Traktanalyse SQL i lagerintegrert produktanalyse

Å analysere og forstå trakter er en viktig ferdighet for alle produktsjefer (PM). Det hjelper dem med å forstå og optimalisere bruken av produkter og funksjoner ved at de kan spore og visualisere kundereisen fra anskaffelse, gjennom aktivering, oppbevaring, henvisning og inntekter, eller brukernes delreiser gjennom en hvilken som helst arbeidsflyt i produktet - samtidig som konverterings- og frafallsrater fremheves underveis. Ved hjelp av traktanalyse kan PM-er definere suksesskriterier og spore stegene en bruker tar for å nå suksesskriteriene i tilfelle konvertering, eller punktet i produktet der brukeren avbrøt arbeidsflyten, i tilfelle frafall.
Denne typen analyse er ganske forskjellig fra forretningsanalyse, som aggregerer tiltak på et sett med dimensjonale attributter for å forstå forretningsresultatene. Basert på mine mer enn 10 års erfaring med å bygge databaser med høy ytelse, mener jeg imidlertid at moderne datavarehus er godt rustet til å effektivt utføre slike (faktisk alle produktanalyser) arbeidsmengder i stor skala.
I dette innlegget vil jeg dykke dypt inn i de interne beregningene som ligger bak beregningen av trakter, og beskrive hvordan moderne datavarehus kan utføre traktspørringer i stor skala.
Hva er traktanalyse?
Wikipedia definerer traktanalyse som kartlegging og analyse av en rekke hendelser som leder mot et definert mål, for eksempel en annonse-til-kjøp-reise i nettannonsering. Eksemplet nedenfor følger konverteringen av brukere til "Betalt aktivering" etter å ha tatt opplæringskurs på en nettbasert læringsplattform - 18,6 % av brukerne tar "Analytics-kurset" etter "Komme i gang", og av disse konverterer 31 % av brukerne til "Betalt aktivering", noe som gir en total konvertering på 5,8 %.
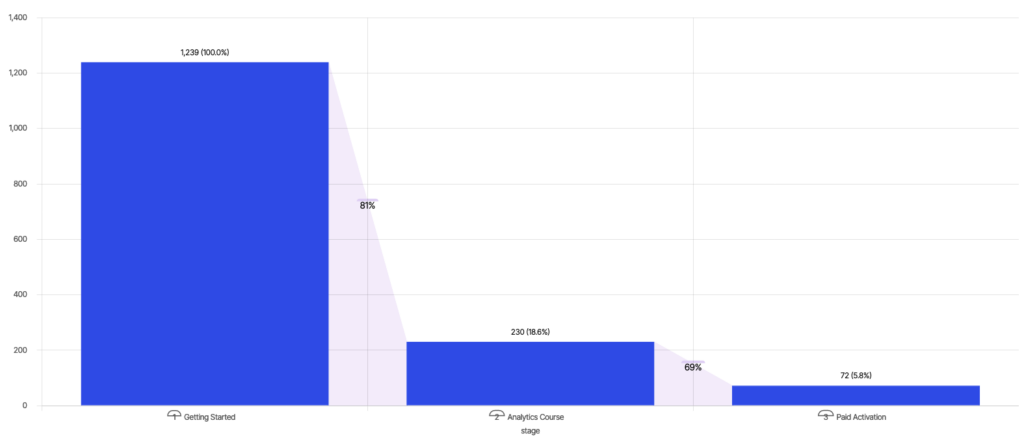
En PM som ønsker å øke engasjementet, kan se på konverterings- og frafallsraten mellom de ulike trinnene og bestemme seg for å fokusere på å forbedre konverteringen mellom "Komme i gang" og "Analytics-kurs" for å øke "Betalt aktivering".
Hvordan bygge en trakt
Konseptuelt følger en trakt en ordnet sekvens av hendelser etter "event_time" for hver bruker for å beregne det lengste trakttrinnet de har nådd. Det finnes flere måter å uttrykke denne beregningen på ved hjelp av SQL. Vi skal ta for oss to slike mønstre og gi innsikt i ytelsen for begge. Men før vi går over til SQL, skal vi definere datamodellen som brukes til denne analysen.
