Motor for innholdsanbefalinger
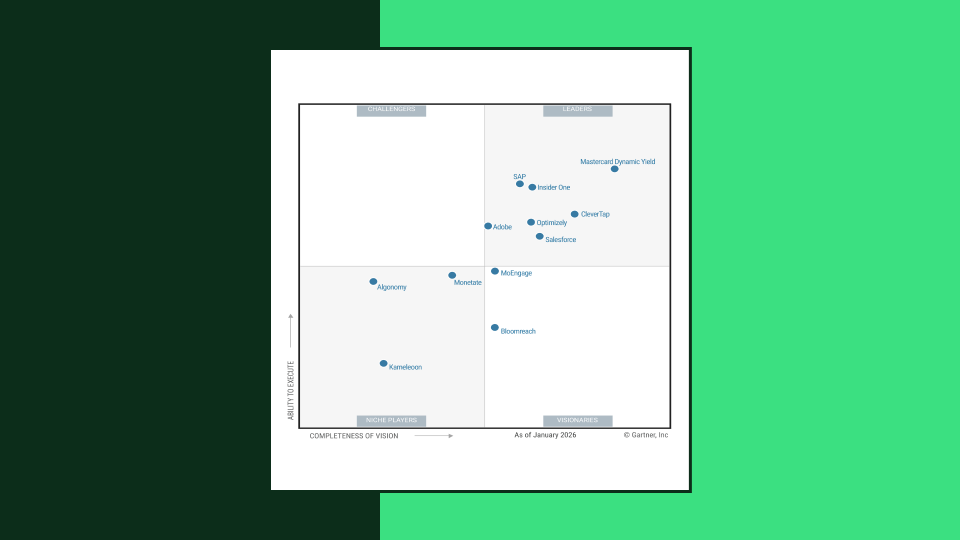
Hva er en innholdsanbefalingsmotor?
En innholdsanbefalingsmotor er et verktøy som bruker data og algoritmer til å foreslå innhold til brukere basert på deres preferanser, atferd og interesser. Det er et system som lærer av publikums interaksjoner og skreddersyr innhold som passer til deres behov. Det fungerer bak kulissene, lærer hva de besøkende liker og serverer innhold som er skreddersydd for dem. Du har sannsynligvis sett innholdsanbefalingsmotorer i aksjon uten å være klar over det, fra "Du vil kanskje også like"-seksjonen på en blogg til produktanbefalinger når du handler på nettet.
Et annet eksempel på dette er Netflix' anbefalingssystem. Når du har sett en serie eller film, foreslår Netflix lignende innhold basert på hva du allerede har sett. På samme måte bruker en nettbutikk som Amazon anbefalingsmotorer til å foreslå produkter basert på din surfe- og kjøpshistorikk.
For markedsførere kan innholdsanbefalingsmotorer hjelpe deg med å levere riktig innhold til de rette personene til rett tid, noe som øker engasjementet og konverteringen.
Viktige tips
-
En innholdsanbefalingsmotor gir personlig tilpasset innhold og forslag til besøkende på nettstedet for å optimalisere opplevelsen deres
-
Innholdsanbefalinger består av fire trinn: datainnsamling, datalagring, dataanalyse og datafiltrering
-
Samarbeidsfiltrering gir anbefalinger basert på hvor lik en bruker er andre brukere
-
Innholdsbasert filtrering gir anbefalinger basert på hva en bruker liker og ikke liker
-
Den hybride anbefalingsmodellen bruker en blanding av både kollaborativ og innholdsbasert filtrering for å gi de mest nøyaktige anbefalingene
Hva gjør en innholdsanbefalingsmotor?
En innholdsanbefalingsmotor er en programvareløsning som skaper personlige brukeropplevelser ved å analysere bruker- og produktdata. Motoren ser på brukerens tidligere atferd på nettet, hva han eller hun liker og ikke liker, og annen nøkkelinformasjon, og bruker disse dataene til å levere personalisert innhold eller komme med kjøps- eller visningsanbefalinger som er spesifikke for den aktuelle brukeren.
