Spør eksperimenteksperten: Slutt å bruke inntekter som det primære måleinstrumentet

Når vi jobber med kundene våre for å hjelpe dem med å forstå resultatene og læringen fra et eksperiment, er et av de viktigste spørsmålene vi får: "Hvorfor oppnår jeg ikke signifikans?" eller, mer spesifikt, "Hvorfor er dette eksperimentet ikke konklusivt?" Når jeg hører dette spørsmålet, er min første sjekk å se på hvilke beregninger som er angitt i Optimizely for å måle suksessen til et eksperiment. Og viktigst av alt, hva er angitt som den primære suksessindikatoren? Denne primære målingen er ment å være den målingen som vektes tyngst blant de andre eksperimentmålingene for å erklære et eksperiment som en vinner. Dette er ikke annerledes enn de fleste forretningsbeslutninger! En ledende måleindikator med støtte fra de riktige måleindikatorene.
Arbeidet med å finne avgjørende resultater starter lenge før du setter i gang med eksperimentet. Det starter før du gjør en resultatanalyse. Det starter før du utformer testen. Det starter når du identifiserer hvilke måltall du kan påvirke gjennom eksperimenter, og når du forstår hvordan disse måltallene samvirker med hverandre.
For kundetilfredshet er inntekter, høyere retensjonsrate og endelig(e) konvertering(er) de nøkkelindikatorene (KPI-er) som er i fokus for å forbedre gjennom eksperimentering. Men andre måltall kan (og bør) være i fokus for individuelle eksperimenter, avhengig av hvilket kundeproblem du ønsker å løse. Måleindikatorene under de viktigste KPI-ene kan også være de som ligger nærmest der du eksperimenterer. Det er disse indikatorene du med størst sikkerhet kan måle og forbedre for det enkelte eksperimentet. Hvis du flytter nålen på disse atferdene, vil det ha en nedstrøms innvirkning på de viktigste KPI-ene.
Hvis du bare fokuserer på inntekter som det primære målet for alle eksperimenter på kort sikt, vil du garantert gå glipp av gevinster, lærdom og muligheter til å iterere for å påvirke inntektene. Du vil utvilsomt ta beslutninger og kalle eksperimenter mislykkede, selv om de faktisk har en positiv innvirkning på brukeratferden og samtidig påvirker inntektene på lang sikt. Hvis du ikke setter opp eksperimentene dine på riktig måte for å avdekke effekten av denne atferden, går du også glipp av å lære hva som påvirker inntektene.
Men vent litt. Vi bryr oss bare om å øke inntektene fra a/b-testing. Hvorfor skulle vi ikke måle suksess etter inntekter?
Du bør måle inntektene! Faktisk bør du måle den for hvert eksperiment som et sekundært mål hvis det er viktig for virksomheten din! Og bruk det i balanse med andre beregninger for å bestemme suksess. Det du imidlertid ikke kan kontrollere for hvert eksperiment, er hvilken innvirkning det vil ha direkte på inntektene og kundens livstidsverdi.
Definisjonen av måleparametere for et individuelt eksperiment bør passe inn i disse tre kategoriene:
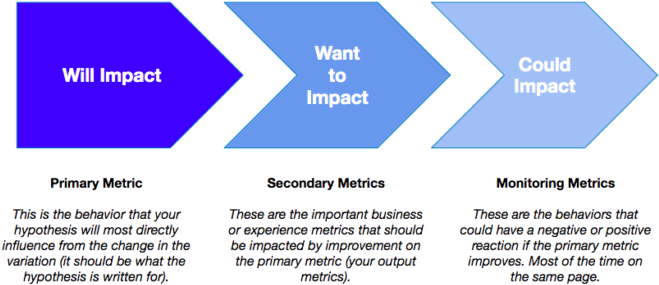
La oss tenke oss at du har sett fallende engasjement, gjennomsnittlig bestillingsverdi og et lavere antall aktive brukere på hjemmesiden din, noe som er et problem fordi det er hovedinngangen til e-handelsnettstedet ditt. En hypotese du har, kan være
"Hvis produktmarkedsføringsteamet vårt bruker en karusell i stedet for et statisk heltebilde, vil vi øke antall kjøp fordi vi gir brukerne flere tilbud og produktmeldinger nårdekommer inn på siden.
