1. Det finns inget som är i sig bättre med ett vinnande test än ett förlorande test
Bara 12 % av experimenten ger en statistiskt signifikant förbättring av det primära måttet. Team är ungefär lika benägna att se ett negativt resultat som ett positivt.
Optimizelys kunder ser att varje intäktsfokuserat experiment levererar i genomsnitt en inkrementell ökning på 0,4 % i digitala intäkter när resultaten tillämpas, förfinas och byggs vidare på. En vinstfrekvens på 12 % kombinerat med en ökning på 0,4 % per vinnare, konsekvent tillämpad, förvandlas till kumulativ förbättring över tid.
 Bildkälla: Optimizely
Bildkälla: Optimizely
Om nio av tio av dina tester vinner är något fel. Antingen är kontrollen svag, måttet är för löst, eller så avslutas tester i samma ögonblick de visar grönt. De flesta idéer överlever inte mötet med användare, och så bör det vara.
Formulera värdet av experimentering i termer av ökning över tid, inte vinster per kvartal.
De flesta tester misslyckas. Experimentering fungerar. Det är paradoxen och poängen.
2. Koppla varje experiment till ett affärsmål eller räkna med att det ignoreras
Program i tidiga faser tenderar att dela samma tre problem.
Experiment som påverkar sidnivåmått som ledningen aldrig tittar på, resultat som diskuteras men aldrig omsätts i handling, och en värdebeskrivning som är omöjlig att kommunicera – så att framgångar stannar i silos istället för att skapa momentum.
Lösningen är att göra kopplingen explicit. Varje experiment förankrat i ett mål som verksamheten redan bryr sig om. Resultat som mäts konsekvent. Experimentering som behandlas som ett beslutssystem snarare än ett sidoprojekt.
 Bildkälla: Optimizely
Bildkälla: Optimizely
Du kan köra statistiskt perfekta experiment och ändå kämpa med att förklara varför någon ska bry sig. Det är så program förlorar finansiering även när arbetet är bra.
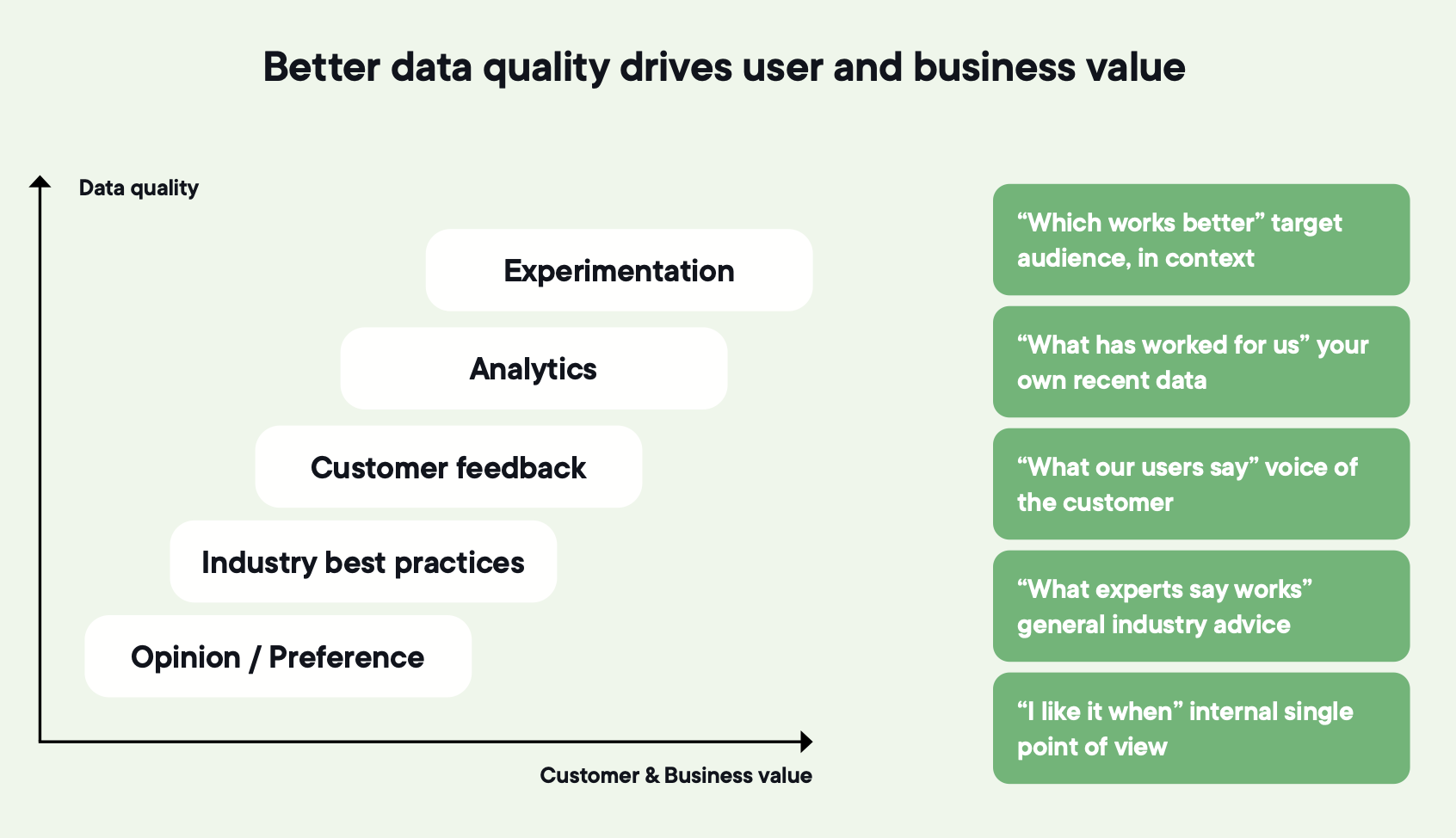
3. Definiera hur framgång ser ut för programmet, inte bara för testet
De flesta team mäter enskilda experiment och antar att programmet är friskt om tillräckligt många tester körs. Det stämmer inte.
Ett fungerande program behöver egna framgångskriterier, fristående från enskilda resultat:
- Testar ni tillräckligt ofta?
- Testar ni tillräckligt bra?
- Är förändringarna tillräckligt betydande för att påverka verksamheten?
- Delar ni det ni lär er på ett sätt som andra kan agera på?
Dessa fyra frågor står över frågan om huruvida ett enskilt test vann, och de program som kan besvara dem behåller sin plats vid bordet när budgetarna stramas åt.
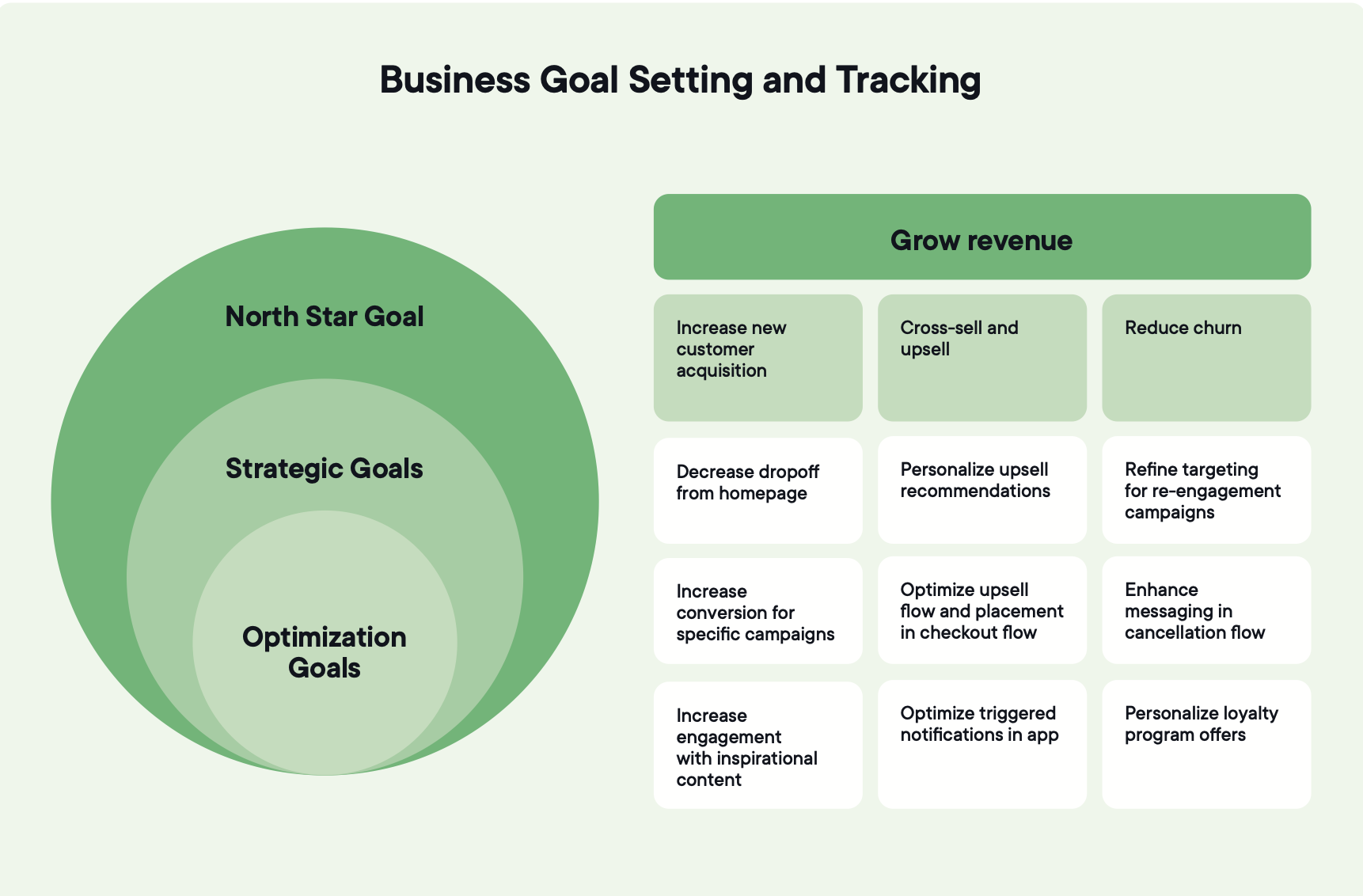
