
Som en datadrevet organisasjon bruker du sannsynligvis flere analyseverktøy for å løse ulike analytiske bruksområder:
- Business Intelligence (BI) - for rapportering av historiske forretningsdata, med utgangspunkt i aggregerte transaksjonsdata som hentes inn i datavarehuset fra forretningssystemer.
- Produktanalyse - for å analysere mønstre i produktbruk og kundeatferd fra hendelsesdata fra produktinstrumentering, for å optimalisere brukeropplevelse, konvertering, engasjement, oppbevaring og vekst.
- Infrastrukturovervåking - For sanntidsovervåking av driftstilstanden til systemer og applikasjoner ved hjelp av server-, prosess- og loggdata.
- Maskinlæring (ML) - for å analysere og trekke slutninger fra mønstre i data ved hjelp av AI-algoritmer og statistiske modeller.
Mens de to sistnevnte, infrastrukturovervåking og maskinlæring (ML), er spesialiserte verktøy som sannsynligvis vil forbli atskilte, er grensene mellom Business Intelligence (BI) og Product Analytics i ferd med å viskes ut.
Utviklingen av produktanalyse
Hvorfor viskes grensene mellom BI og produktanalyse ut? Historisk sett har produktanalyse vært fokusert på å analysere strømmer av produktinstrumenter for å gi produktsjefer innsyn i produktbruken. Førstegenerasjonsverktøy som Amplitude og Mixpanel har gjort tradisjonell produktanalyse mainstream. Men den siloformede visningen har alltid vært svært begrensende. Dette har blitt ytterligere forverret i nyere tid med PLG-drevne bevegelser, der bedrifter ønsker et 360-graders innblikk i kundene sine - på tvers av alle interaksjonskanaler og med kontekst fra alle forretningssystemer. Førstegenerasjonsverktøyene har forsøkt å løse dette med enkle "omvendt ETL"-løsninger, noe som er tungvint og ufullstendig.
Fra produktmålinger til virksomhetsmålinger
Tenk deg et tradisjonelt produktanalyseverktøy som viser deg at konverteringsfrekvensen har økt etter lanseringen av en ny funksjon. Men hva om flertallet av kundene som konverterte, endte opp med å avbestille ved å ringe kundesenteret? Disse dataene befinner seg ikke i den siloformede produktinstrumentasjonsstrømmen som tradisjonelle verktøy jobber med. De befinner seg i et annet forretningssystem som er utilgjengelig for førstegenerasjons produktanalyseverktøy. Kan du på samme måte forstå effekten av en produktendring på supporthenvendelser/samtaler - data som finnes i Zendesk? Kan du forstå produktengasjement etter abonnementsnivå - data som finnes i Salesforce? Kan du bli varslet om produktfriksjon eller økt engasjement hos kunder som skal fornye abonnementet om en måned - data som finnes i NetSuite?
Kan du fordele abonnementsinntektene på ulike kundegrupper? Kan du prioritere produktproblemer basert på innvirkning på inntektene? Kan du målrette de riktige kampanjene/tilbudene/oppfølgingen mot de riktige kundene basert på deres livstidsverdi?
Det er ikke lenger tilstrekkelig å forstå snevert definerte produktmålinger basert på produktinstrumentdata. Etter hvert som moderne virksomheter utvikler seg i retning av produktstyrt vekst, blir produktteamene raskt til inntektssentre, og de må gå fra produktmålinger til forretningsmålinger, der produktinstrumentasjonsdata bare er én kilde til input. De trenger et verktøy for forretningsanalyse som gir et bredere perspektiv. De trenger forretningsanalyse for å få større gjennomslagskraft og innflytelse hos toppledelsen.
Forretningsanalyse for alle
Tradisjonell produktanalyse har først og fremst vært til nytte for produktsjefer. Men flere andre team i moderne bedrifter trenger innsyn i produktbruk og kundeatferd i sammenheng med forretningsfunksjonene sine. Forretningsanalyse er for alle i organisasjonen som bryr seg om produktet og kundene deres - Growth Marketing, Customer Success, Sales og Support. Og produktansvarlige kan også dra nytte av en bredere forståelse av den forretningsmessige effekten av produktfunksjonene de jobber med.
