
Du er en produktstyrt virksomhet som ekspanderer raskt. Forretningsmetoden din er produktstyrt vekst (PLG), der brukeranskaffelse, konvertering, engasjement, oppbevaring og ekspansjon er produktstyrt. Som et resultat av dette ønsker både produkt-, vekst-, markedsførings-, salgs- og suksessorganisasjonene mer produkt- og kundeanalyse for å forstå og påvirke de viktigste drivkreftene bak forretningsmålene.
Teamet ditt har fått i oppgave å utarbeide en analysestrategi for bedriften - hvilken arkitektur og hvilke verktøy som skal tas i bruk. Skal dere bygge internt eller kjøpe fra eksterne leverandører? Denne bloggen tar for seg det moderne arkitekturmønsteret som bør brukes, og fordeler og ulemper ved å bygge og kjøpe verktøy for produktanalyse.
Analytics-arkitektur
Følgende prinsipper er sentrale i arkitekturen til en moderne dataanalysestack:
- Sentralt datavarehus: Datavarehuset er det sentrale lageret for alle data, inkludert produktinstrumentasjonsdata og data fra forretningssystemer.
- ELT (Extract, Load, Transform): Bruk av ELT i motsetning til ETL. Datatransformasjoner skjer i lageret ved hjelp av lagersentriske verktøy som DBT. Rådata, for eksempel hendelsesdata, lagres i lageret i opprinnelig form og er tilgjengelig for bruk i rå eller transformert form, avhengig av hva kunden har behov for. Ingen data forsvinner eller mister datafidelitet.
- Frakoblet instrumentering: SDK-er og biblioteker for produktinstrumentering er frikoblet fra analyseverktøyene. Bruk av de beste verktøyene i klassen, som Segment, Snowplow og Rudderstack, for å instrumentere produkter og apper, og lagre dataene direkte i bedriftens sentrale datavarehus. Disse dataene er i et åpent format, lagret i kjente relasjonsmodeller i lageret, som alle analyseverktøy enkelt kan bruke.
- Warehouse-innfødte analyser: Alle analyseverktøy bør koble seg til lageret og arbeide direkte med disse dataene. Ingen data skal kopieres ut av det sentrale datalageret - noe som er kritisk av hensyn til kostnader, sikkerhet, styring, nøyaktighet og håndterbarhet.
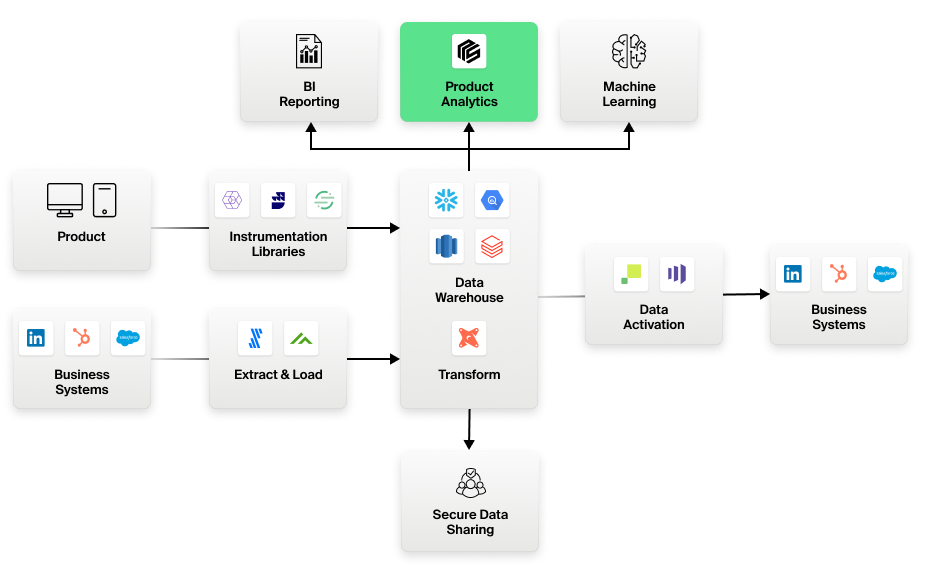
Figur 1: Den moderne datastakken for analyse
Bygge kontra kjøpe
Hvis vi antar at du abonnerer på de arkitektoniske mønstrene som er beskrevet ovenfor, kan vi se nærmere på hvordan "build versus buy" ser ut for produktanalyse. Her er noen scenarier du kanskje har tenkt på:
Bygg Scenario 1:
Jeg innser at produktanalyse er veldig spesialisert. Men vi er et teknisk kunnskapsrikt selskap som bygger komplekse produkter. Vi kan bygge et produktanalyseverktøy selv.