Du må tenke på at det er mange trinn/budskap/atferd og andre påvirkninger (også utenfor nettstedet ditt!) som skjer for brukerne mellom denne endringen og den endelige konverteringen, og som du ikke kontrollerer for. Det kan for eksempel være en reklamekampanje som har ført til at en bruker har kommet til hjemmesiden, og som senere har ført til at flere brukere ikke konverterer på grunn av uoverensstemmende meldinger senere i kjøpsforløpet.
Poenget er at den primære målingen (og hovedmålingen i hypotesen) alltid bør være den atferden som ligger nærmest den endringen du gjør i den variasjonen du benytter. Hypotesen bør egentlig lyde som følger:
"Hvis vi bruker en karusell i stedet for et statisk heltebilde, vil vi øke antall klikk på heltebildet og antall visninger av produktsiden fordi vi gir brukerne flere tilbud og et nytt produktbudskap når de kommer inn på siden.
La oss nå se for oss et annet scenario. Du har optimalisert den øverste delen av e-handelstrakten din godt. Men du sliter nå i kassen. Hypotesen din er
"Hvis vi kollapset skjemafeltseksjoner på betalingssiden, vil vi øke kjøpene fordi vi presenterer en indikasjon på all informasjonen vi vil kreve fra brukerne over oversikten fra seksjonstitlene.
Dette stemmer godt overens med flytdiagrammet over! Siden vi eksperimenterer på det siste trinnet (det eneste formålet med den siden er å konvertere brukere), er det fornuftig å bruke kjøp eller inntekter som den primære målingen. Det er den atferden du mest sannsynlig vil påvirke med endringene du gjør i variasjonen.
Men bør vi ikke forvente å se en innvirkning på inntektene når det gjelder eksperimentene våre lenger opp i trakten (de som er lenger unna kjøp eller den endelige konverteringen)?
"Bør" er kanskje ikke det rette ordet. Vi håper alltid at inntektene vil bli påvirket av de prioriterte eksperimentene dine. Det må bare være en forståelse for at du kanskje ikke kan måle direkte innvirkning på inntektene for hvert eksperiment.
Men hvis du kan utvikle de atferdene som fører brukerne nærmere den endelige konverteringen som gir inntekter, påvirker du inntektene. Hvis du måler de ledende atferdene først og gjør statistisk signifikante forbedringer på disse, kan du fortsette å flytte fokuset til eksperimenter som er nærmere inntektene.
Det gir god mening. Men igjen. INNTEKTER, INNTEKTER, INNTEKTER.
Greit nok. Det ovennevnte er konseptuelt. Men vi så på tvers av alle kundeeksperimenter og så faktisk at dette var sant! Vi fant ut at når månedlig tilbakevendende inntekt er satt som primærmåling i Optimizely, nådde den prosjektets statistiske signifikansnivå bare 10 % av tiden, sammenlignet med når alle andre måltyper (sidevisningshendelser, klikkhendelser, egendefinerte hendelser) er satt som primærmåling. Selv om vi ønsker å maksimere inntektene i eksperimentene våre, har vi ikke alltid full kontroll over dem i alle eksperimenter, og eksperimentdataene underbygger dette.
De beste programmene måler inntekter og andre viktige måltall for hvert eksperiment for å forstå den inkrementelle effekten eksperimentet har på disse viktige KPI-ene.
Hvordan bør du avveie de primære og sekundære måleparameterne for å avgjøre hvor vellykket det enkelte eksperimentet er?
En god praksis i planleggingen av testene er å diskutere i gruppen hvilke avveininger dere er villige til å gjøre mellom det totale antallet primære og sekundære måleparametere - i dette tilfellet inntekter. Det har vært interessant å oppdage at dette varierer fra bransje til bransje. Noen programmer anser en statistisk signifikant forbedring av den primære måleparameteren som den eneste suksessfaktoren for et eksperiment. Noen programmer krever at det må være en statistisk signifikant forbedring i sekundære måleparametere (f.eks. omsetning, kjøp) for at et eksperiment skal anses som en seier.
