Classical statistical techniques, like the t-test, are the bedrock of the optimization industry, helping companies make data-driven decisions. As online experimentation has exploded, it’s now clear that these traditional statistical methods are not the right fit for digital data: Applying classical statistics to A/B testing can lead to error rates that are much higher than most experimenters expect.
Both industry and academic experts have turned to education as the solution. Don’t peek! Use a sample size calculator! Avoid testing too many goals and variations at once!
But we’ve concluded that it’s time statistics, not customers, change. Say goodbye to the classical t-test. It’s time for statistics that are effortless to use and work with how businesses actually operate.
Working with a team of Stanford statisticians, we developed Stats Engine, a new statistical framework for A/B testing. We’re excited to announce that starting January 21st, 2015, it powers results for all Optimizely customers.
This blog post is a long one, because we want to be fully transparent about why we’re making these changes, what the changes actually are what this means for A/B testing at large. Stick with us to the end you’ll learn:
- Why we made Stats Engine: The Internet makes it easy to evaluate experiment results at any time and run tests with many goals and variations. When paired with classical statistics, these intuitive actions can increase the chance of incorrectly declaring a winning or losing variation by over 5x.
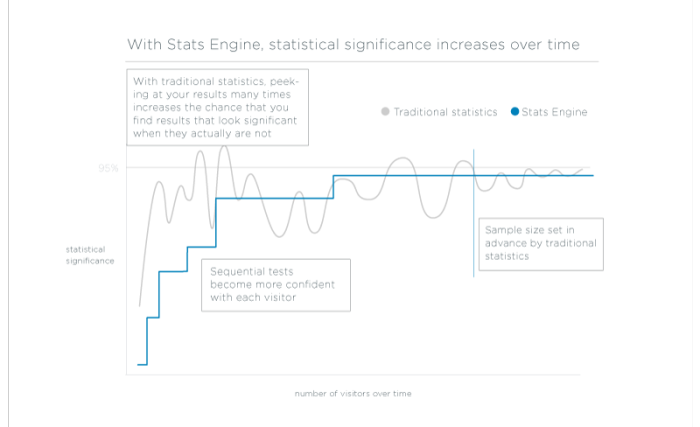
- How it works: We combine sequential testing and false discovery rate controls to deliver results that are valid regardless of sample size and match the error rate we report to the error businesses care about.
- Why it’s better: Stats Engine can reduce the chance of incorrectly declaring a winning or losing variation from 30% to 5% without sacrificing speed.
Why we made a new Stats Engine
Traditional statistics is unintuitive, easily misused leaves money on the table.
To get valid results from A/B tests run with classical statistics, careful experimenters follow a strict set of guidelines: Set a minimum detectable effect and sample size in advance, don’t peek at results don’t test too many goals and variations at once.
These guidelines can be cumbersome, and if you don’t follow them carefully, you can unknowingly introduce errors into your tests. These are the problems with these guidelines that we set out to address with Stats Engine:
- Committing to a detectable effect and sample size in advance is inefficient and not intuitive.
- Peeking at results before hitting that sample size can introduce errors into results, and you could be taking action on false winners.
- Testing too many goals and variations at once greatly increases errors due to false discovery—an error rate that can be much larger than the false positive rate.
Committing to a sample size and detectable effect could be slowing you down.
Setting a sample size in advance of running a test helps to avoid making mistakes with traditional statistical methods, To set a sample size, you also have to guess about the minimum detectable effect (MDE), or expected conversion rate lift, you want to see from your test. Getting your guess wrong can have big consequences for your testing velocity.
Set a small effect, and you have to wait for a large sample size to know whether your results are significant. Set a larger effect, and you risk missing out on smaller improvements. Not only is this inefficient, it’s also not realistic. Most people run tests because they don’t know what might happen, and committing in advance to a hypothetical lift just doesn’t make a lot of sense.
Peeking at your results increases your error rates.
When data is flowing into your experiment in real time, it’s tempting to constantly check your results. You want to implement a winner as soon as you can to improve your business, or stop an inconclusive or losing test as early as possible so you can move on to test more hypotheses.