Datamodell
La oss ta utgangspunkt i et skjema med en enkelt "Events"-tabell. Dataene i "Events" kan tenkes å ha følgende form:
| hendelsesnavn | hendelses_tidspunkt | bruker_id | OS | nettleser |
| Komme i gang | 0 | user_id0 | ios | safari |
| Kurs i analyse | 1 | user_id0 |
ios |
safari |
| Kurs i analyse | 1 | user_id1 | android | krom |
| Betalt aktivering | 4 | user_id0 | ios | safari |
Jeg har gjort to forenklende antakelser i denne modellen, men som jeg forklarer nedenfor, er ingen av disse antakelsene et problemområde for moderne datavarehus.
- Strukturerte data - "Events" antas å være en strukturert tabell, selv om hendelsesdata nesten alltid er semi-strukturerte. Se min forrige blogg for å forstå hvordan datavarehus håndterer semi-strukturerte data på en effektiv måte.
- Ingen sammenkoblinger - Førstegenerasjonsverktøy som Amplitude og Mixpanel modellerer skjemaet sitt som en enkelt hendelsesstrøm. Denne modellen kan være svært begrensende, spesielt siden enhver analyse i den virkelige verden krever forretningskontekst fra andre kilder. I motsetning til førstegenerasjons produktanalyseverktøy som Amplitude og Mixpanel, som gir svært begrensede spørringsmuligheter, er moderne datavarehus bygget for å koble sammen flere tabeller på en effektiv måte.
Traktspørring

Spørringsmotorer analyserer og optimaliserer SQL-tekst for å lage en optimalisert relasjonsplan for kjøring. La oss visualisere den optimaliserte relasjonsplanen for denne SQL-en for å få en bedre forståelse av kjøringsprofilen.Det er én underforespørsel for hvert trinn i trakten:
- stage1-underspørringen sender ut unike user_ids som har opplevd hendelsen "Getting Started"
- trinn2-underspørring kobler "Events"-tabellen med trinn1-utdata for å sende ut individuelle user_ids som nådde "Analytics Course"-hendelsen etter "Getting Started"-hendelsen
- trinn3-underspørring kobler "Events"-tabellen med trinn2-utdata for å sende ut unike user_ids som nådde "Betalt aktivering"-hendelsen etter "Komme i gang"- og "Analysekurs"-hendelsen, i den rekkefølgen
- Utdata fra alle tre trinnene aggregeres for å telle antall unike brukere i hvert trinn
Moderne datavarehus har ekstremt sofistikerte spørringsplanleggere for å optimalisere relasjonelle trær. Det er to optimaliseringer i planen ovenfor som er verdt å nevne:
- Beregning for hvert trinn skjer én gang - Optimaliseringsverktøyet regner ut overflødige beregninger i planen som delplaner eller fragmenter for å gjenbruke resultatene i hele spørringen. De beste motorene i klassen planlegger delplaner adaptivt for å bruke resultater og statistikk til videre planlegging.
- Aggregering i "Final Output" skyves under sammenføyningen - Optimaliseringsprogrammer i toppklasse bør kunne utlede at aggregering kan skyves under venstre sammenføyning for mange-til-en-sammenføyninger, slik som her, for å eliminere kostnadene ved en dyr venstre sammenføyning mellom de tre trinnene. Å lage en spørring som aggregerer før sammenføyning, er også et levedyktig alternativ for en analysemotor i tilfelle optimaliseringsverktøyet ikke er i stand til å optimalisere for dette mønsteret.
Aggregate- og Join-operasjoner er helt sentrale i moderne datavarehus, og gjør det mulig å utføre slike spørringer effektivt i stor skala med massiv parallellitet. Det finnes imidlertid fortsatt et par forbedringer som kan forbedre spørringens ytelse ytterligere:
- Sammenføyning mellomunderspørringer - Sammenføyninger mellom underspørringer er dyrere enn sammenføyninger av basistabeller, siden underspørringer ikke har sammenføyningsindekser som er forhåndsberegnet. I vårt eksempel er "Events" og hver trinnutgang koblet sammen på brukernivå, noe som kan være kostbart for brukere med høy kardinalitet. Merk at krysskoblingen i den endelige spørringen er ganske billig, siden den kobler sammen nøyaktig én rad fra hver inngang.
- Flere skanninger - Selv etter at overflødige beregninger er fjernet, skannes tabellen "Events" tre ganger, én for hver underspørring. En raskere og mer effektiv algoritme ville skannet "Events"-tabellen bare én gang.