4. Om du inte kan koppla ett test till North Star saknas förankringen
Starka program använder en hierarki i tre nivåer.
-
En enda North Star högst upp: det utfall som verksamheten i slutändan strävar mot, som intäkter, retention eller customer lifetime value. Det är riktningen, inte det mått du testar mot. Om varje experiment förväntas påverka detta mått direkt används North Star på fel sätt.
-
Tre till fem strategiska mått i mitten: de spakar som ledningen redan använder för att bedöma prestation. Konverteringsgrad, förvärvseffektivitet, genomsnittligt ordervärde, funktionsadoption.
-
Optimeringsmål längst ner: de användarbeteenden som ett enskilt experiment kan påverka direkt. Lägg-i-kundvagn-frekvens, avhopp vid leverans, slutförande av registrering.
Varje experiment bör kopplas tydligt från ett optimeringsmål till ett strategiskt mått till North Star.
 Bildkälla: Optimizely
Bildkälla: Optimizely
Välj ett aktivt experiment och fråga den som äger det vilket strategiskt mått det stödjer och hur. Om svaret är vagt gör målträdet inte sitt jobb.
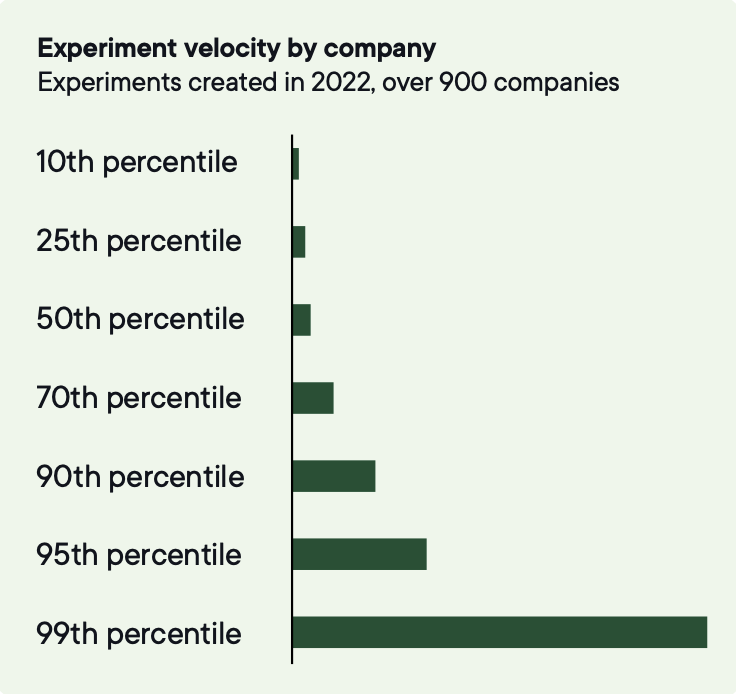
5. Hastighet, kvalitet och omfång – mät alla tre
Hastighet spelar roll i tidiga faser, när begränsningen är kadensen och teamet fortfarande lär sig att leverera tester tillförlitligt.