Fordeler
- Full kontroll over verktøyet som kan skreddersys etter bedriftens behov.
- Ingen ekstra kostnader for lisensiering av eksterne produkter.
- Ingen problemer med sikkerhet eller samsvar med dataflytting eller bruk av eksterne SaaS-tjenester.
Ulemper
- Massiv investering med et stort team for å bygge et så spesialisert og komplekst verktøy. Kan koste mange ganger mer enn å lisensiere et produkt som utelukkende fokuserer på analyse.
- Risiko for at produktet forfaller og at investeringene går tapt hvis sentrale medlemmer av dette teamet forlater selskapet.
- Tapt mulighet til å bruke investeringen i produktanalyseverktøyet andre steder der det kan være mer sentralt for virksomheten.
Byggescenario 2:
Dataingeniørteamet mitt har gode SQL-ferdigheter. Jeg kan gjøre dette med SQL-verktøy som Mode eller Notebooks.
Fordeler
- Lave kostnader for SQL-editorverktøy.
- Dataingeniører kan skreddersy spesialiserte analyser ved hjelp av SQL som de er vant til og er sterke på.
- Grunnleggende visualisering som disse verktøyene tilbyr, kan være godt nok for kundene dine.
- SQL-verktøyene fungerer direkte på data i datavarehuset. De er derfor i samsvar med det moderne arkitekturmønsteret du abonnerer på. Du kan stole på analysene, siden de er basert direkte på masterdataene i datalageret og ikke på en kopi.
Ulemper
- Forretningsbrukere kan ikke selv utføre analyser, men må stole på, og vente på, at dataanalytikerne lager rapporter for hver forespørsel.
- SQL for produktanalysespørringer er uforholdsmessig kompleks og tungvint å skrive og vedlikeholde. Stor belastning på dataanalytikerne med gjentatte forespørsler fra virksomheten.
- Spesialiserte visualiseringer og modelleringskonstruksjoner som tidsserier, kohorter, trakter og stier er ikke tilgjengelige i vanlige SQL-verktøy.
- Rapportene som produseres, er ikke interaktive for neste analysenivå, f.eks. for å se nærmere på brukere som har falt fra mellom to stadier i en trakt.
- Rå SQL for produktanalysespørringer fungerer ikke og kan være ubrukelig treg. Analytikerne må samarbeide med datatekniske team for å løse ytelsesproblemer med cubing, tuning, forprosessering, sampling osv.
Bygg scenario 3:
Jeg har allerede Tableau. Jeg vil bare bruke det til produktanalyse.
Fordeler
- Ingen nye utgifter som følge av at du bruker et verktøy som du allerede har betalt for.
- Ingen nye verktøy å lære seg, fordi man bruker et kjent verktøy som allerede er i bruk.
- BI-verktøy som Tableau arbeider direkte med data i datavarehuset. De er derfor i samsvar med det moderne arkitekturmønsteret du abonnerer på.
- Du kan stole på analysene, siden de er basert direkte på masterdataene i datalageret og ikke på en kopi.
Ulemper
- BI-verktøy er ikke egnet til å uttrykke hendelsesorienterte produktanalysespørringer som involverer kohorter, sekvenser, baner, strømmer og tidsserier. Forretningsbrukerne kan derfor ikke betjene seg selv, og må stole på datateknikk.
- Dataingeniører må jobbe med SQL på lavt nivå. SQL for produktanalysespørringer er uforholdsmessig kompleks og tungvint å skrive og vedlikeholde. Stor belastning på datatekniske team med gjentatte, ofte banale, forespørsler fra virksomheten.
