Varje experiment behöver en testplan som avtalas innan lansering. Den innehåller hypotesen, experimenttypen, varianterna, inriktningen, den primära mätvariabeln, beslutsregler och risker. Utan den tolkas resultaten mot den fråga som verkar mest bekväm när data väl finns.
4. Utför och övervaka
Utförande är där väldesignade experiment brister.
De första timmarna bör fokusera på korrekthet, inte prestanda:
- Kontroll och alla varianter renderas korrekt
- Trafik delas upp enligt planerad allokering
- Primär mätvariabel registreras för alla varianter
- Inga spårningsluckor, dubbelräkning eller oväntade toppar
- Interna användare, bots och QA-trafik exkluderas
Förvänta dig volatilitet tidigt. Utvärdera inte prestanda under detta fönster. Målet är validering, inte tolkning.
När lanseringsvalideringen är klar skiftar övervakningen till att skydda integriteten. Håll utkik efter oförklarliga skiften i målgruppsmix, trafikinkonsistenser eller konflikter med andra experiment som körs på samma målgrupp.
När ett experiment är live, behandla designen som fast. Ändringar av varianter, inriktning eller mätvaribler introducerar snedvridning och gör resultatet opålitligt. Pausa bara för att skydda användare eller verksamheten. Avsluta bara baserat på fördefinierade kriterier. Dokumentera externa händelser som inträffar under körning.
Stoppa om den primära mätvariabeln når statistisk signifikans och testet har körts i minst två veckor för att fånga normala användarbeteendemönster. Stoppa även om testet har kört sin planerade varaktighet, samlat upp avsevärd trafik och resultaten förblir långt från signifikans – klassificera det som inkonklusivt och gå vidare.
5. Analysera och besluta
Det vanligaste misslyckandet i analys inträffar innan någon tittar på data.
- Tänk: Återge avsikten. Vilket problem experimentet designades för att lösa, vad hypotesen var, vad den primära mätvariabeln är och vilken riktning som utgör framgång. Detta förhindrar att frågan ändras efter att svaret setts.
- Observera: Primärt mätvariabelresultat för varje variant. Sekundära mätvaribler för kontext. Övervakningsvaribler för att visa om något gick sönder. Endast fördefinierade segment.
- Tolka: Leverera, iterera, expandera eller stoppa. Dokumentera varför beslutet fattades, inte bara vad som beslutades. Statistisk signifikans är ett tröskelvärde, inte en garanti.
Att koppla experiment till datalagret innebär att analysera mot customer lifetime value, returfrekvenser och kundlojalitet snarare än klick och konverteringar. Eftersom AI-sökning tar över upptäckten blir klick allt mindre förutsägande för affärsvärde. De mätvaribler som kommer att ha betydelse framöver finns i datalagret.
6. Leverera, iterera och ackumulera
Att leverera en vinnare är inte detsamma som att ackumulera ett lärande.
Bekräfta att beslutet fortfarande håller. Leverera exakt det som testades. Sista-minuten-justeringar förändrar mekanismen som producerade resultatet. Alla produktionsjusteringar dokumenteras.
Övervaka samma primära mätvariabel och räcken efter lansering. Iterera sedan:
- Förfina: Rikta in dig på beteendet som rörde sig eller misslyckades med att röra sig
- Utforska angränsande: Testa ett annat tillvägagångssätt på samma problem
- Expandera: Tillämpa samma mekanism på nya kontexter eller målgrupper
- Stoppa: Dokumentera lärandet och gå vidare
Ackumulering fungerar bara om resultaten förändrar vad som händer härnäst. De flesta team har känt vad som bryter detta. Ett testresultat delat i Slack som ingen agerade på. Ett hypotesmöte där samma idé dök upp som någon hade testat för åtta månader sedan, men ingen kom ihåg resultatet. Det är vad som händer när ett program inte har minne.
Struktur slår improvisation. Skriftligt slår muntligt. Brett deltagande slår små grupper. Programmen som ackumulerar är de där vem som helst kan hitta vad som testades, vad som lärdes och vad som kommer härnäst.