Hvordan ser et Business Analytics-verktøy ut?
Så hvordan ser et slikt Business Analytics-verktøy ut? Det starter med klassisk produktanalyse, for eksempel hendelsessegmentering, oppbevaring, trakt, stier osv. Men vi snakker også om å innlemme data fra forretningssystemer som vanligvis rapporteres i BI-verktøy. Vi snakker om sømløs navigering fra det ene til det andre. Ta for eksempel en kohort av brukere som har falt fra et bestemt traktstadium til et annet, og bryt dem ned etter ulike dimensjoner som konto, region, alder osv. Førstnevnte (trakt) er klassisk produktanalyse. Sistnevnte (dimensjonal oppdeling) er klassisk BI.
Utfordringen i dag er at disse ligger i separate systemer. Så når en bruker i et førstegenerasjons produktanalyseverktøy har spørsmål på neste nivå, må de ringe datateknikerteamet for å få laget en engangsrapport i et BI-verktøy. Dataingeniørene må eksportere data fra produktanalyseverktøyet til et datavarehus og skrive tungvint SQL for å produsere rapporten - noe som kan ta flere uker. I tillegg har du nå fragmenterte analyser i to separate systemer som ikke kan brukes sømløst. Hva om du for eksempel ønsker å opprette en kohort av brukere fra en BI-rapport og bruke den til å forstå brukernes reise i produktet? Det er praktisk talt umulig å gjøre det i dag.
Neste generasjons forretningsanalyseverktøy er en sammensmelting av tradisjonelle produktanalyseverktøy og BI-verktøy i én og samme plattform.
Arkitekturen til BI- og produktanalyseverktøy
Konvensjonell visdom sier at du ikke kan gjøre produktanalyse i et BI-verktøy, eller BI i et produktanalyseverktøy. Det var en gang sant.
Tradisjonelle produktanalyseverktøy kan i dag ikke jobbe fra et lager, slik BI-verktøy kan. De har ikke et generisk datamodellerings- eller analytisk uttrykkslag, slik BI har. De er spesialbygd for et spesifikt bruksområde og er ikke generiske analyseplattformer som BI.
BI-verktøy er på den annen side ikke egnet til å uttrykke hendelsesorienterte spørringer som involverer sekvenser, baner, strømmer og tidsserier. Det er ekstremt tungvint å uttrykke slike spørsmål i SQL. Dessuten er ikke SQL-ene de genererer, egnet for interaktiv analyse.
Disse to typene systemer ble bygget opp på ulike måter - ett hendelsesorientert og ett tilstandsorientert.
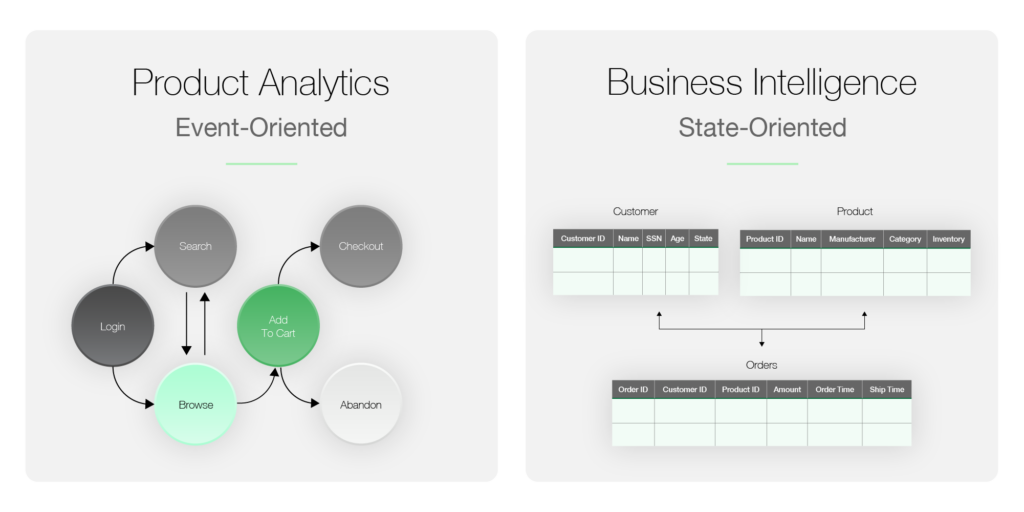
Men disse systemene ble utviklet for flere tiår siden. Hva om du kunne starte fra bunnen av og lage et system som kan tjene begge formålene? Hva om BI og produktanalyse kunne konvergeres til én plattform? Forretningsverdien av et slikt konvergert verktøy ville være enorm!