Det er ved hjelp av innholdsanbefalingsmotorer at Amazon kan anbefale produkter til deg når du handler på nettet, eller at Netflix kan foreslå nye serier og filmer du kanskje har lyst til å se. Hvis du er helt ny på nettstedet, vil du kanskje ikke finne så mange anbefalinger - eller så er det ikke sikkert at de anbefalingene du får, er nyttige. Men etter hvert som du fortsetter å bruke nettstedet og nettstedet blir kjent med hva du liker og ikke liker, vil du finne flere og mer nøyaktige forslag.
Noen innholdsanbefalingsmotorer mates med dynamisk innhold på nettsidene du besøker. Basert på din tidligere visningsatferd - og visningsatferden til andre brukere som deg - kan innholdsanbefalingsmotoren automatisk generere personlig tilpasset innhold etter hvert som du blar nedover siden.
Brukerne liker innholdsanbefalinger fordi det gir dem en mer personlig opplevelse. Selskaper liker anbefalingsmotorer fordi en mer personlig brukeropplevelse fører til økt seeroppslutning og flere kjøp. Det er en vinn-vinn-situasjon for alle involverte.
Hvorfor innholdsanbefalinger er viktige
Innholdsanbefalinger hjelper brukerne med å finne frem til mer innhold de vil like. I stedet for at brukerne forlater nettstedet ditt etter å ha lest ett blogginnlegg eller sett én video, kan velplasserte anbefalinger holde publikum engasjert lenger. Ved å foreslå relatert innhold viser du de besøkende at du "forstår" dem, noe som gjør det mer sannsynlig at de blir værende og utforsker mer av innholdet ditt.
Når du konsekvent tilbyr relevant innhold til brukerne dine, bygger du tillit, styrker forbindelsene og øker til slutt konverteringen. Tenk deg for eksempel at en bruker leser et blogginnlegg om Instagram-markedsføring. Hvis du deretter anbefaler en artikkel om hvordan du bygger en fantastisk Instagram-bio eller optimaliserer annonser, vil de sannsynligvis klikke seg videre og tilbringe mer tid på nettstedet ditt. Mer tid betyr flere sjanser til å gjøre besøkende til lojale kunder.
Fordelene med innholdsanbefalingsmotorer
Innholdsanbefalingsmotorer gir markedsførere som ønsker å forbedre sine strategier for å engasjere og beholde kunder, flere fordeler:
- Økt engasjement: Når brukerne ser innhold som gir gjenklang hos dem, er det mer sannsynlig at de blir værende. Ta YouTubes autoplay-funksjon som et eksempel. Når du er ferdig med én video, spilles det av en annen som er like relevant.
- Bedre konverteringsrater: Ved å tilpasse innholdsanbefalinger til målgruppen din, er det langt mer sannsynlig at de konverterer. Hvis du prøver å få besøkende til å abonnere eller kjøpe noe, kan du komme langt med skreddersydde innholdsforslag. Netthandelsnettsteder som Amazon bruker denne strategien effektivt for å foreslå produkter og øke salget.
- Forbedret brukeropplevelse: Innholdsanbefalingsmotorer gir en mer sømløs brukerreise. Når du slipper å lete deg gjennom et hav av innhold, blir friksjonen mindre og brukeropplevelsen mer behagelig.
- Forbedret personalisering: Innholdsanbefalingsmotorer bruker individuelle brukerdata til å levere skreddersydde innholdsforslag, noe som gjør personalisering av innhold til et mindre manuelt løft for markedsføringsteamet.
- Økt lojalitet: Ved å konsekvent levere relevant innhold til målgruppen din, øker du sannsynligheten for at de kommer tilbake og, på et eller annet tidspunkt, konverterer til betalende kunder.
Hvordan fungerer en innholdsanbefalingsmotor?
Innholdsanbefalinger er vanligvis en prosess i fire trinn. Det handler om å samle inn data, lagre dataene, analysere dataene og deretter filtrere dataene for å komme frem til anbefalinger.
