
Test + Learn (the AI virtual event built specifically for experimentation teams) was back in 2026, and it absolutely delivered on answering one question.
What does AI in experimentation actually look like when you're inside a real program, with real data, real teams, and real internal politics?
We brought in Elena Verna (Head of Growth at Lovable) to keynote. It was followed by sessions with Brandon Brackett (Salesforce), Bhav Patel (Huel), Calley Bowser (ASOS), Shaun Dolan (Kingfisher), Divya Isaiah (BBC), and Grace Miller (Flight Story).
Five sessions, and a lot of operational specifics that don't usually get shared this honestly.
Missed it? Don't worry, it's all available on demand. But first, here's your sneak peek at the key takeaways.
1. Elena Verna: Stop optimizing the small stuff. The product is moving too fast for it to matter.
Elena opened with the claim that 60 to 80% of growth tactics no longer work, and the reason is feature velocity. In AI-native companies, 80 to 90% of the code is now written by AI, which means feature differentiation that used to last years now lasts a month or two.
She knows because she's living it. Lovable is 18 months old, past $400M ARR, and her team has to reinvent product-market fit every month to two months. The small optimization tweaks she focused on for most of her career have stopped paying back. By the time you find a small win, the product has already moved past it.
Elena believes most experimentation programs are over-experimenting on the wrong things, and not patient enough on the right ones. Too many teams judge tests on 7-day windows. The biggest uplifts she's seen came from watching what happened to a cohort at week two, week three, and beyond. Retention impacts. Second-week engagement. Behavior that only shows up after the initial response fades.
And the work she's most excited about isn't on UI surfaces anymore. As product interfaces collapse into a prompt box, experimentation moves onto agent behavior. The tests that matter are about how an agent responds to a user, not how a page converts.
Watch Elena's full keynote on demand →
2. Brandon Brackett (Salesforce): The first thing AI should fix isn't experimentation. It's the work around it.
When Brandon's team at Salesforce mapped their full experimentation workflow against the agents they could deploy, they didn't lead with ideation or test build. They started with operations.
Brandon was pulling three to four different project boards every week just to put together his team's to-dos. Slackbot now handles intake to output, templates, output documentation, and posts results to the right Slack channels automatically. The hours saved per week aren't the story by themselves. The story is what it freed up.
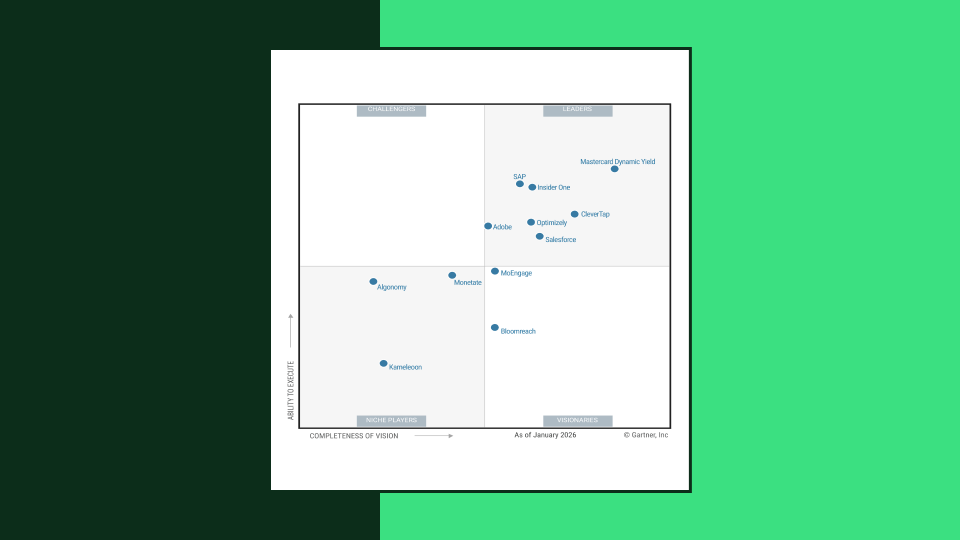
Salesforce achieved a 200% increase in velocity last year. The AI work is what they did with the breathing room. They mapped where each Opal agent could plug into existing workflow stages, and where they'd need custom agents to fill gaps. Brandon's product team and Optimizely's product team independently drew the same workflow chart and flagged the same gaps. That alignment is why the rollout worked at scale.
The part that excites Brandon most is that stakeholders across Salesforce can now self-serve from years of categorized experimentation insights, in a way that gets them the answers they need to act on. The end state is a program where the experimentation team enables the rest of the business, instead of being the bottleneck that the rest of the business waits on.
His advice for teams getting started: Do it quickly, and fail often. The teams that wait for a perfect plan get overtaken by the teams that ship.