Den moderne datastakken
Generasjonsskifter i analyseverktøy ledsages ofte av store endringer i dataarkitekturen. I dag er vi vitne til et skifte til den moderne datastakken.
Datavarehus i skyen
Sentralt i den moderne datastakken står et datavarehus i skyen, som Snowflake eller BigQuery. Disse datavarehusene er det sentrale lageret for alle data i moderne bedrifter. Selv data som produktinstrumenteringshendelser eller IoT-sensoravlesninger, som tradisjonelt sett aldri har havnet i datalageret, lagres nå der. Dette er det viktigste skiftet.
Komponerbar CDP
Det andre skiftet er fremveksten av den komponerbare CDP-en. Komponerbar CDP betyr at man bruker best-of-breed-systemer sentralisert på datalageret. Dette innebærer
- Spesialiserte instrumenteringssystemer som Rudderstack, Segment eller Snowplow som er frikoblet fra analyseverktøyene, og som leverer data i nøytrale formater på lageret slik at alle enkelt kan bruke dem. Det er slutt på at kritiske kundedata forsvinner til en SaaS-tjeneste i et svart hull.
- SpesialiserteELT-verktøy (i motsetning tilETL-verktøy) som Fivetran, som bringer data fra forretningssystemer som Salesforce og Zendesk til lageret.
- Lagerintegrerte datatransformasjonsverktøy som DBT for å transformere rådata til mer anvendelige former.
- Dataaktivering til forretningssystemer direkte fra lageret.
- Lagerintegrert forretningsanalyse direkte på toppen av lageret. Ingen data forlater noensinne lageret. Ingen ekstra ETL/omvendt ETL-rot. Ingen tid med å finne ut hva som skal sendes (eller ikke sendes) til produktanalysetjenesten for å kontrollere kostnadene.
- Høyere nivåer av sikkerhet og styring i kraft av å være lagersentrisk.
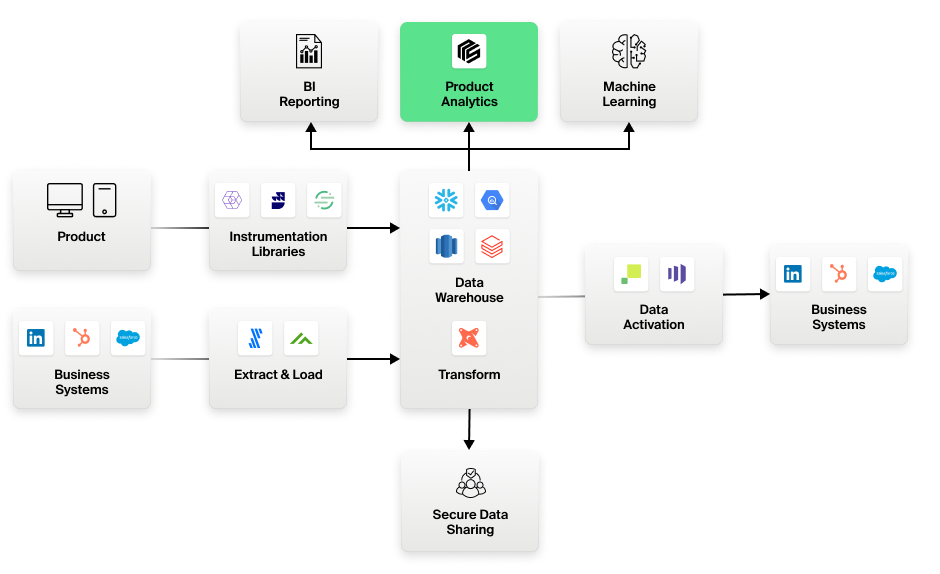
Optimizely Warehouse-Native Analytics-tilnærmingen
Hos Optimizely Warehouse-Native Analytics har vi utviklet systemet vårt fra grunnen av med tanke på Modern Data Stack. Vi har utviklet en arkitektur som bygger bro mellom hendelses- og tilstandsorienterte systemer. Vi er warehouse-native, der alle beregninger skjer inne i datalageret, og ingen data noensinne forlater lageret. Vi tilbyr spesialiserte maler for produktanalyse, men også ad hoc-analyser i BI-stil - alt gjennom et selvbetjent grensesnitt.