Forespørsel om stablede vindusfunksjoner
En alternativ tilnærming til å erklære denne beregningen er å bruke vindusfunksjoner. Window-funksjoner muliggjør imperativ hendelsessekvensanalyse via det deklarative SQL-grensesnittet. I denne tilnærmingen oppretter vi en stabel med vindusfunksjoner (partition over), én for hvert trinn i trakten, etterfulgt av en distinkt telling av "user_ids" på toppen av denne stakken. Vi kaller dette mønsteret for Stacked Window Functions-mønsteret. Her er SQL for å opprette den samme trakten ved hjelp av Stacked Window Functions.

Selv om spørringen ovenfor er mer ordrik, skaper den en mye enklere relasjonell plan - mesteparten av kompleksiteten for å beregne trakten er lagt inn i vindusfunksjonen.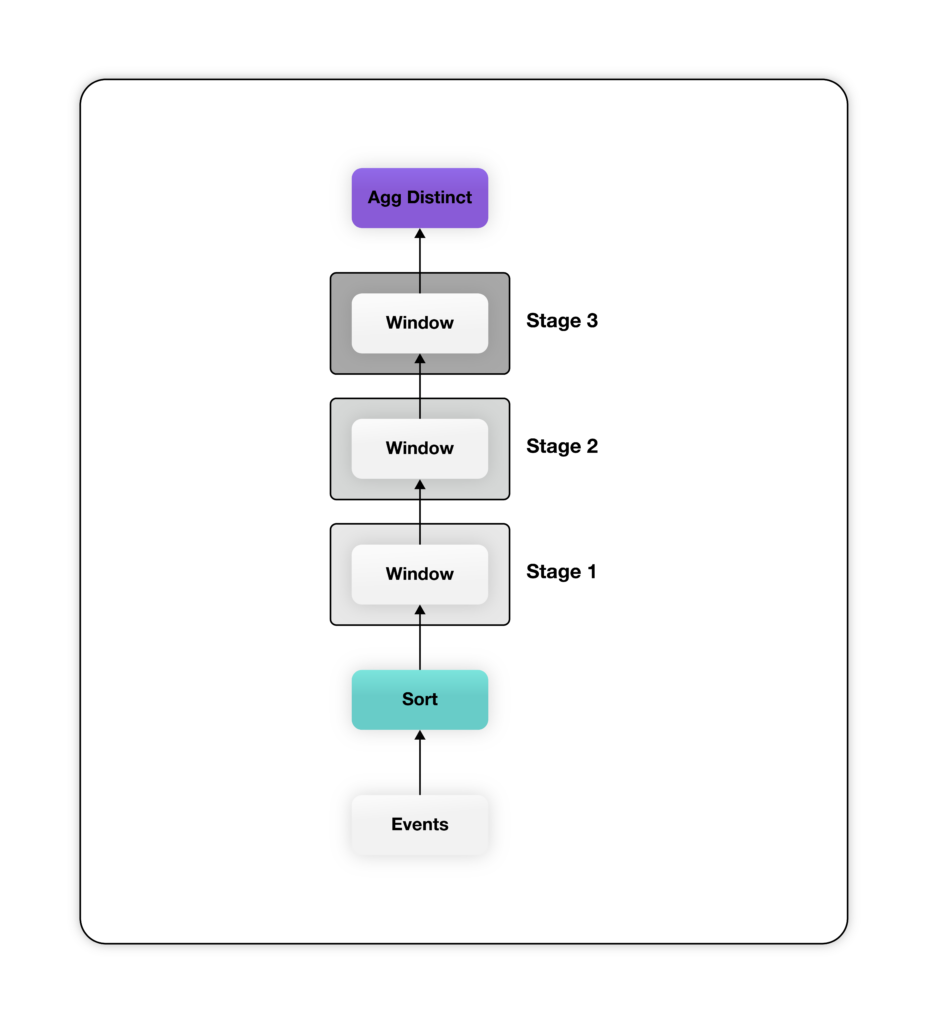 Planen ovenfor har én vindusfunksjon for hvert trinn i trakten. Legg merke til at vindusfunksjonene som er definert i SQL-koden ovenfor, deler inndataene inn etter "user_id" og sorterer etter "event_time" for å sikre at data for hver bruker behandles av den samme vindusfunksjonsinstansen i stigende rekkefølge etter "event_time". Hver vindusfunksjon sender ut en ekstra kolonne som inneholder det tidligste tidsstempelet når brukeren når det tilsvarende stadiet, eller null hvis brukeren ikke når dette stadiet. Til slutt aggregeres utdataene fra det siste vinduet, som inneholder én kolonne med "event_time" for hvert trinn for alle brukere, for å telle distinkte "user_ids" per trinn.