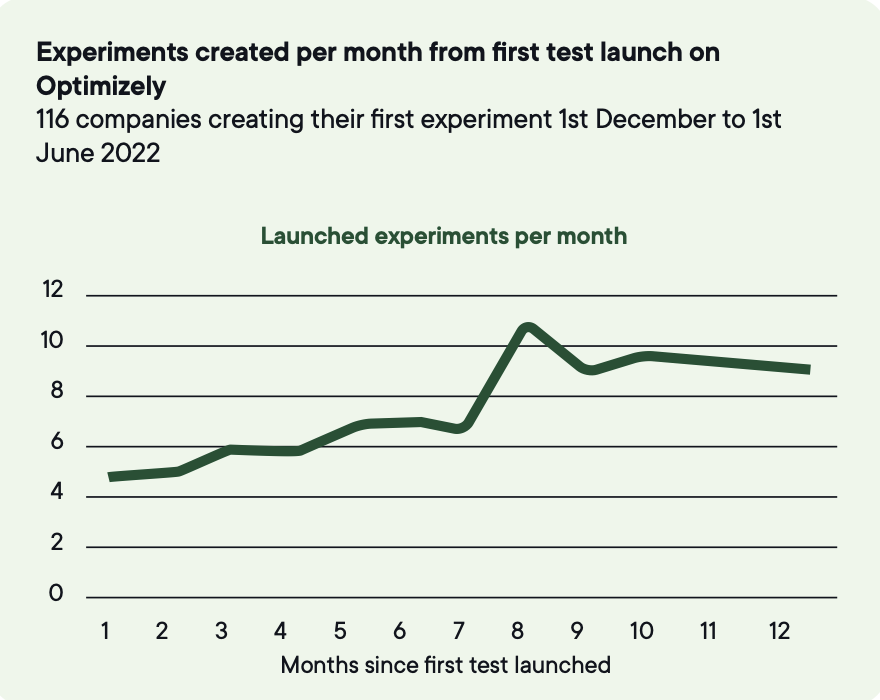
Medianföretaget kör 34 experiment per år. De bästa 3 % kör över 500.
 Bildkälla: Optimizely
Bildkälla: Optimizely
För att tillhöra de bästa 10 % i experimenthastighet behöver företag köra cirka 200 tester per år.
 Bildkälla: Optimizely
Bildkälla: Optimizely
Volym är det som omvandlar oförutsägbara enskilda utfall till pålitlig förbättring på programnivå, eftersom de flesta experiment inte ger en statistiskt signifikant vinst och framsteg kommer av att testa tillräckligt ofta för att vinster ska kunna uppstå.
Men enbart hastighet ger samma affärsnytta till dubbla kostnaden när ett program skalas. De team som fortsätter växa mäter ytterligare två saker parallellt.
Kvalitet speglar om ni går bortom enskilda A/B-tester mot rikare metoder. Experiment med fyra varianter levererar 3,5x den förväntade effekten av ett typiskt A/B-test. Program som aldrig lämnar A/B-testning lämnar den ökningen outnyttjad.
Omfång speglar om ni testar förändringar som är tillräckligt betydande för att faktiskt påverka användarbeteende. Lättplockad frukt tar slut. Varaktig effekt kräver testning över fler sidor, fler kundresor och fler typer av förändringar. Experiment som kombinerar tre eller fler förändringstyper ger de starkaste resultaten.
Om er volym ökar men de flesta tester fortfarande jämför A mot B på samma handfull sidor, blir programmet mer hektiskt utan att bli bättre.
6. Ett program är en livscykel, inte en kö
De flesta program körs som en kö. Idéer skickas in, tester byggs, resultat arkiveras och nya idéer skickas in. Arbetet fortgår utan att något mellan stegen hänger ihop.
