Lagerspegling kontra warehouse-native analytics

Nästa generation av produktanalys har vuxit fram med Modern Data Stack. Det är en unik arkitektur som bygger på en centraliserad datalagring i molnet för all data och erbjuder betydande fördelar när det gäller kostnad och analytisk sofistikering.
I en tidigare blogg tittade Vijay Ganesan på både första generationens och nästa generations produktanalys och utforskade hur produktanalys måste utvecklas för att passa in i Modern Data Stack. I den här bloggen kommer vi att belysa skillnaderna mellan en modern lagerbaserad metod och en evolutionär lösning från första generationens verktyg som leder till att data importeras eller exporteras ut ur lagret.
Warehouse-native analytics för produkter
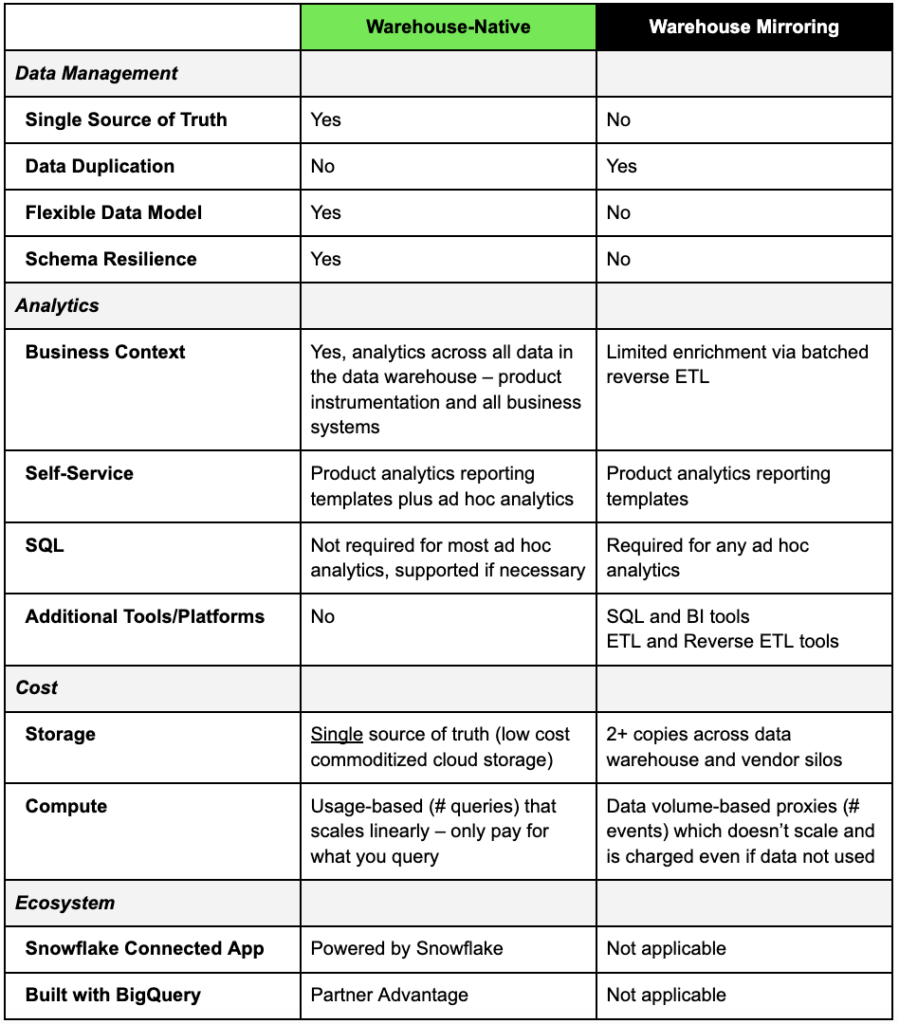
Lösningar för warehouse-native analytics som NetSpring utnyttjar en enda sanningskälla för konsekventa och tillförlitliga insikter. De kan ställa direkta frågor till både händelseorienterad användning och relationsreferensdata i datalagret för att få tillgång till alla relevanta kund- och beteendedata - utan att duplicera data. NetSpring fungerar till exempel med alla vanliga datalager i molnet, inklusive Snowflake®, Google BigQuery™, Redshift och Databricks, för att erbjuda självbetjänade produktanalyser och den utforskande kraften i BI för visuell datautforskning ad hoc.