-
Innsamling av data
Alle innholdsanbefalingsmotorer trenger data som de kan basere anbefalingene sine på. Disse dataene kan handle om brukeren (demografisk informasjon, kjøps- og visningsvaner osv.) eller om produktene (nøkkelord, beskrivelse osv.). Noen data er eksplisitte (innhentet fra kundene), mens andre er implisitte (innhentet fra kundenes atferd, for eksempel ordrehistorikk). -
Lagring av data
Datasettet som samles inn, må lagres i en eller annen form for database, for eksempel en SQL-database, slik at anbefalingsalgoritmen kan kjøres. -
Analyse av data
Innholdsanbefalingssystemet analyserer deretter de lagrede dataene og ser etter sammenhenger mellom datapunkter. Dette kan skje i sanntid eller via en ikke-dynamisk, batchbasert analyse. -
Filtrering av data
Det siste trinnet i prosessen med innholdsanbefalinger filtrerer dataene for å få frem den relevante informasjonen som er nødvendig for å gi brukeren en nøyaktig anbefaling. Dette gjøres vanligvis ved hjelp av en eller annen form for algoritme - samarbeidsbasert, innholdsbasert eller en hybrid av disse to tilnærmingene.
Typer filtreringsmotorer
Det finnes tre hovedtyper av filtrering som brukes til innholdsanbefalinger. Noen modeller bruker samarbeidsfiltrering, noen bruker innholdsbasert filtrering, og noen bruker en hybrid av disse to metodene.
-
Kollaborativ filtrering
Samarbeidsfiltrering samler inn og analyserer en rekke data for å forutsi hva brukerne vil like, basert på hvor lik en bruker er andre brukere. En kollaborativ filtreringsmotor bruker informasjon om brukernes aktiviteter, atferd og preferanser, for eksempel om de liker visse typer mat, filmer eller klær. Prediksjonene gjøres ved hjelp av ulike maskinlæringsteknikker.
Fordelen med kollaborativ filtrering er at den faktisk ikke analyserer eller forstår det underliggende innholdet. Den velger ganske enkelt innhold basert på det man vet om brukeren. Det er også en ulempe, ettersom anbefalingene ofte bare har overfladiske likheter med det brukeren faktisk liker.
Hvis bruker A for eksempel liker de samme TV-programmene som bruker B, og bruker A også liker poloskjorter, kan en kollaborativ filtreringsmotor anta at bruker B også liker poloskjorter, og anbefale poloskjorterelatert innhold til denne personen. Hvis anbefalingene er basert på nok datapunkter, kan de være overraskende nøyaktige. Anbefalinger basert på færre datapunkter kan imidlertid resultere i kun overfladiske anbefalinger.
Amazon bruker kollaborativ filtrering i sin anbefalingsmotor. Amazon bruker sofistikerte algoritmer til å anbefale lignende produkter basert på hva kundene nylig har kjøpt, for å holde på kundene. Nettstedet viser deretter disse anbefalingene i delen "Varer du kanskje vil like" på hver produktside. -
Innholdsbasert filtrering
Innholdsbasert filtrering har en annen tilnærming. Denne typen motor utnytter kunstig intelligens til å anbefale varer som ligner på dem brukeren tidligere har sett på eller kjøpt, i et forsøk på å forbedre kundeopplevelsen.
Tanken er at hvis en person liker vare A, og vare B ligner på vare A, så vil personen også like vare B. Hvis en bruker for eksempel har sett eller kjøpt en eller flere Marvel-filmer, kan den innholdsbaserte filtreringsmotoren anbefale en Marvel-TV-serie til denne brukeren, fordi de åpenbart har lignende innhold.
Effektiviteten til innholdsbasert filtrering er begrenset til å anbefale lignende typer innhold eller elementer til lignende brukere. For eksempel vil det å kjenne til en brukers filmpreferanser være til liten hjelp når man skal finne ut hva slags mat denne personen vil like.
