer att återspegla den verkliga risken för att fatta ett felaktigt affärsbeslut.
Hur Stats Engine fungerar
Stats Engine kombinerar innovativa statistiska metoder för att ge dig pålitliga data snabbare.
Under de senaste fyra åren har vi hört från våra kunder om ovanstående problem, och vi visste att det måste finnas ett bättre sätt att lösa dem än en kalkylator för urvalsstorlek och fler pedagogiska artiklar.
Vi samarbetade med Stanford-statistiker för att utveckla ett nytt statistiskt ramverk för A/B-testning som är kraftfullt, exakt och, viktigast av allt, enkelt. Denna nya Stats Engine är komponerbar av två metoder: sekventiell testning och kontroll av falsk upptäcktsfrekvens.
Sekventiell A/A-testning: Fatta beslut så snart du ser en vinnare.
I motsats till Fixed Horizon-testning, som förutsätter att du bara kommer att utvärdera dina experimentdata vid en tidpunkt, med en bestämd provstorlek, är sekventiell testning utformad för att utvärdera datainsamlingen när den samlas in. Sekventiella tester kan stoppas när som helst med giltiga resultat.
Experimentering har sällan en fast urvalsstorlek tillgänglig, och deras mål är vanligtvis att få en tillförlitlig slutsats så snabbt som möjligt. Stats Engine uppfyller dessa mål med en implementering av sekventiell testning som beräknar en genomsnittlig sannolikhetskvot - den relativa sannolikheten för att variationen skiljer sig från baslinjen - varje gång en ny besökare utlöser en händelse. P-värdet för ett test representerar nu chansen att testet någonsin kommer att nå den signifikanströskel som du väljer. Det är motsvarigheten till ett traditionellt p-värde för en värld där din provstorlek är dynamisk. Det här kallas ett test med styrka ett, och det passar bättre än ett traditionellt t-test för A/B-testning.
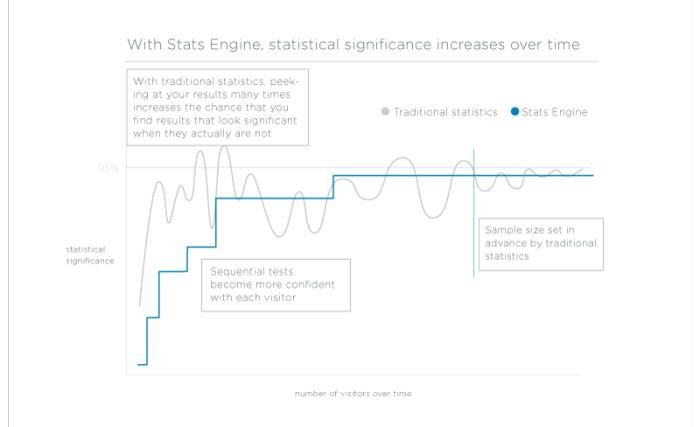
Det innebär att du får tillförlitliga, giltiga slutsatser så snart de är tillgängliga utan att behöva fastställa en minsta detekterbar effekt i förväg eller vänta på att nå en fast urvalsstorlek.
Kontroll av frekvensen för falska upptäckter: Testa många mål och variationer med garanterad noggrannhet.
Att rapportera en falsk upptäcktsfrekvens på 10% innebär att "högst 10% av vinnarna och förlorarna inte har någon skillnad mellan variation och baslinje", vilket är exakt risken för att fatta ett felaktigt affärsbeslut.
Med Stats Engine rapporterar Optimizely nu vinnare och förlorare med låg falsk upptäcktsfrekvens istället för låg falsk positiv frekvens. När du lägger till mål och variationer i ditt experiment kommer Optimizely att korrigera mer för falska upptäckter och bli mer konservativ när det gäller att kalla en vinnare eller förlorare. Även om färre vinnare och förlorare rapporteras totalt sett (vi hittade ungefär 20% färre i vår historiska databas*), kan en experimentering genomföras med full vetskap om risken.
I kombination med sekventiell testning ger kontroll av falsk upptäcktsfrekvens en korrekt bild av risken för fel när du tittar på testresultaten. Kontrollen ger dig en transparent bedömning av den risk du har för att fatta ett felaktigt beslut.