- BI-verktøyene fungerer ikke for produktanalysespørringer og kan være ubrukelige for mange bruksområder. Dataingeniørene må investere i cubing, tuning, forprosessering, sampling osv. for å omgå ytelsesproblemer.
- Interaksjoner i BI-rapporter er begrenset til tradisjonell dimensjonsboring og forstår ikke produktanalysesemantikken, f.eks. boring i brukere som falt fra mellom to stadier i en trakt, og se alle veiene de tok før de falt fra.
Kjøpsscenario 1:
La meg ta det sikre valget ved å velge et tradisjonelt førstegenerasjonsverktøy som Amplitude, som har eksistert i mer enn ti år.
Fordeler
- Lav risiko ved å kjøpe et tradisjonelt verktøy som er modent og kjent for å fungere.
- Det finnes folk som vet hvordan dette verktøyet fungerer, siden det har eksistert lenge.
- Forretningsbrukere kan betjene seg selv med enkle rapportmaler som er spesialutviklet for produktanalyse.
Ulemper
- Bygge og vedlikeholde kostbare ETL-jobber for å flytte data fra lageret til førstegenerasjons produktanalyseverktøy, siden disse verktøyene ikke kan arbeide direkte fra datavarehuset.
- Bryter med det grunnleggende arkitektoniske prinsippet om at datalageret skal være sentrert, og at data ikke skal flyttes ut av bedriftslageret. Eksponering for sikkerhets- og styringsrisiko ved at kritiske kundedata flyttes til en leverandørs SaaS-tjeneste med svart boks.
- Tallene stemmer ofte ikke overens mellom Tableau og Amplitude fordi de jobber med forskjellige datakopier. Uker brukt på å avstemme motstridende tall. Ikke stol på tallene i produktanalyseverktøyet, fordi det ofte jobber med foreldede eller ufullstendige kopier av masterdataene i lageret. Dette kan aldri legges frem for toppledelsen.
- Hendelsesbasert prising av produktanalyseverktøy som Amplitude gjør det uoverkommelig dyrt. Ingen enkel måte å slette ubrukte hendelser på. Du betaler unødvendig for hendelser, uansett om noen bruker dem eller ikke. Enorm innsats hver måned for å finne ut hvilke hendelser som skal sendes til produktanalyseverktøyet (og hvilke som ikke skal det), for å kontrollere kostnadene.
- Siden førstegenerasjonsverktøyet ble utviklet med en spesifikk datamodell og et beregningssystem med én tabell, kan du ikke gå lenger enn til grunnleggende rapportering etter mal. Det er umulig å gjøre ad hoc-analyser, spesielt med ytterligere forretningskontekst som kontoer, kontrakter, tickets, supportsamtaler osv. Som et resultat må data fra verktøyet ETL-behandles ut til datalageret for videre analyse av datatekniske team. Ytterligere ETL-hodepine.
- Forretningsteamene starter med førstegenerasjonsverktøyene, men møter raskt veggen; de må kontakte datateknikk for å eksportere data og skrive tilpassede, enkeltstående rapporter som kan ta flere uker. Du ender opp med fragmenterte analyser i to separate systemer.
Kjøpsscenario 2:
Jeg ønsker å kjøpe et nestegenerasjons produktanalyseverktøy som ikke tvinger meg til å flytte data ut av datavarehuset mitt.
Ta en titt på Optimizely Warehouse-Native Analytics for et selvbetjent produktanalyseverktøy som ikke tvinger deg til å flytte data ut av datalageret. Vi er den første plattformen for produktanalyse som virkelig er warehouse-native - ingen data forlater noensinne det sikre datalageret ditt.
