Produktanalytik + Data Warehouse: eine perfekte Kombination

Produktanalysetools der ersten Generation wie Mixpanel und Amplitude enthalten unter der Haube eine benutzerdefinierte Datenplattform zum Speichern und Analysieren von Produktinstrumentierungsdaten. Diese Plattformen behaupten, speziell für die Nutzungsmuster der Produktanalyse optimiert zu sein. Allerdings schränken sie die Möglichkeiten des Benutzers zur Ad-hoc-Exploration aufgrund der starren Modellierung, der begrenzten Abfragefunktionen und des fehlenden Kontexts stark ein.
Als jemand, der mehrere Datenbanken und Analyse-Engines für Millionen von Benutzern entwickelt hat (einige meiner Vorträge finden Sie unter Zusätzliche Ressourcen am Ende dieses Blogs), bin ich fest davon überzeugt:
Das moderne Cloud Data Warehouse kann Produktanalyse-Workloads genauso effizient bedienen wie jedes andere System, ohne Datensilos zu schaffen oder die Allgemeinheit von SQL zu opfern.
In diesem Beitrag werde ich die kritischen technischen Anforderungen an eine Produktanalyseanwendung auflisten und erläutern, warum Data Warehouses perfekt dafür geeignet sind, diese Herausforderungen zu meistern.
Produktanalytik - Ein extrem kurzer technischer Überblick
Bevor ich meine Argumente vortrage, lassen Sie uns eine kurze Auffrischung der Produktanalytik vornehmen.
Bei der Produktanalyse geht es um die Analyse von Produktnutzungs- und Leistungsdaten. Zu den Produktnutzungsdaten gehören Benutzeraktionen wie Klicks, Tastenanschläge und Anwendungsereignisse wie das Laden von Seiten, API-Fehler, langsame Anfragen usw. Diese Daten werden auch Ereignisdaten genannt. Ereignisdaten werden in der Regel in einem halbstrukturierten Format erfasst und zur weiteren Verarbeitung und Analyse an die Analyseplattform weitergeleitet.
{ "event_name": "checkout", "event_time": 1662313719000, // Millis seit Epoche für Sep 04, 2022 "user_id": "some_user" "property0": "wert®" "property1": "valuel" ... und so weiter ... }Es gibt drei grundlegende Eigenschaften, die in irgendeiner Form in allen Ereignissen vorhanden sind:
- event_name - Name des Ereignisses oder der Benutzeraktion
- event_time - Zeitpunkt, an dem das Ereignis eingetreten ist
- user_id - Kennung des Benutzers, der das Ereignis ausgelöst hat
Die Ereigniszeit fasst alle Ereignisse eines Benutzers zusammen, um eine globale Ordnung über alle Quellen für diesen Benutzer zu schaffen. Produktanalysetools aggregieren und visualisieren diesen Strom von Benutzeraktionen, geordnet nach event_time, um Verhalten, Engagement, Attribution, Treiber usw. zu verstehen.