Produktanalys via spegling av lager
Däremot är populära lösningar av första generationen, som Amplitude och Mixpanel, från tiden före Modern Data Stack och har egna datalager. Detta åtskilda tillvägagångssätt tvingar många företag att spegla eller omvänd ETL välja ut kund- eller affärsdata från datalagret tillbaka för begränsad berikning. Eftersom data dupliceras över analysplattformar är resultaten från första generationens verktyg i allmänhet inkonsekventa med analyser som körs direkt på datalagret.
Begränsningarna i de specialbyggda, förinställda produktanalysrapporterna tvingar många andra att exportera instrumentdata till datalagret. Med relevanta kund- och beteendedata (t.ex. utgifter, support, sociala medier etc.) berikade med produktanvändningsdata görs djupare analyser via SQL- och BI-verktyg för allmänt bruk, som Mode och Looker. Dessa dataexporter resulterar återigen i flera kopior av samma data och introducerar ytterligare analysverktyg som aldrig utformades för att hantera händelseorienterade data eller stödja produktanalys med självbetjäning.
Lagerspecifika lösningar kontra spegling av lager
När första generationens leverantörer framhåller sina lagerfunktioner hänvisar de till en export till ditt befintliga datalager och/eller omvänd ETL från lagret tillbaka in i sin åtskilda silo. I vissa fall kan leverantörerna till och med hänvisa till duplicering från ditt datalager till ännu ett datalager, deras eget! Kort sagt resulterar dessa exporter i två eller flera kopior av samma produktanvändningsdata!