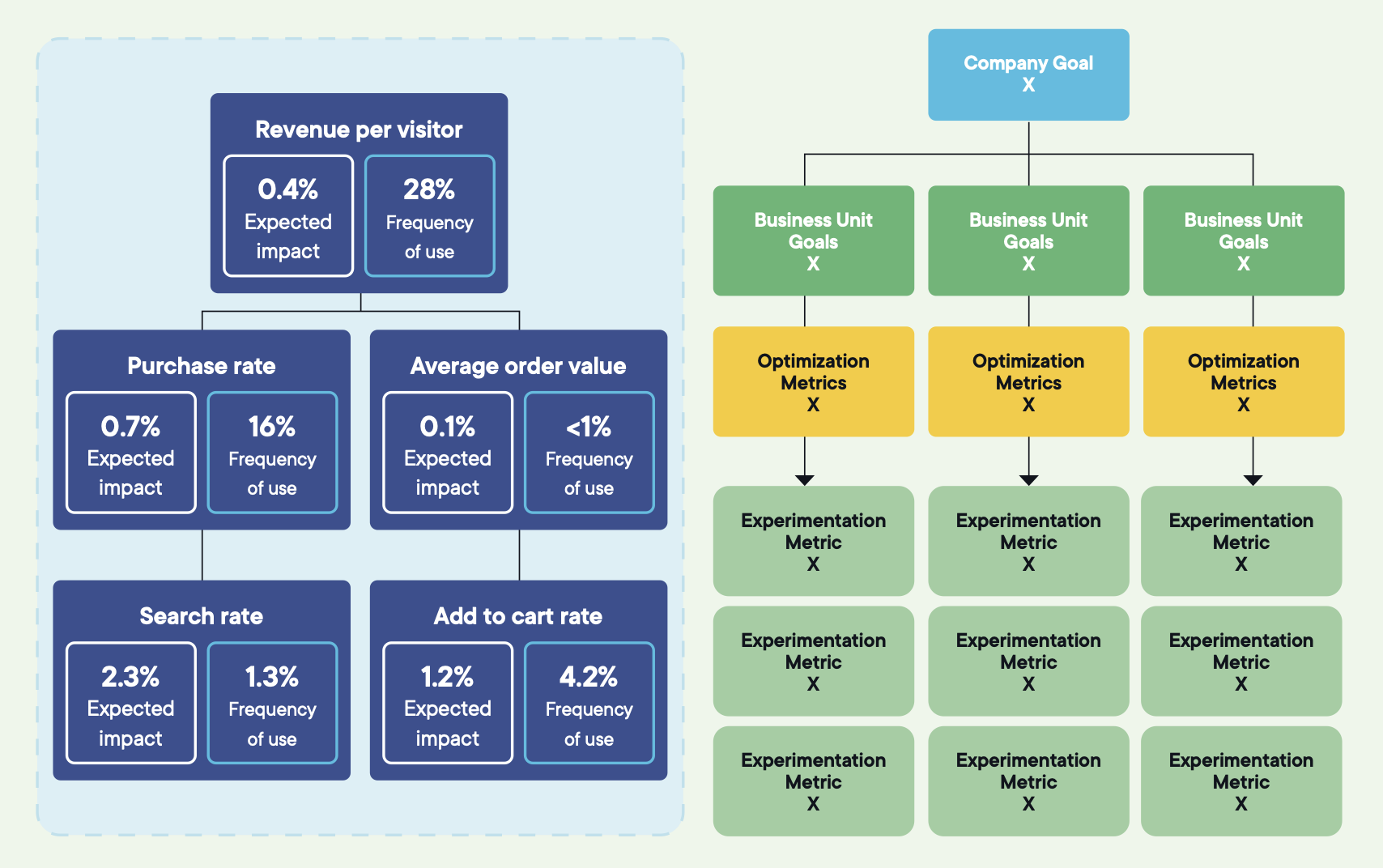
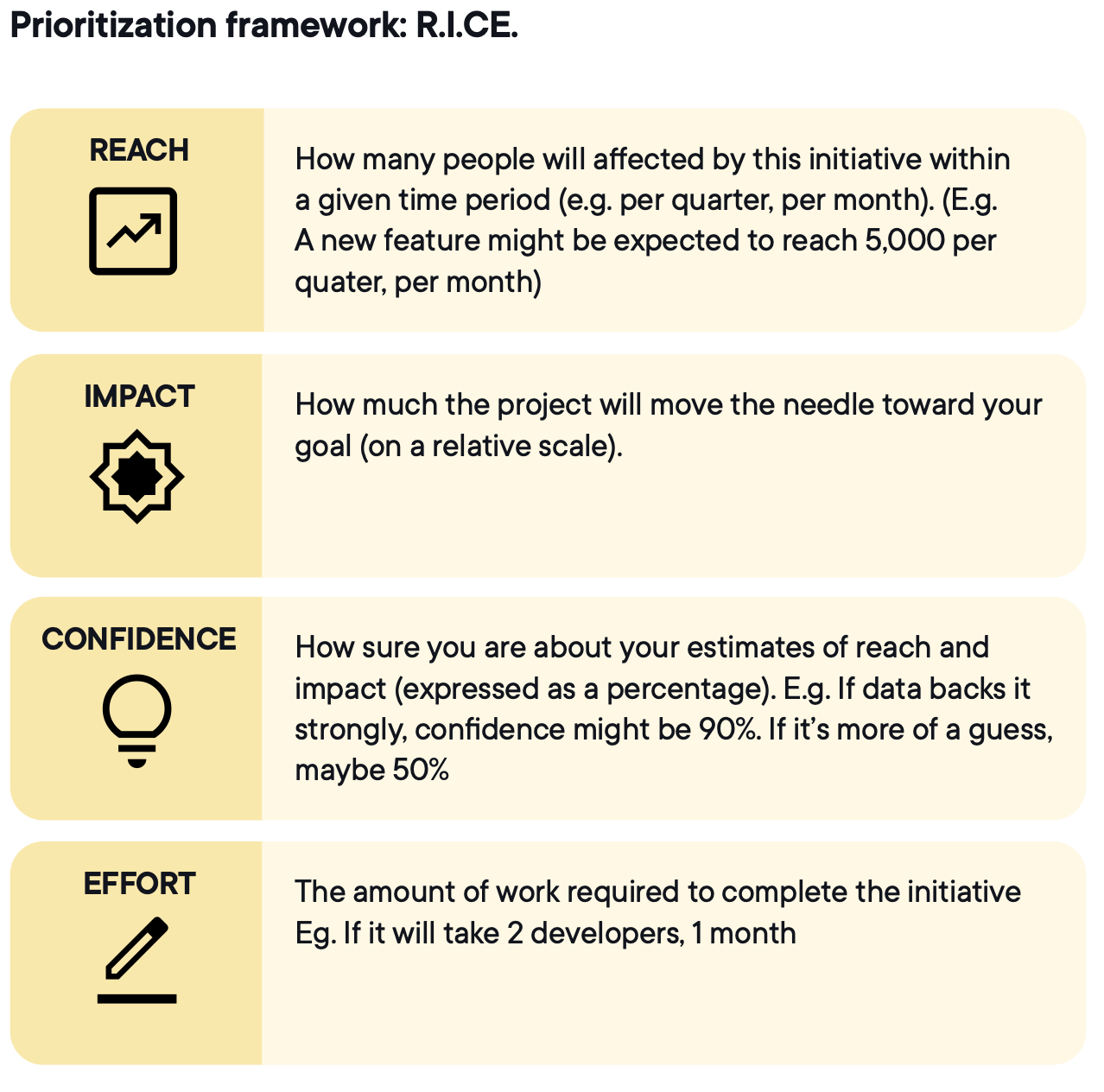