Planen ovenfor har én vindusfunksjon for hvert trinn i trakten. Legg merke til at vindusfunksjonene som er definert i SQL-koden ovenfor, deler inndataene inn etter "user_id" og sorterer etter "event_time" for å sikre at data for hver bruker behandles av den samme vindusfunksjonsinstansen i stigende rekkefølge etter "event_time". Hver vindusfunksjon sender ut en ekstra kolonne som inneholder det tidligste tidsstempelet når brukeren når det tilsvarende stadiet, eller null hvis brukeren ikke når dette stadiet. Til slutt aggregeres utdataene fra det siste vinduet, som inneholder én kolonne med "event_time" for hvert trinn for alle brukere, for å telle distinkte "user_ids" per trinn.
Som tidligere gjør spørringsplanleggeren i de fleste moderne datavarehus to kritiske optimaliseringer for å forbedre ytelsen til planen ovenfor:
- Enkel sortering på tvers av vinduer - Alle vindusfunksjoner er partisjonert på "user_id" og sortert på "event_time". I et slikt tilfelle lager optimaliseringsverktøyet én enkelt sorteringsoperator som mater data i ønsket rekkefølge til alle vindusfunksjonene.
- Lokal distinkt aggregering - spørringen har en distinkt aggregering på "user_id". Denne aggregeringen kan utføres innenfor en partisjon (lokalt) hvis dataene er forhåndspartisjonert på "user_id", siden brukerbasert partisjonering garanterer at brukere ikke trenger å bli aggregert på tvers av partisjoner.
Begge optimaliseringene som er nevnt ovenfor, er standard i de fleste moderne datavarehus. Denne formuleringen av traktspørringen har ingen av de samme svakhetene som Join Sequence-formen av traktspørringen. Det er imidlertid ett problem som må løses. Sorteringsoperatoren på toppen av hendelsesskanningen kan virke dyr å beregne. Heldigvis er det ikke nødvendig at denne sorteringen er global; det er tilstrekkelig å sortere lokalt i partisjonen, siden vindusoperatoren krever sortert input per bruker og ikke på tvers av brukere.
Det er potensial for å optimalisere denne spørringen ytterligere. De fleste datavarehus tilbyr en knapp for å klynge tabeller ved hjelp av en brukertilpasset klyngenøkkel. Klyngenøkkelen er et sett med kolonner eller kolonneuttrykk som brukes til å plassere rader i en tabell i nærheten av hverandre for å forbedre ytelsen. Klynging av tabellen "Events" etter "event_time" har flere fordeler:
- Redusere (kanskje til og med eliminere) kostnaden for sorteringsoperatoren hvis dataene er nesten (eller helt) sortert etter hendelsestid
- Forbedre skanneytelsen på "Events" for spørringer med tidsintervallfiltre på "event_time"-kolonnen
Konklusjon
I denne bloggen har vi presentert to ulike formuleringer av traktanalyse-SQL og analysert deres respektive spørringsplaner for å forstå ytelsesprofilen i moderne datavarehus.
Førstegenerasjonsverktøy som Mixpanel og Amplitude har en utdatert arkitektur som krever dataflytting, skaper datasiloer og duplisering, og som dessuten er uoverkommelig dyr i stor skala. Moderne datavarehus har modnet til et punkt der de kan gi en interaktiv opplevelse for produktanalysearbeid uten disse manglene og med fleksibiliteten til å justere kostnadene for ønsket ytelse.
Optimizely Warehouse-Native Analytics kan kobles til alle de største leverandørene av datavarehus i skyen, inkludert Snowflake, BigQuery, Redshift og Databricks, for å gi en rik produktanalyseopplevelse - uten dataflytting og til en tredjedel av kostnadene ved eldre tilnærminger.

- Sist oppdatert:25.04.2025 21:30:38