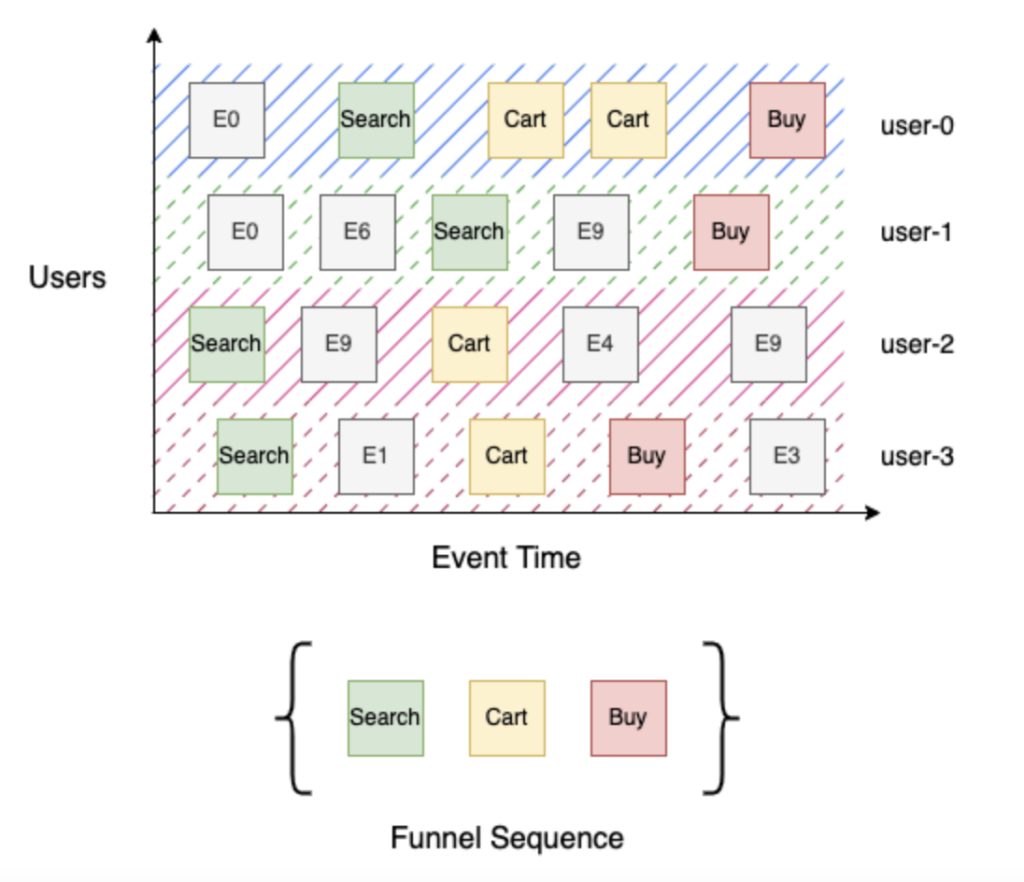
Betrachten wir einen einfachen 3-stufigen Trichter mit den Stufen Suchen, Einkaufswagen und Kaufen. Suche (Stufe 1) identifiziert alle Benutzer, die nach dem Produkt gesucht haben, Warenkorb (Stufe 2) identifiziert alle Benutzer, die nach einem Produkt gesucht und es in den Warenkorb gelegt haben, und schließlich Kauf (Stufe 3) identifiziert alle Benutzer, die nach einem Produkt gesucht, es in den Warenkorb gelegt und zur Kasse gegangen sind. Der Aufbau dieses Trichters ist einfach, wenn Sie einen nach Ereigniszeit sortierten Strom von Benutzerereignissen haben. Gehen Sie für jeden Benutzer die Abfolge der Ereignisse durch, um seinen Fortschritt durch den Trichter zu verfolgen, und aggregieren Sie dann die einzelnen Benutzer nach Stufe. Im obigen Beispiel haben "user-0" und "user-3" den Schritt zum Kauf (Stufe 3) gemacht, "user-1" hat die Suche (Stufe 1) erreicht, da es kein Warenkorb-Ereignis in seinem Ereignisstrom gibt, und "user-2" hat den Warenkorb (Stufe 2) erreicht.
Was macht die Produktanalyse so schwierig?
Extreme Skalierung
Produktnutzungsdaten können extrem umfangreich sein. Sie werden bei jeder Benutzerinteraktion mit dem Produkt erzeugt und sind in der Regel denormalisiert und extrem reich an kontextbezogenen Attributen. Außerdem wachsen diese Daten im Laufe der Zeit mit zunehmender Produktnutzung. Stellen Sie sich nur einmal die Anzahl der täglichen Interaktionen (Klicks, Berührungen, Tastenanschläge usw.) vor, die Sie mit Ihrem Lieblingsprodukt haben, und multiplizieren Sie diese Zahl mit der Anzahl der Benutzer, die es verwenden! Diese umfangreichen Daten müssen für eine sekundengenaue Analyse effizient gespeichert und abgerufen werden.
Abfragen von Ereignisfolgen
Die Berechnungen für die Produktanalyse sind im Allgemeinen wesentlich komplexer als die traditionellen Slice-and-Dice-Abfragen, die für Business Intelligence-Tools wie Tableau und Looker typisch sind. Wie in der obigen Einführung erläutert, müssen die Berechnungen eine Abfolge von Ereignissen verfolgen, um das Benutzerverhalten zu verstehen. Das System muss bei dieser Kombination aus hoher Komplexität und Skalierung effizient sein. Die interaktive Leistung ist für jede Self-Service-Produktanalyselösung entscheidend, damit der Endbenutzer die Daten erkunden und schnell zu wertvollen Erkenntnissen gelangen kann.