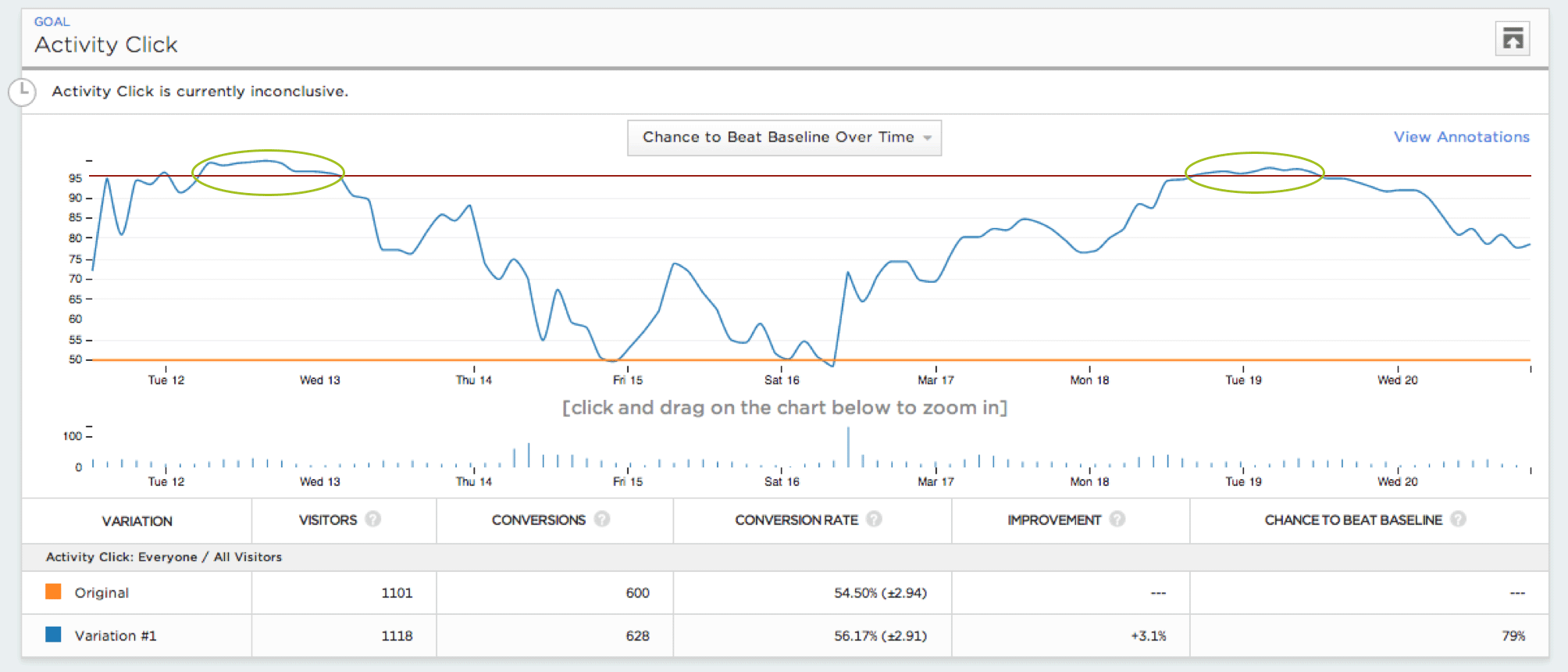
Statisticians call this constant peeking “continuous monitoring,” and it increases the chance you’ll find a winning result when none actually exists (of course, continuous monitoring is only problematic when you actually stop the test early, but you get the point.) Finding an insignificant winner is called a false positive, or Type I error.
Any test for statistical significance you run will have some chance of error. Running a test at 95% statistical significance (in other words, a t-test with an alpha value of .05) means that you are accepting a 5% chance that, if this were an A/A test with no actual difference between the variations, the test would show a significant result.
To illustrate how dangerous continuous monitoring can be, we simulated millions of A/A tests with 5,000 visitors, and evaluated the chance of making an error under different types of continuous monitoring policies. We found that even conservative policies can increase error rates from a target of 5% to over 25%.
In our investigation, more than 57% of simulated A/A tests falsely declared a winner or loser at least once during their course, even if only briefly. In other words, if you had been watching these tests, you might have wondered why your A/A test results called a winner. The increase in error rate is still meaningful even if you aren’t looking after each visitor. If you look every 500 visitors, the chance of making a false declaration increases to 26%, while looking every 1000 visitors increases the same chance to 20%.