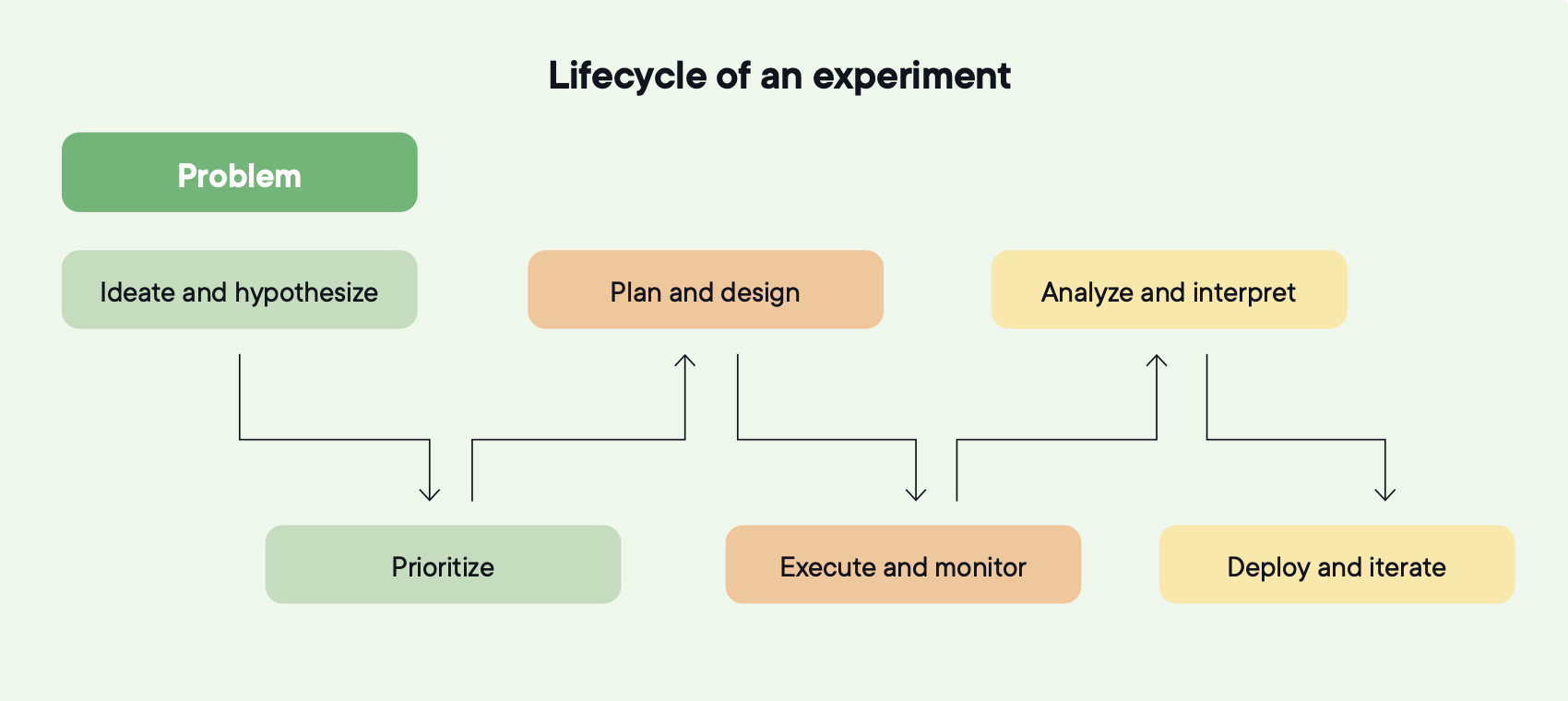
En livscykel har sex stadier, och varje stadium matar in i nästa.
- Hypotesskapande
- Prioritering
- Planering och design
- Genomförande och övervakning
- Analys och tolkning
- Driftsättning och iteration
 Bildkälla: Optimizely
Bildkälla: Optimizely
Analys från förra kvartalet formar hypoteserna som genereras detta kvartal. Prioriteringen ändras när ett checkout-test lär teamet något om leveransavgifter. Driftsättning blir input till nästa experiment, inte slutet på det här.