Datenaufnahme in Echtzeit
Produktteams benötigen einen schnellen Einblick in die Produktnutzungsdaten, um eine schnelle Iteration von Produktfunktionen zu ermöglichen, insbesondere bei Markteinführungen oder zur Unterstützung von Experimenten. Produktnutzungsdaten werden kontinuierlich generiert und müssen innerhalb von Minuten für die Analyse verfügbar sein. Oft wird der Großteil der Daten in kurzen Schüben erzeugt, die sich nach externen Ereignissen oder der Tageszeit richten. Das System muss diese mit Zeitstempeln versehenen Ereignisdaten schnell und dauerhaft aufnehmen und sie auf einem dauerhaften Speicher organisieren und indizieren, um eine effiziente Echtzeitabfrage zu ermöglichen.
Kontinuierlich sich entwickelndes Schema
Produktnutzungsdaten können mit kontextspezifischen Attributen versehen werden, um die Analyse zu erleichtern. Diese Annotationen müssen nicht im Voraus deklariert werden, sondern werden je nach Bedarf bei sich ändernden Anforderungen hinzugefügt. So kann der Benutzer z.B. beschließen, das Kaufereignis im Beispiel des Trichters mit dem Gesamtpreis zu versehen und nur Ereignisse mit einem Gesamtpreis von mehr als $5 zu berücksichtigen. Einfach ausgedrückt: Ereignisdaten haben keine vordefinierte Struktur oder ein vordefiniertes Schema und entwickeln sich mit den sich ändernden Produktanforderungen ständig weiter.
Data Warehouse als Retter in der Not
Die Entwicklung einer Plattform für die Produktanalyse ist zweifellos ein schwieriges Systemproblem. Glücklicherweise arbeitet die Datenbankforschungsgemeinschaft seit Jahrzehnten aktiv an den oben genannten Problembereichen.
Moderne Data Warehouses nutzen verschiedene innovative Techniken, um eine kosteneffiziente Leistung bei der Skalierung von Produktanalysen zu erzielen.
In diesem Abschnitt führe ich einige wichtige Designdetails für Data Warehouses auf, die die oben genannten Herausforderungen angehen.
Spaltenbasierte Speicherung: Im Gegensatz zu zeilenbasierten Speicherformaten wird bei der spaltenbasierten Speicherung die Anzahl der von einer Abfrage berührten Bytes minimiert, indem nur auf die Daten der erforderlichen Spalten zugegriffen wird. Analytische Datenbanken haben bereits in den 1970er Jahren mit der spaltenbasierten Speicherung experimentiert. Das Papier "C-Store" von Stonebreaker et al., 2005, zeigte erhebliche Leistungsverbesserungen für analytische Arbeitslasten. Alle analytischen Systeme verwenden heute spaltenbasierte Speicher für eine verbesserte Leistung.
Effiziente Komprimierung für Zeitreihendaten: Im Laufe der Zeit wurde eine Vielzahl von Techniken zur Datenkomprimierung in Datenbanken entwickelt, um Kosten zu senken und die Leistung zu verbessern. Neben der Implementierung aller bekannten grundlegenden Algorithmen wie Wörterbuchkodierung, RLE- und LZW-Varianten, Delta-Kodierung usw. investieren Lagerhäuser kontinuierlich in diesen Bereich, um Innovationen hervorzubringen - Google veröffentlichte das Capacitor-Format, das die Spaltenanordnung für eine bessere Kompressionsrate beschreibt, Gorilla Paper von Pelkonen et al., 2015 von Facebook beschreibt ein Kompressionsschema für Zeitreihendaten. Die meisten dieser Techniken werden heute von allen großen Data Warehouse-Anbietern eingesetzt.
Massiv parallele Verarbeitung: Verteilte Datenbanken verteilen die Verarbeitung auf eine Reihe von Rechenknoten, wo die Verarbeitung parallel erfolgt und die Ausgaben der einzelnen Knoten schließlich zu einem endgültigen Ergebnissatz zusammengeführt werden. Götz Graffe schlug in seinem "Volcano"-Papier Modelle zur Parallelisierung der Arbeit in SQL-Ausführungsmaschinen über Threads und Knoten hinweg vor. Systeme wie Teradata und Netezza leisteten Pionierarbeit bei dem Ansatz, so viel Arbeit wie möglich so früh wie möglich zu parallelisieren und machten den Begriff MPP populär. Heute verarbeiten reife Datenbanken mit dieser Architektur Terabytes an Daten in Sekundenschnelle.