Et godt eksempel på innholdsbasert filtrering finner du på Facebook. Når Facebook anbefaler potensielle venner for deg, gjør de det basert på ditt personlige innhold - hvor du bor, hvor du har jobbet, hvor du har gått på skole. Det er nesten ren innholdsbasert filtrering. -
Hybridanbefaling
Den hybride anbefalingsmodellen er en blanding av samarbeidsbaserte og innholdsbaserte filtreringsmodeller. Den ser på både kundens bruksdata og innholdsbeskrivelser, og gir dermed mer nøyaktige anbefalinger enn hver av metodene.
Netflix er et eksempel fra den virkelige verden på bruk av den hybride anbefalingsmodellen. For å gi anbefalinger til seerne ser Netflix på hvilke serier lignende seere har sett, i tillegg til innholdet i seriene du har sett. Resultatet er mer personlige anbefalinger enn det som ellers ville vært mulig - og står for 75 % av det seerne ser på tjenesten.
Eksempler på innholdsanbefalinger
Innholdsanbefalingsmotorer har mange forskjellige praktiske bruksområder, blant annet
- Blogganbefalinger: Etter at en bruker er ferdig med å lese et blogginnlegg, kan du anbefale aktuelt relaterte artikler. La oss si at de har lest et blogginnlegg om populære strategier for e-postmarkedsføring. Du kan foreslå et innlegg om A/B-testing av emnelinjer eller emojier som gir flest klikk - og på den måten bringe folk dypere inn i innholdsøkosystemet ditt.
- Produktanbefalinger: Du ser mye av dette på netthandelssider. Når du har sett på et par joggesko, kan nettstedet anbefale matchende tilbehør eller lignende stiler, noe som oppmuntrer deg til å legge flere produkter i handlekurven.
- Videoanbefalinger: YouTube gjør dette på en utmerket måte ved å foreslå relevante videoer basert på hva du allerede har sett. For markedsførere kan dette være en effektiv måte å få folk til å fortsette å se på videoene dine og øke deres engasjement med merkevaren din.
- Forslag til innhold i e-post: Persontilpassede e-postkampanjer bruker anbefalingsmotorer til å foreslå blogginnlegg, produkter eller tilbud basert på abonnentens aktivitet.
Bruksområder for plattformer for innholdsanbefalinger
Markedsførere i alle bransjer kan dra nytte av plattformer for innholdsanbefalinger på flere måter. Noen av de viktigste bruksområdene er
- Personalisering av netthandel: Innholdsanbefalingsmotorer kan brukes til kryssalg av nært beslektede produkter eller mersalg av en mer eksklusiv versjon av produktet. Shopify anbefaler for eksempel ofte komplementære produkter for å øke den gjennomsnittlige ordreverdien.
- Innholdsmarkedsføring: For blogger bidrar innholdsanbefalingsmotorer til å holde leserne engasjerte ved å foreslå mer innhold som matcher interessene deres, noe som resulterer i lengre økter og (ideelt sett) flere konverteringer.
- Videomarkedsføring: Hvis du bruker videoinnhold for å engasjere publikum, kan en anbefalingsmotor hjelpe deg med å finne relaterte videoer som holder seerne på nettstedet ditt lenger og øker engasjementet deres for merkevaren din. Tenk på hvordan Netflix får deg til å se lenger enn du hadde planlagt med sine "fordi du så ..."-forslag.
- E-postmarkedsføring: Personlige tilbud eller innholdsanbefalinger i e-postkampanjer kan øke klikkfrekvensen og drive mer trafikk til nettstedet ditt.
- Abonnementstjenester: Abonnementsbaserte apper, som Spotify, eller strømmetjenester som Netflix, er veldig flinke til å bruke innholdsanbefalinger for å holde kundene engasjerte og hindre at de slutter å bruke tjenesten. Det er også en gevinst for kunden - de slipper å scrolle i det uendelige for å finne noe de liker.
Fremtiden for innholdsanbefalingsmotorer
Med tiden kommer innholdsanbefalingsmotorer bare til å bli smartere - og kraftigere. Jo mer du kan levere hyperpersonalisert innhold, desto mer vil publikum engasjere seg i merkevaren din, noe som vil hjelpe deg med å bygge dypere kunderelasjoner og øke konverteringen.