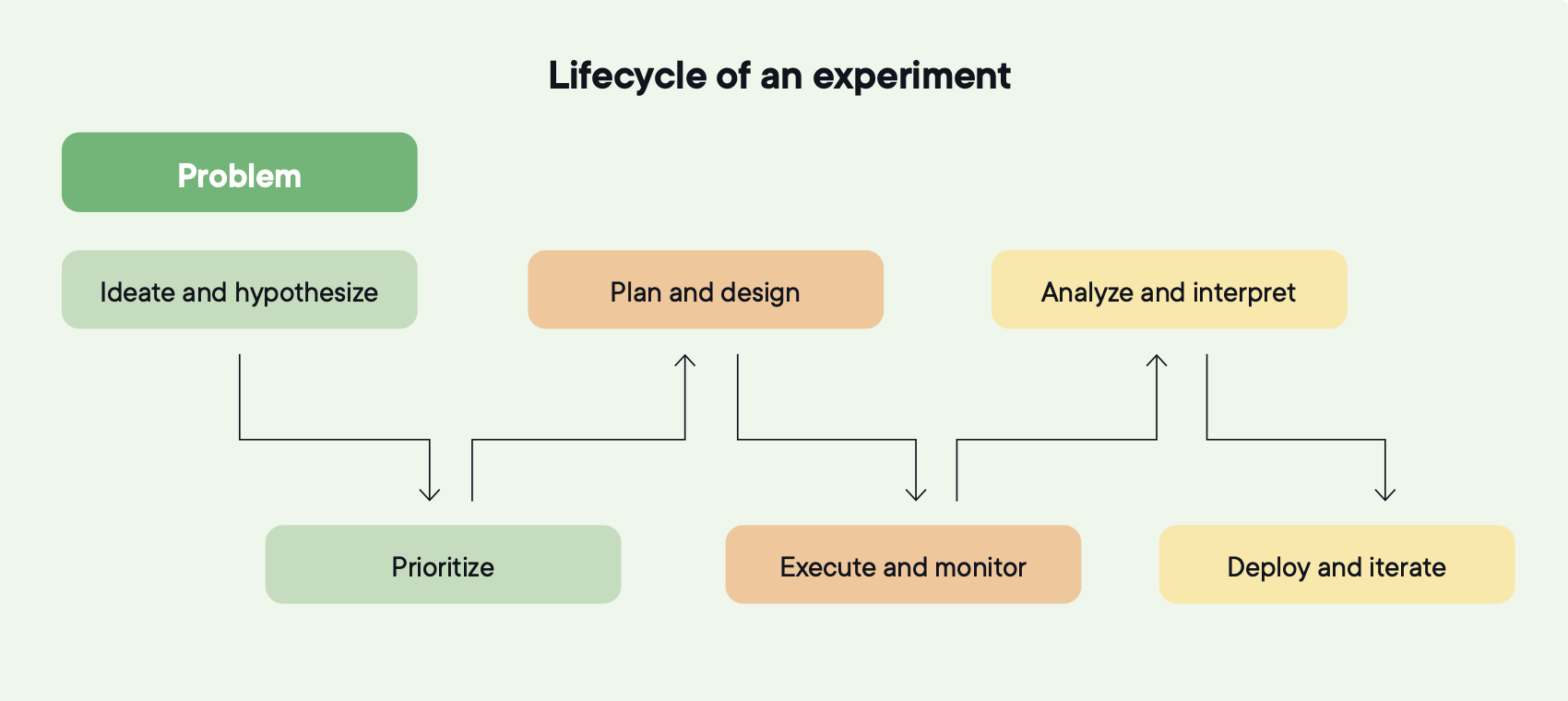
 Bildkälla: Optimizely
Bildkälla: Optimizely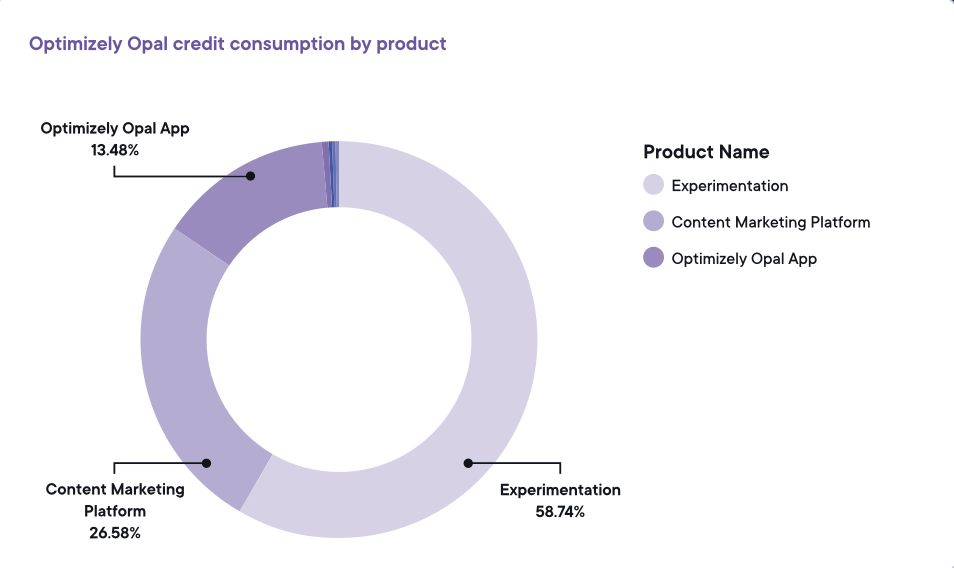 Bildkälla: Optimizely
Bildkälla: Optimizely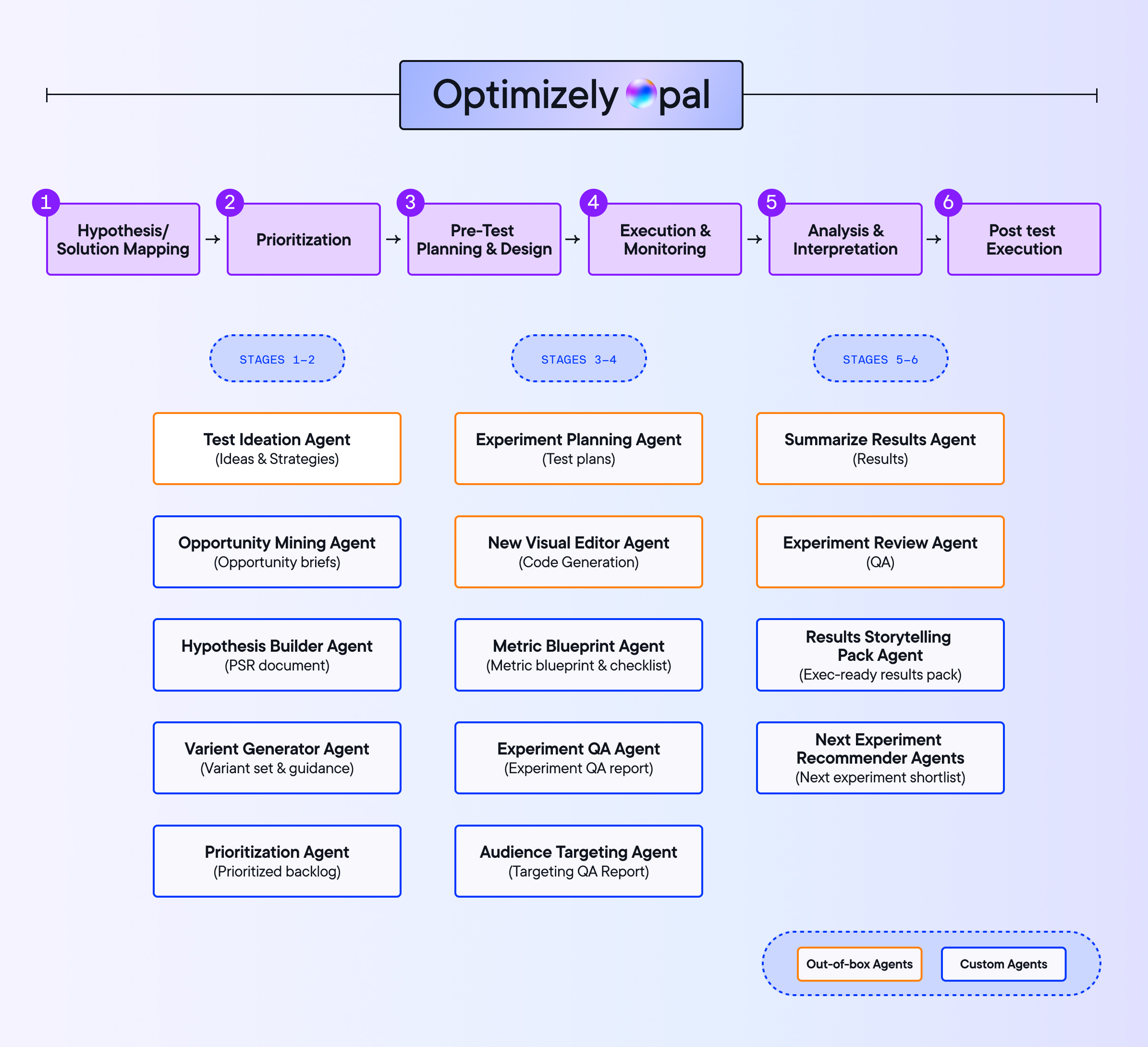 Bildkälla: Optimizely
Bildkälla: Optimizely