Geclustertes Datenlayout: Ein geclusterter Index wird in Datenbanken schon seit langem verwendet, um verschiedene relationale Operationen wie Sortieren, Aggregieren, Verbinden usw. zu beschleunigen. Dies ist besonders nützlich für die Analyse von Ereignisfolgen, um Abfragen zu beschleunigen, indem die Ereignisdaten in der Reihenfolge der Ereigniszeit vorsortiert werden. Die meisten großen Data Warehouses, darunter Snowflake (Daten-Clustering), BigQuery (geclusterte Tabellen), Redshift (Sortierschlüssel) und SQL Server (geclusterte und nicht geclusterte Indizes) ermöglichen benutzerdefiniertes Clustering zur Leistungsoptimierung.
Vektorisierung oder JIT: Datenbankimplementierungen sind stark optimiert und streben für jede Abfrage eine Leistung an, die der von Hand geschriebener Programme nahe kommt. Es gibt zwei weithin bekannte Techniken, die eine solche Leistung ermöglichen - die Vektorisierung, bei der Vectorwise Pionierarbeit geleistet hat, und die JIT-Codegenerierung, bei der HyPer Pionierarbeit geleistet hat. Beide Ideen werden ausgiebig erforscht, wobei die meisten modernen Implementierungen einige Ideen aus beiden Paradigmen verwenden (siehe Zusätzliche Ressourcen unten für meinen Vortrag in diesem Bereich).
Fensterfunktion für Ereignisabläufe: Die 2003 zu SQL hinzugefügten Window Functions (oder Analytic Functions) ermöglichen die meisten Abfragemuster für Zeitreihendaten, die den Zugriff auf benachbarte Zeilen erfordern. Seitdem ist die Verwendung dieses Operators in allen Data Warehouses allgegenwärtig, was dazu geführt hat, dass seine Implementierung intensiv erforscht und optimiert wurde - z.B. "Efficient Processing of Window Functions" von Leis et al., 2015 und"Incremental Computation of Common Windowed Holistic Aggregates" von Wesley et al., 2016. Produktanalytische Tools können Fensterfunktionen für die Abfrage von Ereignisfolgen umfassend nutzen. Dies ist ein Bereich, der reif für Innovationen ist. Ich werde in späteren Beiträgen mehr Details dazu liefern.
Semi-strukturierte Typen: Mit kontextspezifischen Attributen versehen, die nicht im Voraus deklariert werden müssen, sondern je nach Bedarf bei sich ändernden Anforderungen hinzugefügt werden. So kann der Endbenutzer z.B. beschließen, das Ereignis "Kaufen" im obigen Trichter-Beispiel mit dem Kaufpreis zu versehen und nur Ereignisse mit einem Preis von mehr als 5 $ aufzunehmen. Ereignisdaten haben keine vordefinierte Struktur oder ein Schema. Sie entwickeln sich ständig mit den sich ändernden Anforderungen weiter. Im Jahr 2010 veröffentlichte Google das "Dremel"-Papier, in dem ein Speicherformat für interaktive Ad-hoc-Daten auf verschachtelten halbstrukturierten Daten beschrieben wurde. Dieses Papier wurde zur Grundlage für das bekannte Apache Drill-Projekt. Heute nutzen alle großen Cloud-Data-Warehouses die Ideen dieses Papiers, um JSON und ähnliche verschachtelte Typen mit minimalen Leistungseinbußen zu unterstützen.
Verarbeitung und Ingest in Echtzeit: Systeme wie Druid und Pinot haben vor kurzem die Echtzeit-Ingestion unter Verwendung der Lambda-Architektur populär gemacht. Die Kappa-Architektur, wie sie von Flink und Spark verwendet wird, hat die Streaming-Ingestion weiter vereinfacht und wurde von den meisten modernen Data Warehouses übernommen. BigQuery verfügt über eine Streaming-Storage-Write-API, die Ingest mit hohem Durchsatz (~10 GB/Sek.) bei einer Aktualisierungslatenz von 2-3 Minuten ermöglicht. In ähnlicher Weise lässt sich Redshift mit Amazon Kinesis Data Firehose integrieren, um Daten aufzunehmen und in weniger als einer Minute live zu schalten. Snowpipe verwaltet den kontinuierlichen Dateningest in Snowflake mit einer Datenfrische von ein paar Minuten für Szenarien mit hohem Durchsatz.