Vi gjorde dette ved å starte med en tradisjonell relasjonsmodell og legge en hendelsesmodell på toppen. Så til syvende og sist er det SQL-spørringer som genereres, og som kjøres mot lageret. Den tradisjonelle relasjonsmodellen muliggjør dimensjonale analyser i BI-stil. Hendelsesmodellen gir rike uttrykksmuligheter og optimaliseringer for spesialiserte produktanalyserapporter. Et spesialisert språk kalt NetScript gir et abstraksjonslag for optimalisert spørringsbehandling som kan fungere godt i lageret.
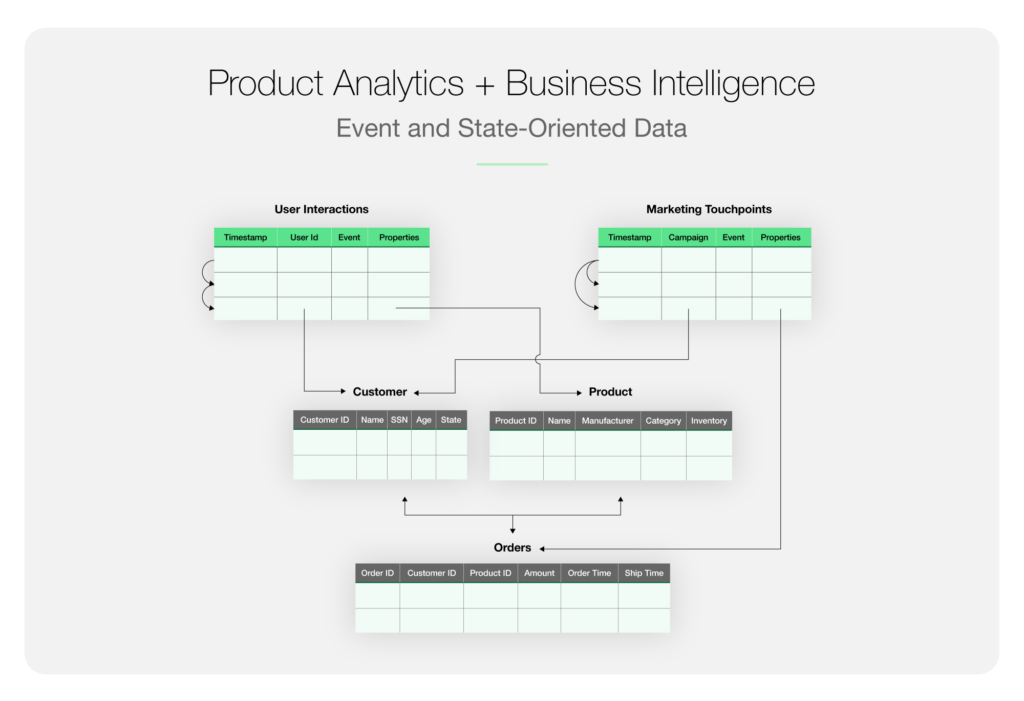
Vi mener at BI og produktanalyse kan gjøres effektivt i ett og samme verktøy. Dette gir enorme fordeler når det gjelder kostnader, styring, sikkerhet og analyser med stor forretningseffekt.
På samme måte som datavarehuset eliminerer siloer av data, eliminerer Business Analytics-systemer som Optimizely Warehouse-Native Analytics siloer av analyser. Ett enkelt analyseverktøy på ett enkelt sentrallager - denne drømmen er i ferd med å gå i oppfyllelse nå. Og bedriftene har gode grunner til å omfavne og feire den.

Entreprenør, leder og produktleder med dokumentert erfaring med å utvikle og bygge innovative, vellykkede programvaresystemer i stor skala Selskapsbygger som har...
- Sist oppdatert:25.04.2025 21:30:38