Slutsatser
Framväxten av molnbaserade datalager som en mogen plattform för allmänna ändamål öppnar upp för ett brett spektrum av möjligheter för produktanalys.
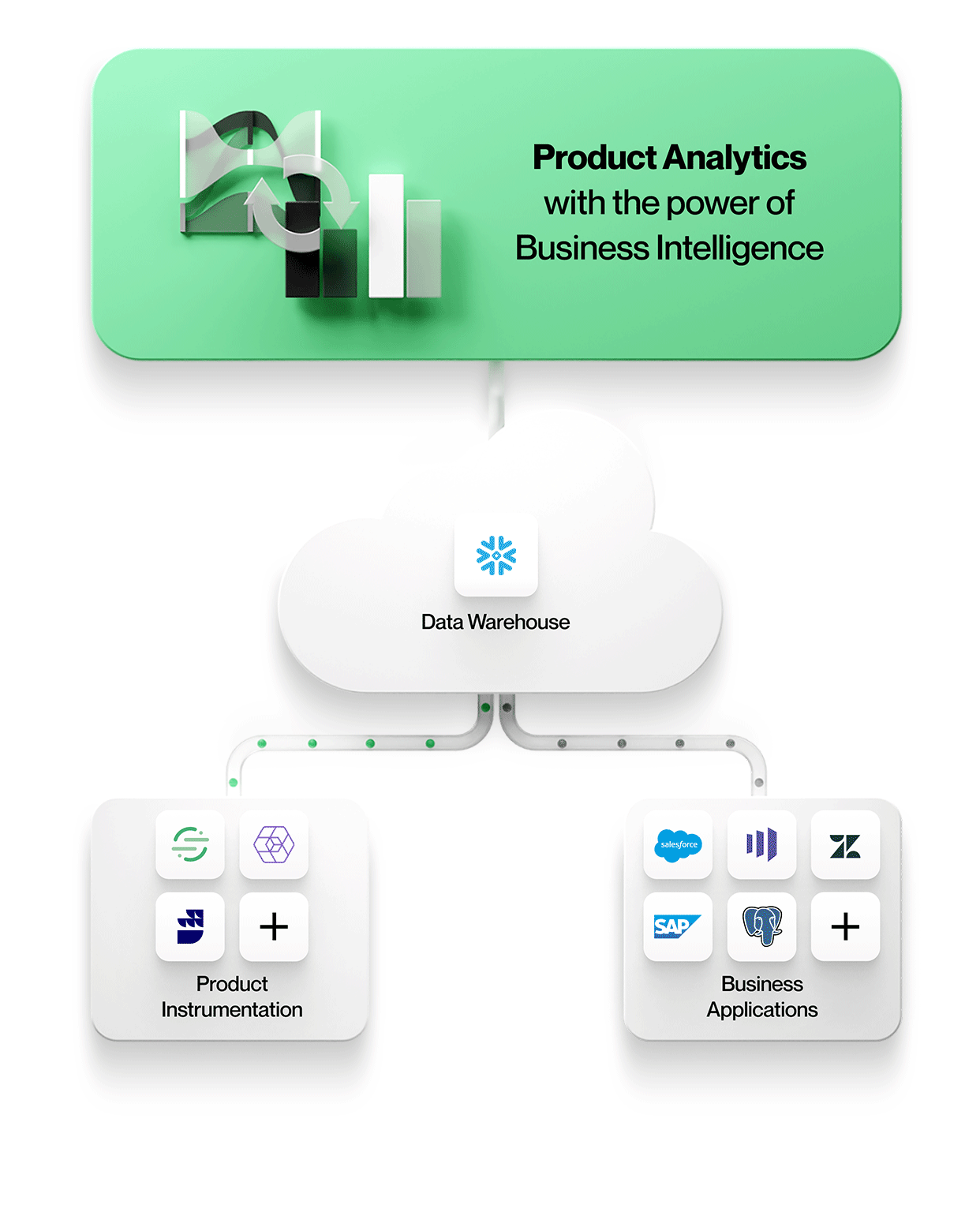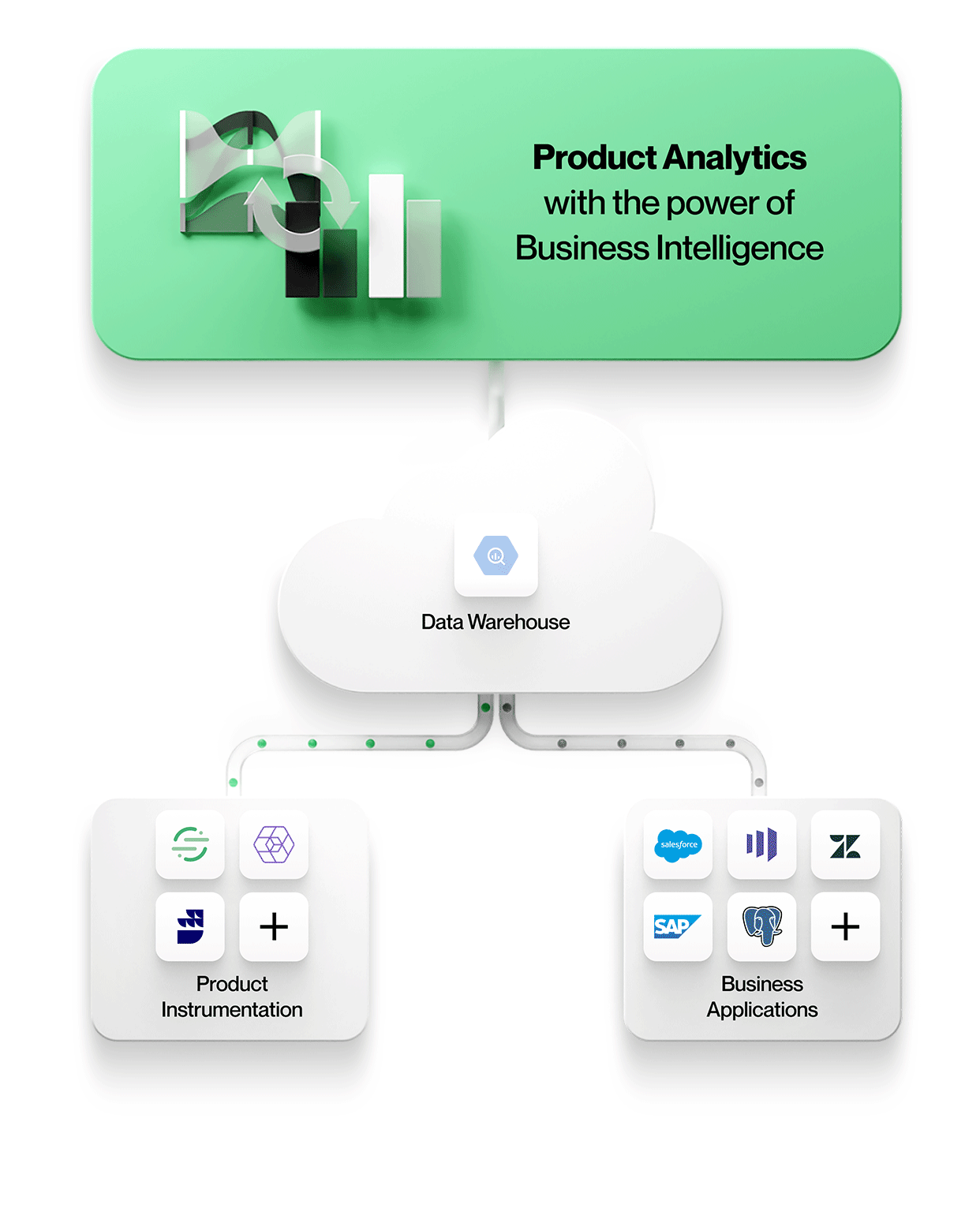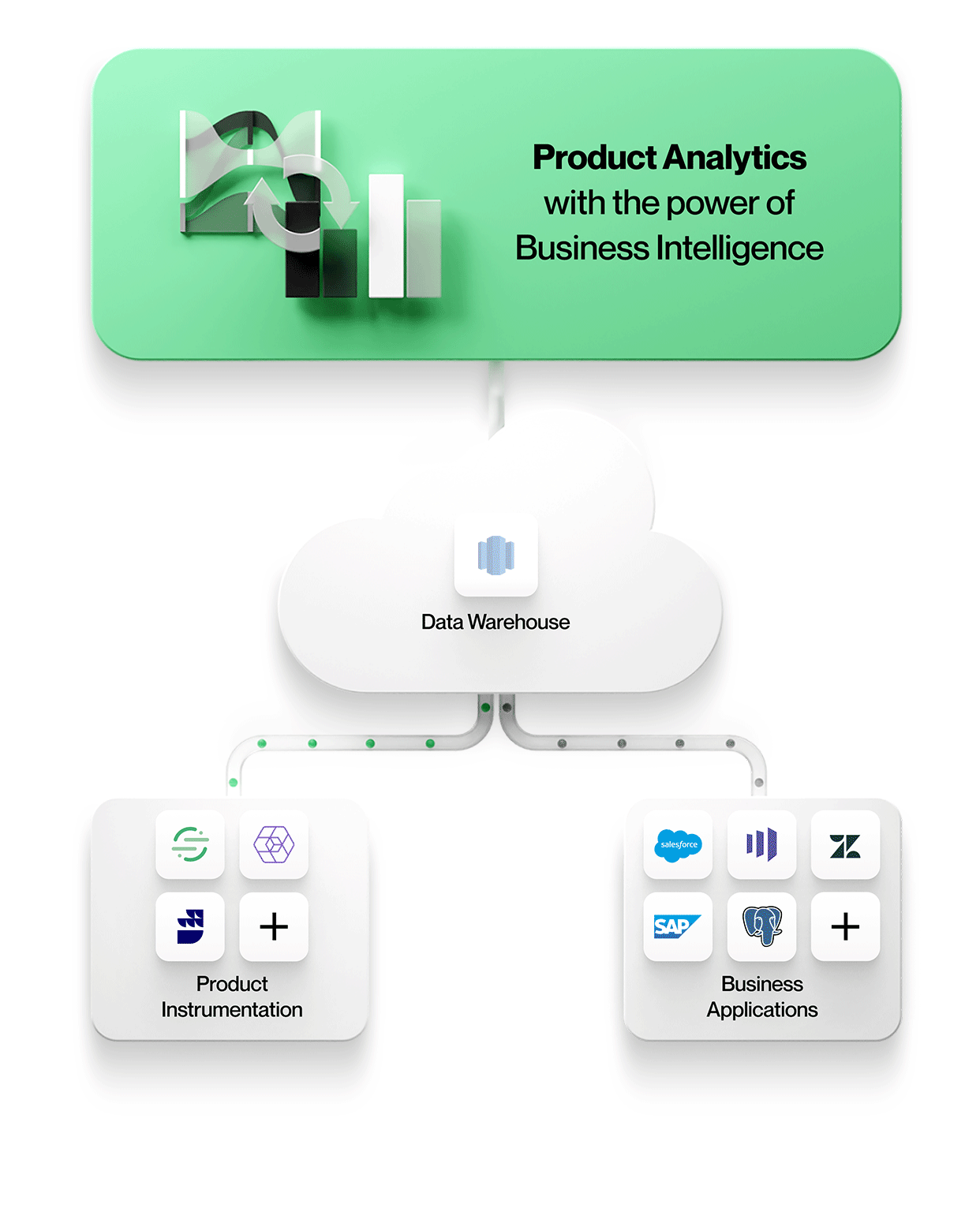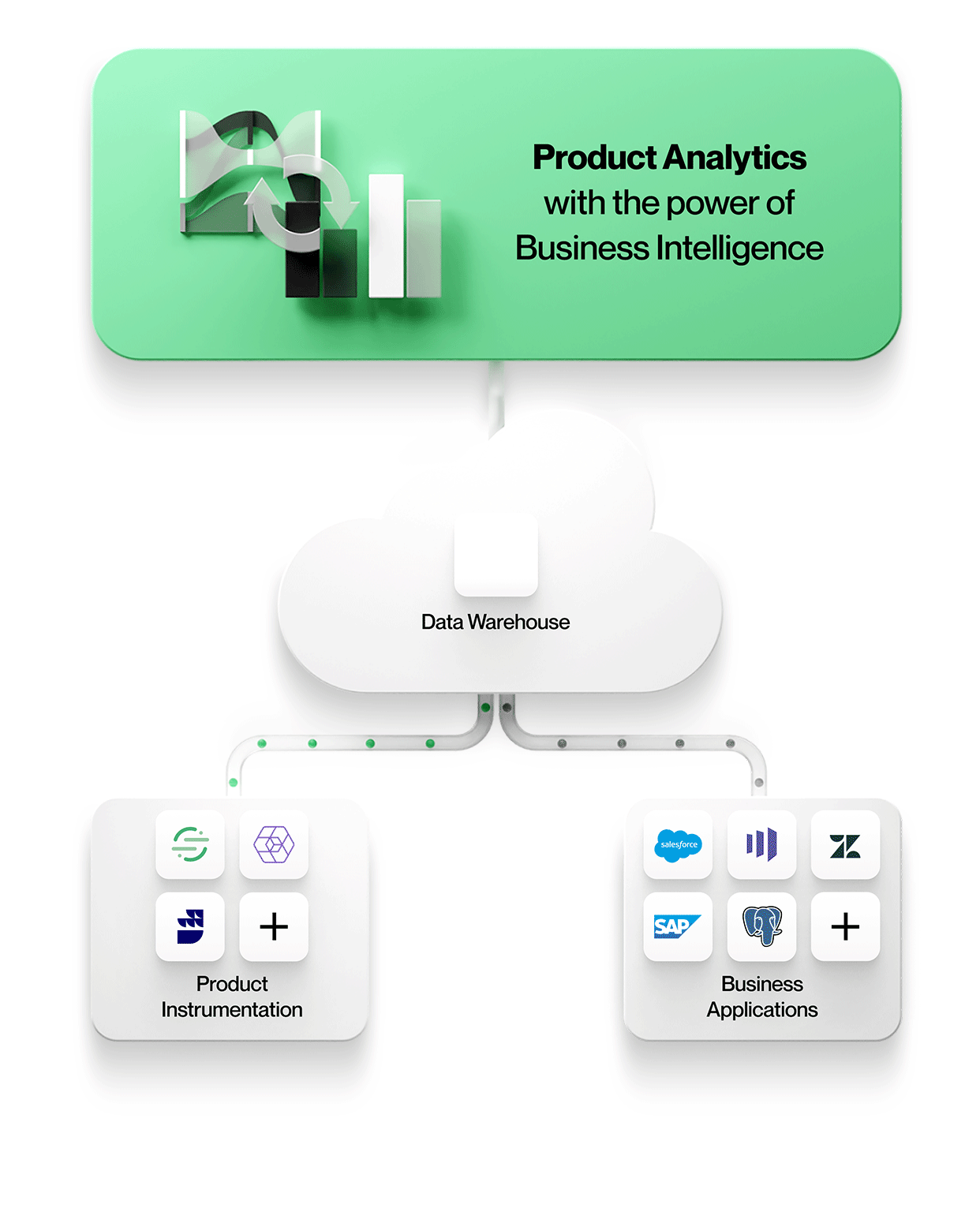
För det första kan åtskilda datalager undvikas när produktanvändningsdata lagras tillsammans med all annan företagsdata i ett säkert, reglerat lager. Där kan den nås av alla analysverktyg, oavsett om de är optimerade för händelseorienterad data, relationsdata eller, i bästa fall, både händelse- och relationsdata för kontextrik produktanalys av data i deras ursprungliga form.
Det innebär att man arbetar med enheter och deras relationer precis som de ser ut i affärsapplikationer, t.ex. konton, kontrakt, intäkter och leads från Salesforce eller ärenden, SLA:er och uppgifter från Zendesk. Produktanalys kan förstås i sitt sammanhang och korreleras med affärsresultat, vilket gör din analys mer värdefull och relevant för alla i organisationen.
Sammantaget resulterar denna moderna arkitektur för produktanalys i stora besparingar när det gäller lagring och beräkning, och högre affärseffekt från mer sofistikerade ad hoc-analyser. NetSpring erbjuder nästa generations produktanalys till en bråkdel av kostnaden för traditionella metoder, med produktanalys i självbetjäning och BI:s utforskande kraft, genom att arbeta direkt ovanpå ditt datalager.

- Last modified:2025-04-26 00:16:55