Du kan sette opp et beslutningsrammeverk på forhånd for et eksperiment (eller for programmet som helhet) for å skape konsensus om hvordan disse scenariene skal håndteres. Dette rammeverket kan endres over tid, men det kan gjøre det raskere å ta beslutninger og iverksette tiltak basert på resultatene. Vi anbefaler å bruke dette så ofte som det er debatter om suksesskriterier!
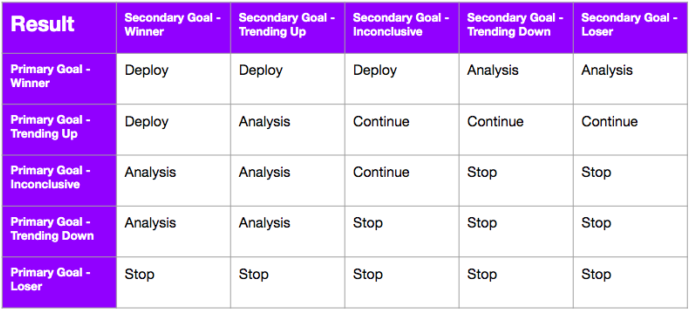
Det er to viktige deler i et best-in-class-beslutningsrammeverk: Det har et rimelig delta for innvirkning på inntektene OG enten aksepterer eller avviser at det er nødvendig med en statistisk signifikant gevinst på det primære måltallet. Dette kan være et delta som har både positive og negative grenser. Det er her Optimizelys konfidensintervaller kommer til nytte. Ved å bruke konfidensintervallene på resultatsiden i Optimizely får du en klar indikasjon på hvor den "sanne forbedringen" vil ligge i inntektene hvis du implementerer vinneren. Sørg for at intervallet ikke utvides basert på det rimelige deltaet ditt.
Hvilke andre måter kan vi måle suksessen til programmet vårt på?
Den mest oversette delen av et eksperimenteringsprogram er målingen som pålegges seg selv. Vi kaller disse målingene for "driftsmålinger", og disse ser på det samlede programmet kontra de spesifikke testene. Disse virksomhetsmålene er atferd som vi vet er sterke indikatorer på et sunt program. Hvis vi mener at metodikken vår er god og i sin tur genererer læring som gir oss bedre kunnskap om eksisterende og nye kunder, er denne typen beregninger gode indikatorer på suksess:
- Hastighet - Antall eksperimenter som startes per uke, måned, kvartal osv.
- Konklusjonsrate - prosentandelen av eksperimenter som når en statistisk signifikant tilstand.
- Win Rate - prosentandelen eksperimenter som oppnår et positivt statistisk signifikant resultat.
- Læringsrate - Prosentandelen av eksperimenter som skapte læring som kan brukes til handling.
- Gjenbrukbarhet - Andelen eksperimenter som bidrar til andre initiativer og forretningsmål.
- Iterasjonsrate - Andelen eksperimenter som blir iterert som et neste steg.
Det finnes mange andre operasjonelle nøkkeltall du kan finne på, og disse kan suppleres med alle metadata du har om programmet (f.eks. type variasjonsstrategi, idékilde osv.) for å illustrere hvilken innvirkning programmet har på virksomheten i løpet av en tidsperiode.
Husk at hvert eksperiment er forskjellig!
Alle eksperimenter er forskjellige! Det er ikke sikkert at du følger disse prinsippene til punkt og prikke, men programmet ditt bør ha et sterkt og konsekvent syn på hvordan du skal definere primære måleparametere for å få en bedre forståelse av eksperimentets resultater og læring. Fortell oss hvordan du kan tilnærme deg dette på en annen måte, hva du har sett som en suksess når det gjelder å definere eksperimentets måleparametere, og hvordan du har analysert inntektseffekten!

Lead Strategy Consultant - Alek var tidligere kunde hos Optimizely, og ledet American Medical Associations digitale analyseteam og optimaliseringsprogram. I dag...
- Last modified:25.04.2025 21:15:04