Det innebär att du kan testa så många mål och variationer som du vill med garanterad noggrannhet.
* På ett stort, representativt urval av historiska A/B-testningar av Optimizely-kunder fann vi att det fanns ungefär 20% färre variationer med falsk upptäcktsfrekvens mindre än .1 jämfört med falsk positiv frekvens på samma nivå.
Hur det är bättre
Optimizely's Stats Engine minskar felen utan att offra hastigheten.
Vi körde om 48 000* historiska experiment med Stats Engine och resultaten är tydliga: Stats Engine ger mer exakta och handlingsbara resultat utan att offra hastigheten.
Ha större förtroende för dina vinnare och förlorare.
Fixed Horizon-statistik förklarade en vinnare eller förlorare i 36 % av testerna (när testet stoppades.) I samma dataset förklarade Stats Engine vinnare eller förlorare i 22 % av testerna.
Stats Engine avslöjade 39% färre avgörande testresultat än traditionell statistik. Även om denna siffra kan vara alarmerande (och till en början var den alarmerande för oss också!) fann vi att många av dessa avbrutna experiment troligen avbröts för tidigt.
För att komma fram till detta resultat använde vi en metod som liknar den som kunder använder när de manipulerar kalkylatorn för urvalsstorlek för att avgöra om ett test har styrka (sannolikheten att du kommer att upptäcka en effekt om en sådan faktiskt finns) efter att det har startat - en post-hoc effektberäkning. Att köra tester med för låg styrka tyder på att det inte finns tillräckligt med information i data för att skilja mellan falskt positiva och sant positiva resultat. Med 80 % som vår standard för styrka var de flesta (80 %) av de experiment som Stats Engine inte längre kallade avgörande understyrda medan de flesta (77 %) av de experiment som Stats Engine behöll var styrkta.
Stabila rekommendationer du kan lita på.
Fixed Horizon-statistik ändrade sin förklaring av vinnare eller förlorare i 44% av våra historiska experiment. Stats Engine ändrade deklarationer i 6 % av dessa tester.
Med Fixed Horizon-statistik kunde du se en vinnare en dag och ett oklart resultat nästa dag. Den enda giltiga deklarationen var den med din förutbestämda provstorlek. Med Stats Engine är resultaten alltid giltiga och det är osannolikt att de ändrar ett avgörande resultat.
Med Stats Engine sjönk andelen falska positiva resultat från >20% till <5%.
Minns våra simuleringar av A/A-testning (varje test kördes på 5000 besökare) när vi diskuterade farorna med att tjuvkika. I dessa simuleringar körde vi tester med 95% signifikans och hittade:
- Om du tittade på resultaten efter varje ny besökare experimentet, finns det en 57% chans att förklara en vinnare eller förlorare.
- Om du tittade på var 500:e besökare är det 26% chans att det blir en falsk deklaration.
- Om man tittar på var 1000:e besökare är risken för en felaktig deklaration 20 %.
- Med sekventiell testning (där man tittar efter varje besökare) sjunker samma felnummer till 3%.
Om vi kör dessa simuleringar på större urvalsstorlekar (t.ex. 10 000 eller till och med 1 000 000 besökare) ökar risken för en falsk deklaration med traditionell statistik (lätt över 70 % beroende på urvalsstorlek) oavsett hur ofta du tittar på dina resultat. Med sekventiell testning ökar också denna felfrekvens, men den övre gränsen ligger på 5%.
Det finns ingen hake: Exakta och användbara resultat behöver inte gå ut över hastigheten.
Efter att ha läst så här långt kanske du frågar dig: Vad är haken? Det finns inte någon.
Här är varför: Att välja en korrekt urvalsstorlek innebär att man i förväg väljer en minsta detekterbar effekt. Som diskuterats tidigare är det en svår uppgift. Om du för varje experiment (innan du kör det) ställer in MDE inom 5 % av experimentets faktiska lyft, kommer det sekventiella testet att vara i genomsnitt 60 % långsammare.
Men i verkligheten väljer utövarna ett MDE som är utformat för att vara lägre än de observerade lyften. Det återspeglar den längsta tid de är villiga att köra ett experiment. Med Stats Engine kommer du att kunna göra ditt test snabbare när det verkliga lyftet är större än ditt MDE.