Watch Brandon's session on demand →
3. Bhav Patel (Huel): Self-serve only works when the data underneath it does
Most analysts at Huel were spending their time pulling metrics, reconciling experiment data with business data across different systems, and aligning definitions nobody had agreed on. AI absorbed most of that work.
The output is what Bhav calls the trading supercomputer. The name is a joke he hates. It's seven or eight sub-agents running across specific data sets, feeding a mediator agent that posts Monday-morning insights into trading Slack channels. Work that used to take one person several weeks now arrives in real time, with context, every week.
Before the trading supercomputer ever went live, Bhav and four or five people on Bhav's team manually validated every output of every agent. They caught semantic drift, fed context back, and only opened it up to the wider business once they trusted what was coming out.
And Huel doesn't let people loose on the raw data warehouse with AI. Their BI layer is fully accessible because the business logic and definitions are already modeled into it. They do not give people raw Snowflake access through Claude. The data warehouse stays gated. The modeled layer above it is open.
This is the most concrete AI governance pattern from any session. Self-serve works when the data has already been modeled with business context. It breaks when people ask questions of raw tables and get confident answers that happen to be wrong.
Watch Bhav's session on demand →
4. Calley Bowser and Shaun Dolan (ASOS and Kingfisher): The hardest part of scaling AI is letting go of what worked in the past.
Calley's team at ASOS watched product managers take around two weeks to figure out what a test result was actually saying. The Summarized Results Agent cut that average in half. The output is non-technical enough to send to a non-technical stakeholder, which means the readout actually reaches the people who need to act on it.
The unexpected outcome was that test quality went up alongside velocity. Better planning from the ideation and planning agents produced better-designed tests, not just more of them.
The trickier part of Calley's story was adoption. Her data science team pushed back hardest on Opal's responses. Rather than treat that as resistance, ASOS asked Optimizely to walk them through how the responses were being generated. The scrutiny was what built real trust. If you're rolling AI into an experimentation program, the people who push back hardest are usually the people you most need to bring along.
Shaun at Kingfisher is at the start of the same curve, and his plan for the next 12 months is to begin with the bookends: test design at the front of the workflow, analysis and reporting at the back, with governance wrapping both. He sees that order as the fastest path to value, because those are the stages where AI most obviously reduces the manual load without disrupting how teams already work together.
He also flagged a cultural shift that has to come with it. His organization leans toward test-to-win rather than test-to-learn. The Summarized Results Agent is part of what changes that, because when readouts are legible to non-experts, learning travels more easily through the business. The job of the experimentation practitioner moves up the value chain alongside that shift, away from the manual checkpoints AI now absorbs.
Watch the ASOS and Kingfisher session on demand →
5. Divya Isaiah and Grace Miller (BBC and Flight Story): AI is trained on averages, so it builds for averages.
At the BBC, Divya is paying close attention to what AI is good at and where it falls short. The thing she keeps coming back to is that AI is trained on averages, so it builds for averages. If you want it to do something useful for your business, you have to identify the outliers worth building for and feed that back in as context. She thinks the next two or three years of work in experimentation are going to be less about prompts and more about what you put into the model in the first place.
For most teams, experimentation has been a measurement tool. AI is making the measurement cheaper, which means experimentation now has more room to be a tool for thinking. A way to surface assumptions you didn't know you were making and test them properly.
Grace at Flight Story brought the honest version of what AI looks like in practice. She thinks the industry needs to be more straightforward about the fact that prompting is hard and that AI knowledge varies wildly even between people on the same team. She herself couldn't replicate what one of her own teammates had built with Claude Code, and she said so on stage. The posts online claiming someone built an AI agent that replaces a whole marketing team are mostly people overselling what actually worked.
What does work at Flight Story is years of thumbnail testing on every episode of Diary of a CEO. The first big test was whether to put Steve Bartlett's face on the thumbnail. It won every time. Then they tested whether hands should be in the shot. Then, facial expressions, colors, and graphic styles. AI now generates the variations for them, which means they can test more of them per episode. The testing didn't change. The cost of producing the variations did.
Watch the BBC and Flight Story session on demand →
The patterns underneath
A few things came up across more than one session:
-
Better inputs matter more than better prompts. Most of the work in making AI useful is getting your data, definitions, and brand voice into shape first.
-
AI doesn't create problems. It shows you the ones you already had. The teams getting the most out of it are treating that as the point, not a setback.
-
Almost everyone went after analysis before they touched ideation. Results, summaries, and reporting are where AI is paying back fastest.
Watch the full event on demand
The recordings are up, including the live agent demos that ran between sessions.

Ja, en marknadsförare och en copywriter ... men mer lam än de flesta. Jag försöker använda AI och här att vara en tänkare snarare än bara en publicist, men egentligen...
- Last modified:2026-06-17 15:51:17