Fazit
Cloud Data Warehouses sind in den letzten zehn Jahren nicht nur auf dem Vormarsch, sondern regelrecht explodiert. Im Jahr 2010, als Mixpanel und Amplitude gegründet wurden, mag es sinnvoll gewesen sein, eine eigene Plattform zu entwickeln, aber diese Architektur ist heute überholt.
Mit Optimizely Warehouse-Native Analytics sind wir der Meinung, dass die Verwendung eines Data Warehouse für die Ausführung von Produktanalyseabfragen nicht nur leistungsfähig und kostengünstig ist, sondern auch neue Arten von Analysen ermöglicht, die mit bestehenden Produktanalysetools nicht möglich sind, wie z. B. die Anreicherung von Benutzerereignisdaten mit dem Geschäftskontext in Salesforce, die Kombination mehrerer Ereignisquellen zum besseren Verständnis der Produktnutzung usw.
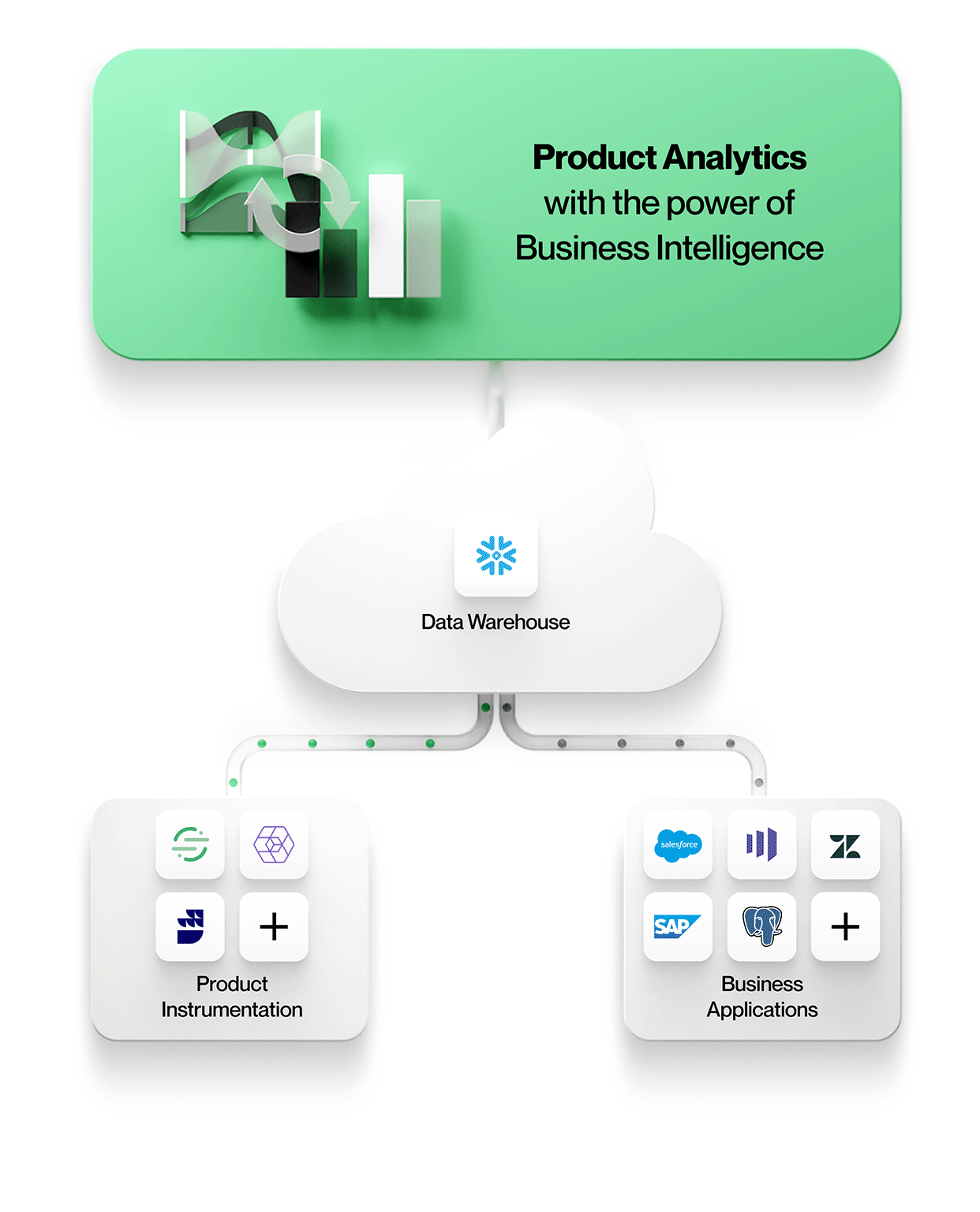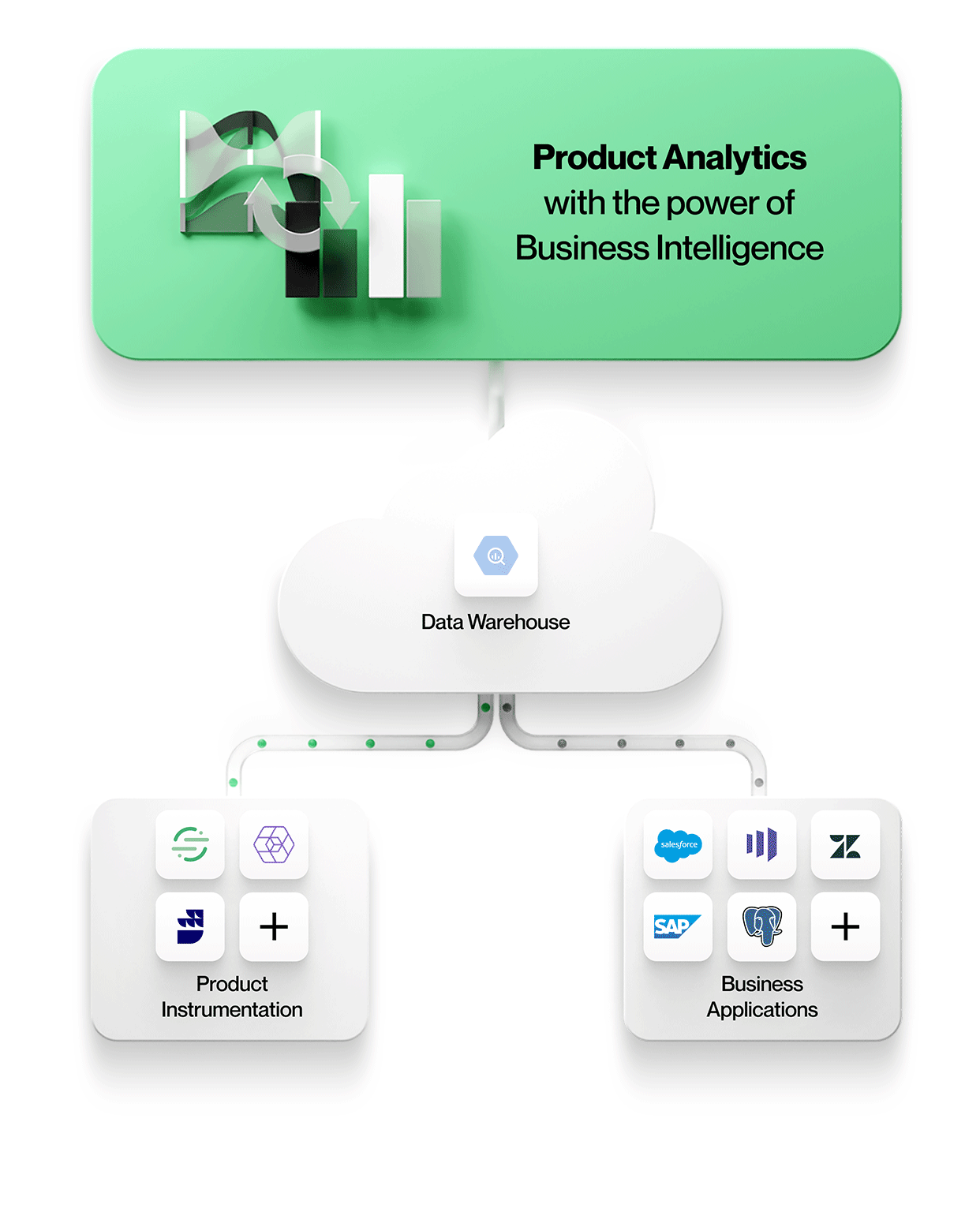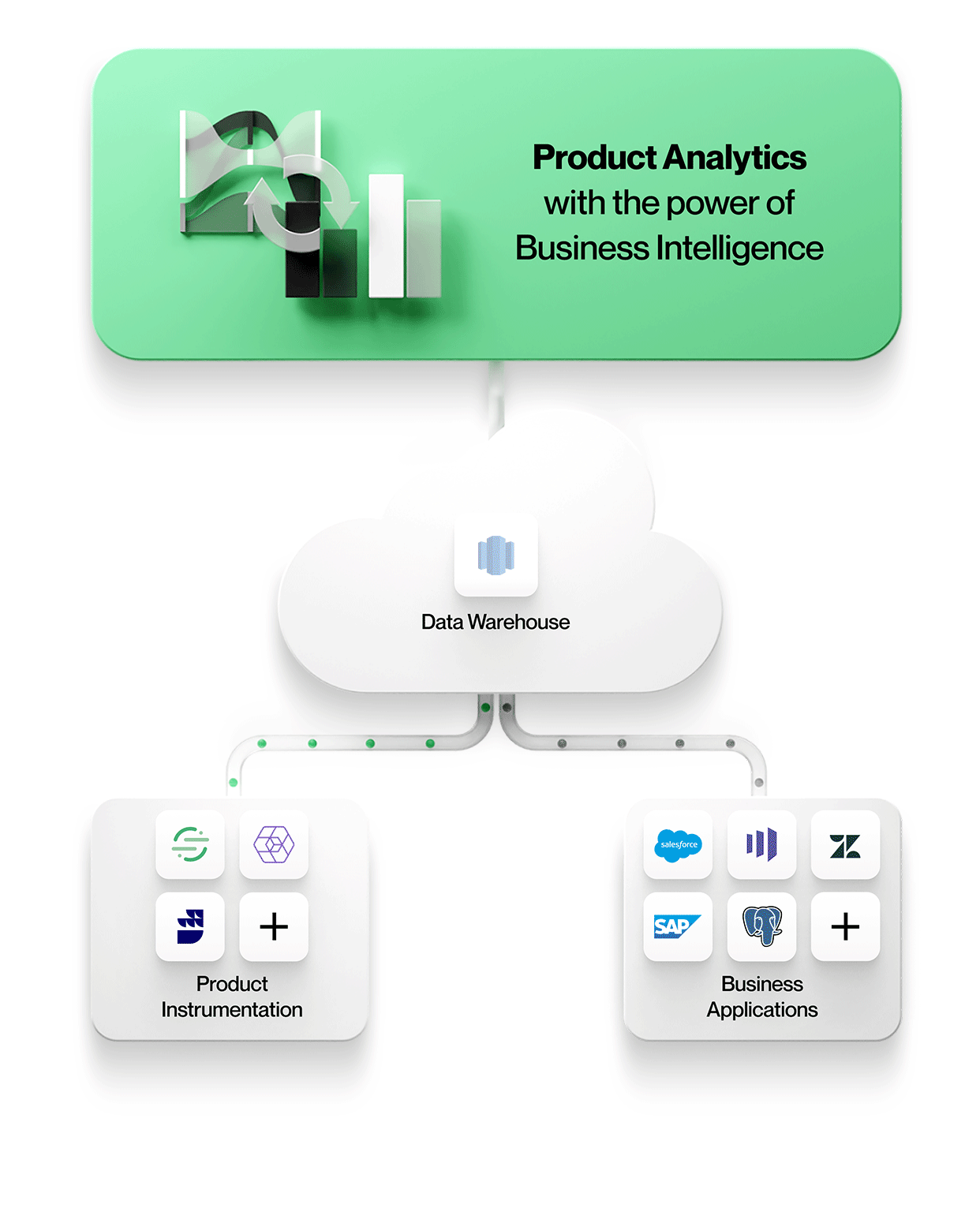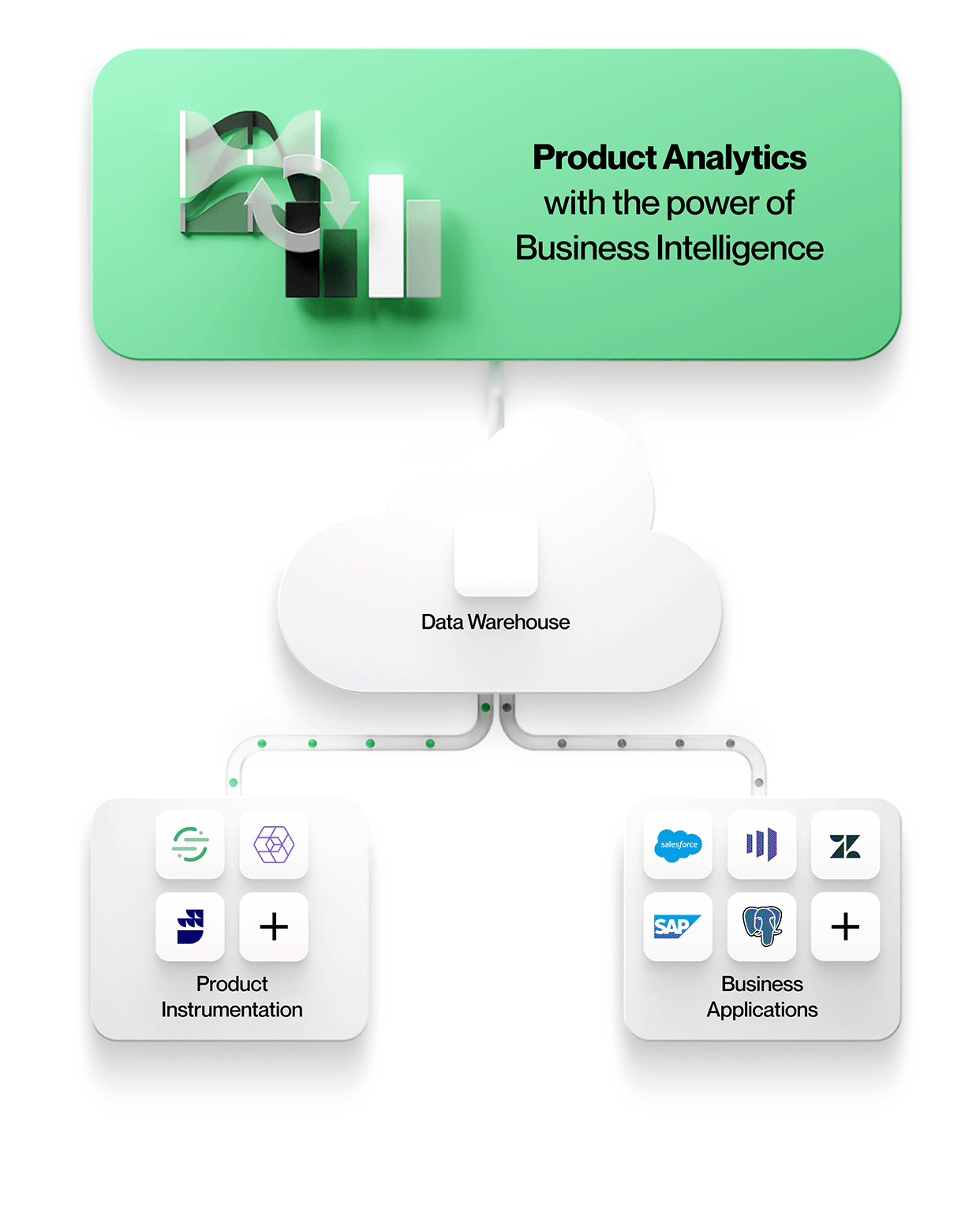
Optimizely Warehouse-Native Analytics kann mit allen wichtigen Cloud-Data-Warehouse-Anbietern verbunden werden, darunter Snowflake®, Google BigQuery™, Amazon Redshift und Databricks, um ein erstklassiges Erlebnis für die Produktanalyse zu bieten, indem die besten Lösungen für jeden Workflow verwendet werden.

- Zuletzt geändert: 21.04.2025 18:09:26