Vi fann att om lyftet i din A/B-testning hamnar 5 procentenheter (relativt) högre än din MDE, kommer Stats Engine att köras lika snabbt som Fixed Horizon-statistiken. Så snart förbättringen överstiger MDE med så mycket som 7,5 procentenheter är Stats Engine närmare 75 % snabbare. För större experiment (>50 000 besökare) är vinsterna ännu högre och Stats Engine kan utse en vinnare eller förlorare upp till 2,5 gånger så snabbt.
Förmågan att få tester att köras på rimlig tid är en av de svåraste uppgifterna när det gäller att tillämpa sekventiell testning på A/B-testning och optimering. Vår stora databas med historiska experiment gör att vi kan ställa in Stats Engine utifrån tidigare information. Genom att utnyttja vår omfattande databas med upplevelseoptimering kan Optimizely leverera de teoretiska fördelarna med sekventiell testning och FDR-kontroll utan att införa praktiska kostnader.
* En anmärkning om data: Datauppsättningen vi testade hade experiment med en median på 10 000 besökare. Tester med ett lägre antal besökare hade ett lägre antal deklarationer i både Fixed Horizon Testing och Stats Engine, ett liknande antal ändrade deklarationer, men vi är snabbare att visa hastighetsvinster för sekventiell testning.
Vad detta betyder för varje testkörning fram till idag
Låt oss klargöra en sak: Traditionell statistik kontrollerar fel vid förväntade priser när denanvänds korrekt. Det innebär att om du har använt en kalkylator för urvalsstorlek och följt dess Recommendations behöver du förmodligen inte oroa dig för tester som du har kört tidigare. På samma sätt, om du tenderar att fatta affärsbeslut som endast baseras på primära konverteringsmått, minskar skillnaden mellan din falska upptäckt och falska positiva grad. För Optimizely One-användare som redan vidtog dessa försiktighetsåtgärder kommer Stats Engine att ge ett mer intuitivt arbetsflöde och minska ansträngningen för att köra tester.
Vi vet också att det finns många människor där ute som förmodligen inte gjorde exakt vad kalkylatorn för provstorlek sa till dig att göra. Men digitala experimentörer är ett kunnigt och skeptiskt gäng. Du kanske väntade ett visst antal dagar innan du ringde resultaten, väntade längre om saker och ting såg skumma ut eller körde om din beräkning av urvalsstorleken varje gång du tittade för att se hur mycket längre du skulle vänta. Alla dessa metoder hjälper till att bekämpa risken för att göra ett fel. Även om din felfrekvens sannolikt är högre än 5%, skulle den förmodligen inte heller vara över 30%. Om du tillhör den här gruppen befriar Stats Engine dig från dessa metoder och ger dig istället exakta förväntningar på de felprocent du kan förvänta dig.
Ett litet steg för Optimizely, ett jättekliv för onlineoptimering
Optimizely's mission är att göra det möjligt för världen att omvandla data till handling. För fem år sedan tog vi vårt första steg mot detta uppdrag genom att göra A/B-testning tillgänglig för icke-ingenjörer med vår Visual Editor. Nu har tiotusentals organisationer anammat en filosofi som går ut på att implementera data i varje beslut.
Idag, med Stats Engine, vill vi ta branschen ett steg längre genom att ta bort ännu en barriär för att bli en datadriven organisation. Genom att ge vem som helst möjlighet att analysera resultat med kraftfull statistik vill vi ge företag möjlighet att stödja ännu fler viktiga beslut med data.
Att få rätt statistik är avgörande för att fatta datadrivna beslut, och vi är fast beslutna att utveckla vår statistik för att stödja våra kunder. Vi ser fram emot att arbeta tillsammans med dig för att skriva nästa kapitel om onlineoptimering.
Vi ser fram emot din feedback och dina tankar om statistik. Låt oss veta vad du tycker i kommentarerna!
Vill du lära dig mer? Vi har skapat ett antal ytterligare resurser för att hjälpa dig att komma igång med statistik med Optimizely:

Leo har en doktorsexamen i statistik från Stanford och är Optimizely's första interna statistiker. Han brinner för att ge alla möjlighet att dra nytta av fördelarna...
- Last modified:2025-04-26 00:15:00