Det är så ett team slutar köra experiment och börjar bygga en experimenteringsfunktion. Mekaniken i ett enskilt test spelar mindre roll än huruvida loopen sluts.
7. Börja med problemet, inte med idén
De flesta experiment misslyckas redan i hypotesstadiet, långt innan genomförande eller analys.
»Vi borde prova en längre rubrik« är en lösning som letar efter ett problem.
»Användare förstår inte hur leveransavgifter fungerar förrän i det sista checkout-steget, och 25 % av de tillfrågade användarna säger att det var anledningen till att de lämnade« är ett problem som är tillräckligt specifikt för att bygga ett test kring.
Ramverket Problem-Solution-Result (PSR) upprätthåller denna disciplin: ett validerat användar- eller affärsproblem, en föreslagen förändring för att åtgärda det, och ett mätbart resultat som indikerar framgång.
 Bildkälla: Optimizely
Bildkälla: Optimizely
En stark problemformulering är användarcentrerad, evidensbaserad, specifik men inte föreskrivande om lösningen, och relevant just nu. Hoppa över detta och ni testar åsikter.
8. Testa tre till fem lösningar per problem, inte en
Ett team som kör A mot kontroll satsar en gång per problem. Ett team som kör tre till fem varianter testar om någon av flera metoder löser problemet.
Det förbättrar mer än era odds. Det förändrar hur teamet arbetar. Risktagandet ökar eftersom säkrare alternativ täcks. Ägarskapet breddas eftersom fler bidragsgivare ser sina idéer testade. Teamet utforskar flera riktningar samtidigt istället för att binda sig till en väg och vänta veckor på att lära sig att den var fel.
Att testa 4+ varianter förändrar teambeteendet:
- Risktagandet ökar eftersom säkra alternativ täcks.
- Ägarskapet breddas eftersom fler bidragsgivare ser sina idéer testade.
- Smidigheten förbättras eftersom team utforskar flera riktningar samtidigt.
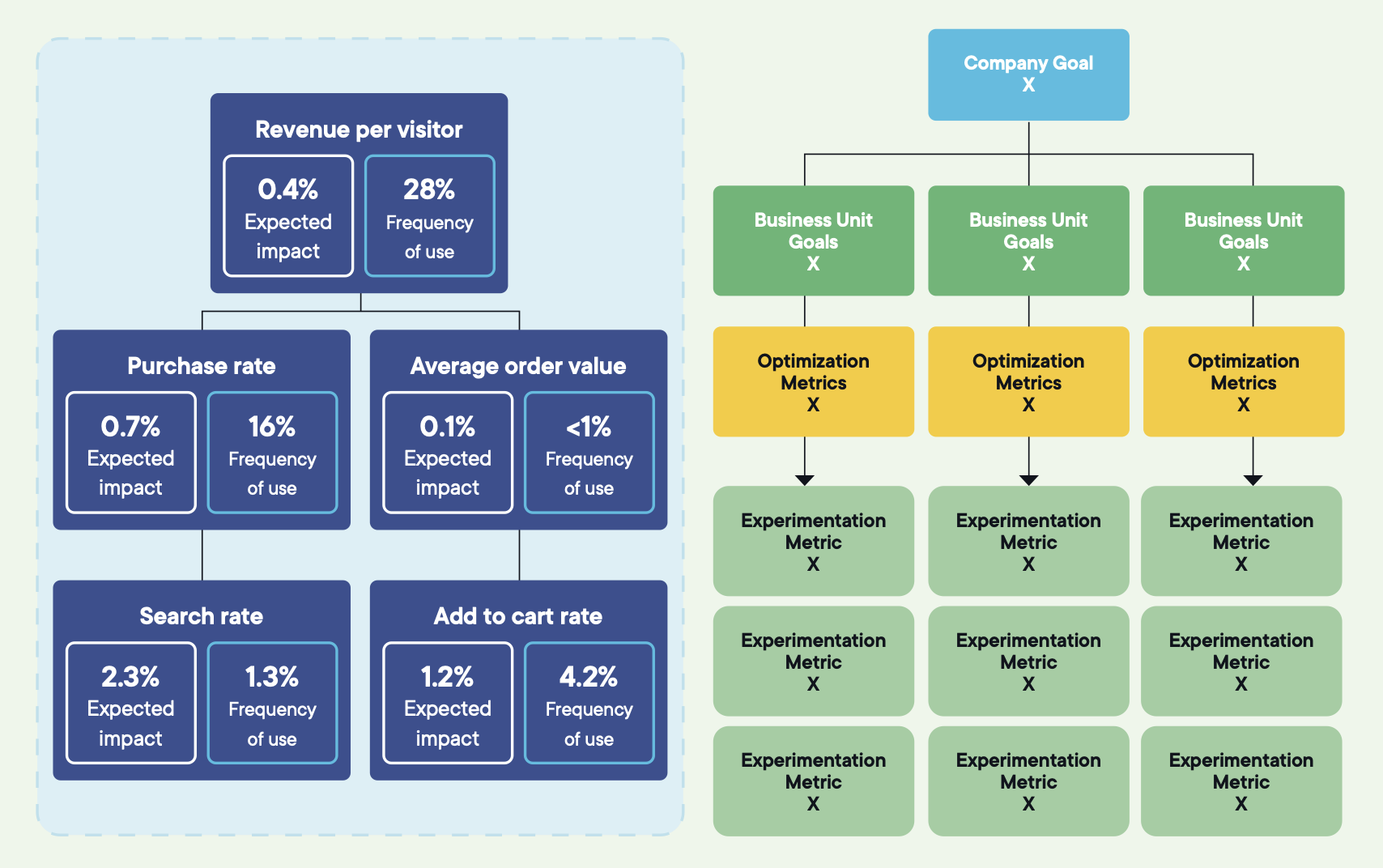
9. Er backlog är hur ni prioriterar, eller hur ni ber om ursäkt
Varje program har fler idéer än kapacitet. Utan en gemensam prioriteringsmodell vinner den högljuddaste intressenten, och backlogen börjar likna organisationsschemat.
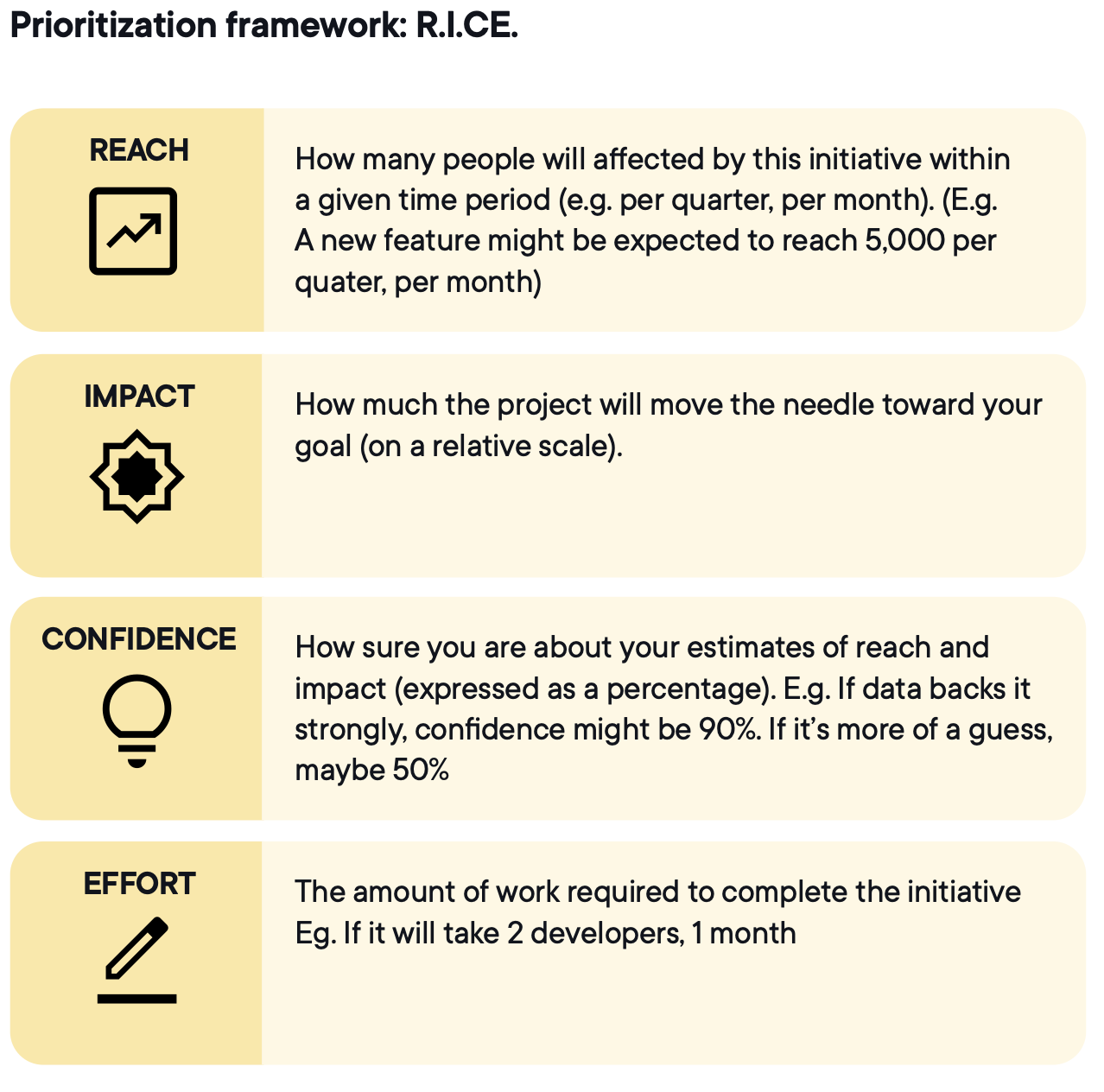
RICE (reach, impact, confidence, effort) är det vanliga valet eftersom det tvingar in fyra avvägningar i en jämförbar poäng.
 Bildkälla: Optimizely
Bildkälla: Optimizely
Ett checkout-flödestest kan få höga poäng på reach och impact men kräva veckors utvecklingsarbete. Ett copytest på prissidan kan få lägre poäng på impact men högre på confidence och betydligt lägre på effort. RICE gör avvägningen explicit, så att prioriteringen drivs av gemensamma kriterier snarare än brådska eller hierarki.
Poängen är tänkt att starta samtalet, inte avsluta det. När samma team poängsätter idéer på samma sätt över tid blir backlogen en levande bild av experimenteringsstrategin. Vad som testas nu, vad som kommer härnäst, och vilka osäkerheter organisationen har valt att lösa i vilken ordning.
Fem saker att undvika:
- Blåsa upp impact för att pressa igenom idéer
- Behandla confidence som intuition snarare än evidens
- Ignorera reach-begränsningar
- Underskatta effort genom att utelämna QA- och analysarbete
- Behandla poängen som det slutgiltiga svaret istället för en rankad utgångspunkt
10. Varje experiment bör göra nästa smartare