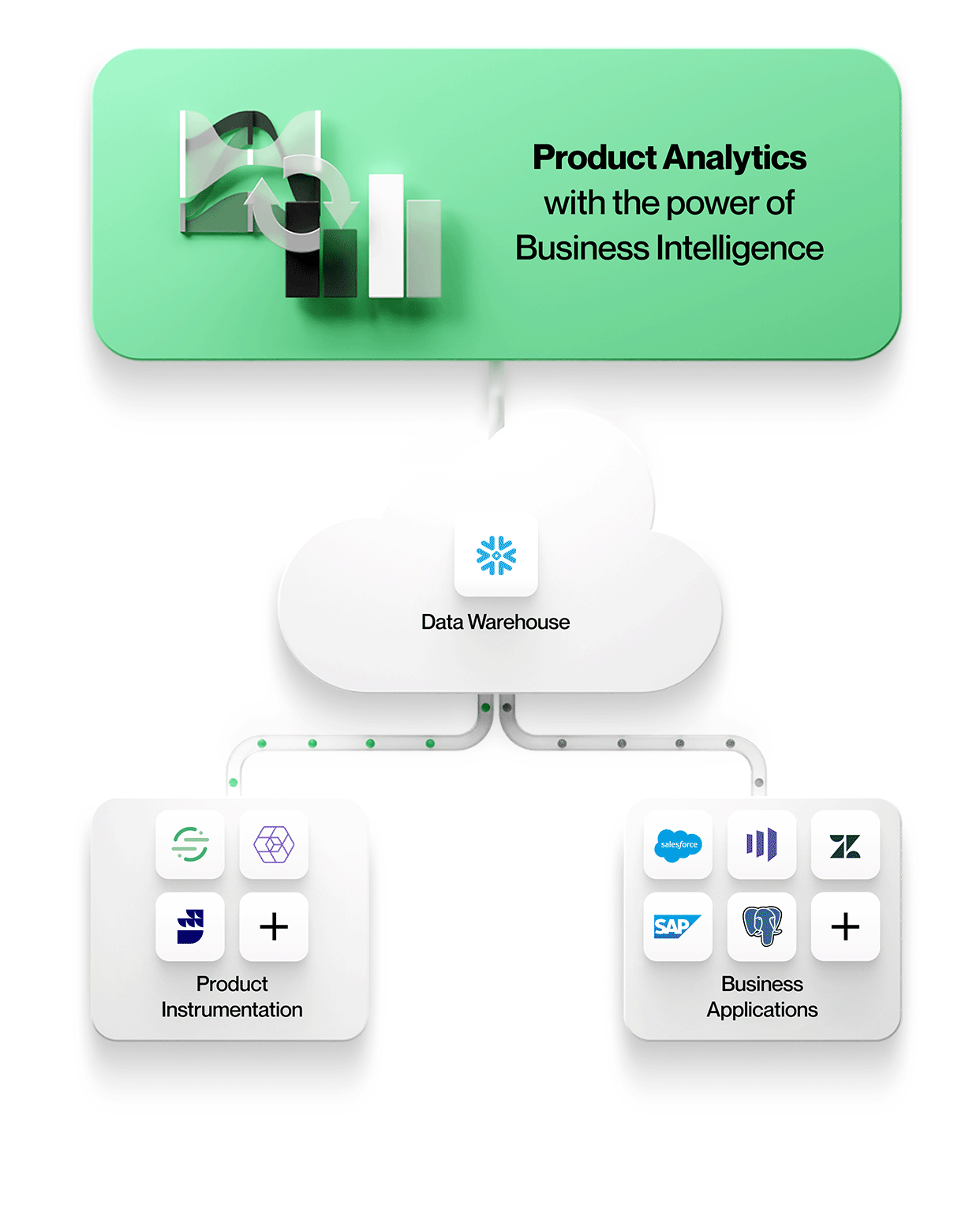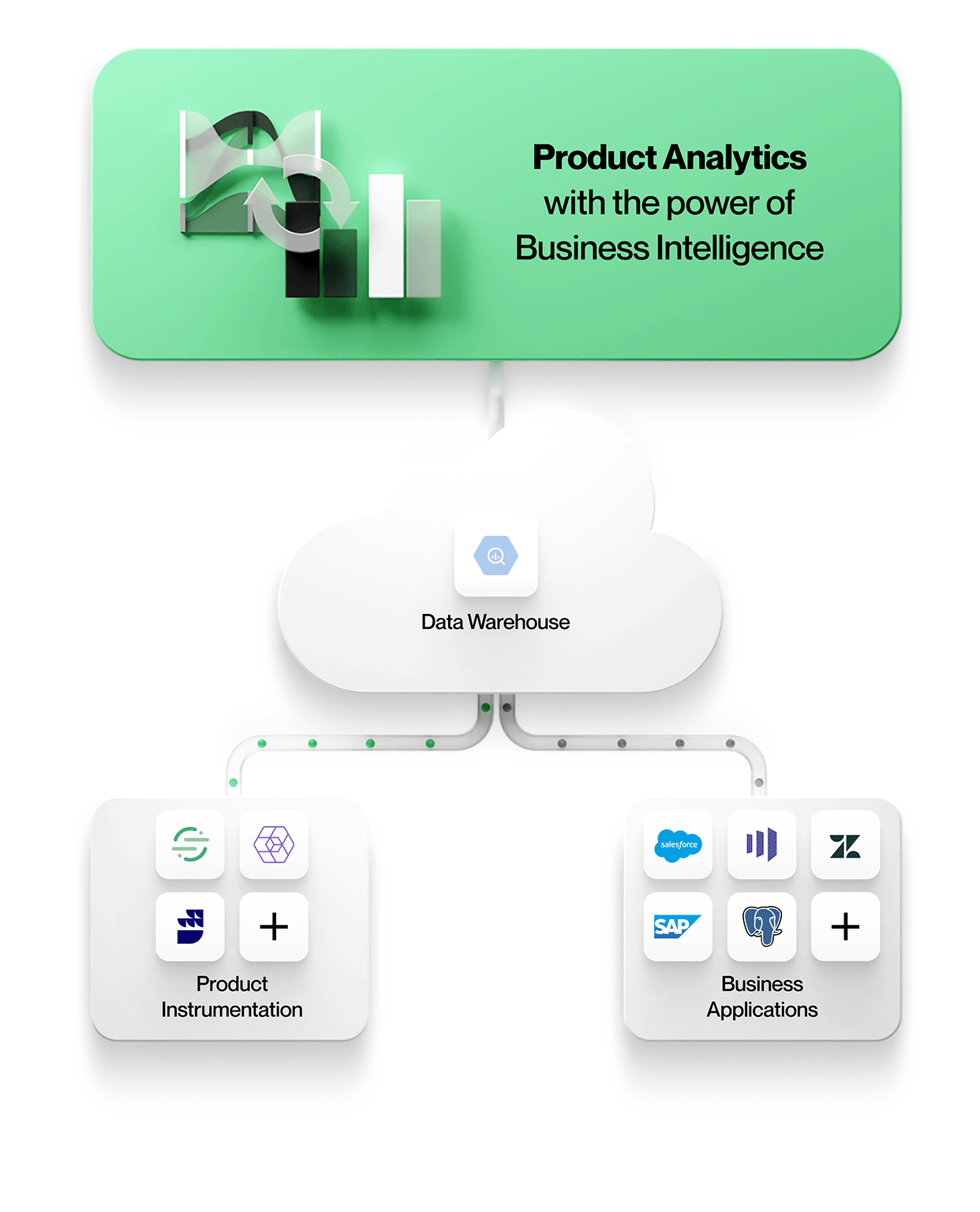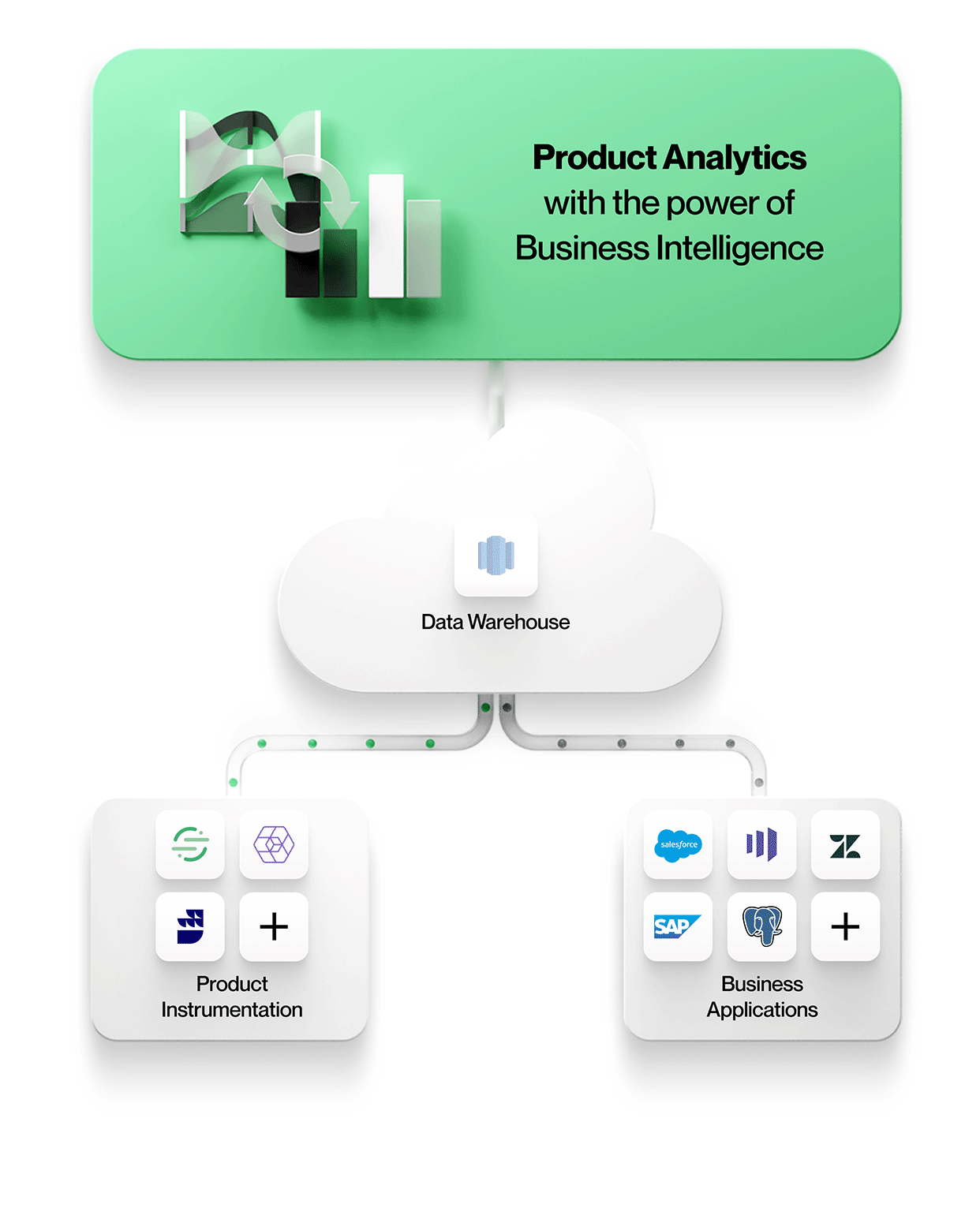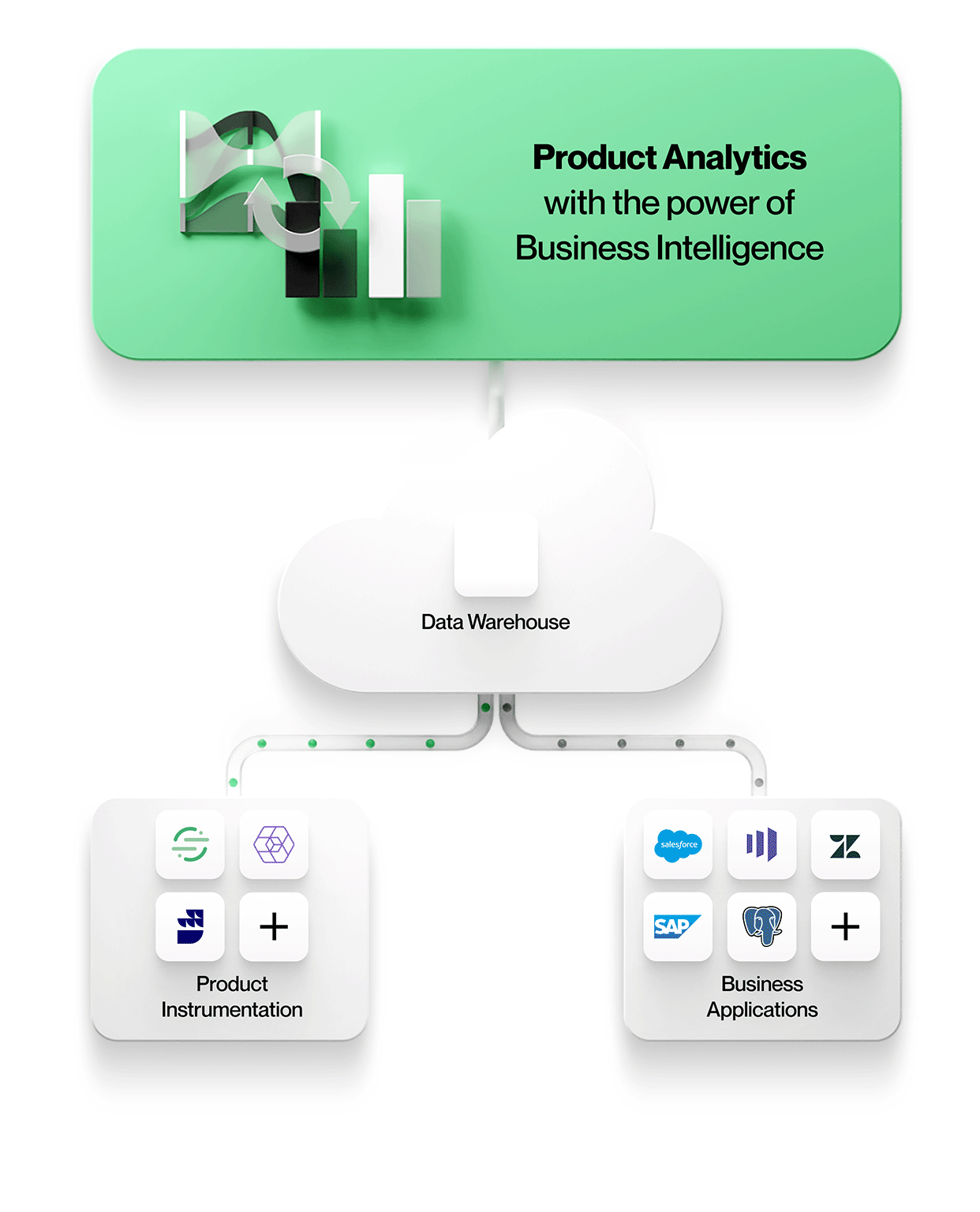
Figur 2: Neste generasjons produktanalyse med Optimizely Warehouse-Native Analytics
Optimizely Warehouse-Native Analytics bringer ad hoc-analysekraften fra BI til produktanalyseverdenen. Med omfattende produktanalysemaler og visuelle ad hoc-datautforskningsmuligheter gjør Optimizely Warehouse-Native Analytics det mulig for forretningsbrukere å betjene selv avanserte behov. Bygg komplekse trakter på tvers av hendelsesstrømmer med betingede stadier, alt i et miljø uten kode, i stedet for å skrive side opp og side ned med blodig SQL.
Se video: Sammenligning av Optimizely Warehouse-Native Analytics vs. SQL-utvikling for å bygge en 4-trinns trakt og deretter legge til et filter
Optimizely Warehouse-Native Analytics genererer automatisk elegant SQL for de mest sofistikerte produktanalysespørringene, og gir også analytikere og dataingeniører full SQL-støtte og avanserte skriptfunksjoner. Men de fleste av de mest sofistikerte spørsmålene kan enkelt besvares i den fullstendig selvbetjente plattformen.

Entreprenør, leder og produktleder med dokumentert erfaring med å utvikle og bygge innovative, vellykkede programvaresystemer i stor skala Selskapsbygger som har...
- Sist oppdatert:25.04.2025 21:30:38