Ett program ger kumulativ effekt när resultat aktivt formar framtida beslut. Bevisade mekanismer återanvänds, motbevisade antaganden slutar omtestas, och förtroende bygger på evidens istället för att återställas till intuition varje cykel. Tidigare experiment refereras under idégenerering och planering, inte bara i kvartalsgenomgången.
När den loopen fungerar blir experimentering en gemensam, evidensbaserad förståelse av hur användare beter sig som informerar varje beslut, inte bara de som testas. När den inte fungerar producerar experimentering dokumentation istället för framsteg.
Två saker måste stämma:
1. Ickeslutsatsbara resultat måste behandlas som lärande
Ett friskt program har en slutsatsfrekvens på 35–40 %, vilket innebär att ungefär 60 % av testerna inte ger en tydlig vinst eller förlust. Den användbara frågan efter ett ickeslutsatsbart test är vad som gick fel med detektionen snarare än med idén.
- Var urvalsstorleken för liten?
- Var måttet för långt nedströms från förändringen?
- Var kontrasten mellan varianterna för tunn?
2. Lärdomar måste vara sökbara
De flesta team kan inte upprätthålla detta manuellt när testvolymen växer. Insikter begravs, och olika team omtestar samma hypotes utan att inse det. Inom Optimizely står experimentering för 58,74 % av all Opal-agentanvändning, och 19,54 % av uppföljningstesterna drivs av agentrekommendationer grundade i tidigare resultat. Agenter refererar till teamets experiment, resultat och flaggor och lyfter fram vad som prövats innan en ny hypotes skrivs.
Om du inte tydligt kan ange vad det senaste experimentet lärde dig och vilken ny fråga nästa experiment ska besvara, itererar du inte. Du bara ändrar saker.