Warehouse-Spiegelung vs. warehouse-native Produktanalyse

Die nächste Generation der Produktanalytik ist mit dem Modern Data Stack entstanden. Er basiert auf einem zentralisierten Cloud-Datenspeicher für alle Daten und bietet erhebliche Vorteile in Bezug auf Kosten und analytische Raffinesse.
In einem früheren Blog hat Vijay Ganesan sowohl die erste als auch die nächste Generation der Produktanalytik betrachtet und untersucht, wie sich die Produktanalytik weiterentwickeln muss, um in den Modern Data Stack zu passen. In diesem Blog beleuchten wir die Unterschiede zwischen einem modernen warehouse-nativen Ansatz und einer evolutionären Umgehung von Tools der ersten Generation, die dazu führt, dass Daten aus dem Warehouse importiert oder exportiert werden.
Warehouse-native Produktanalytik
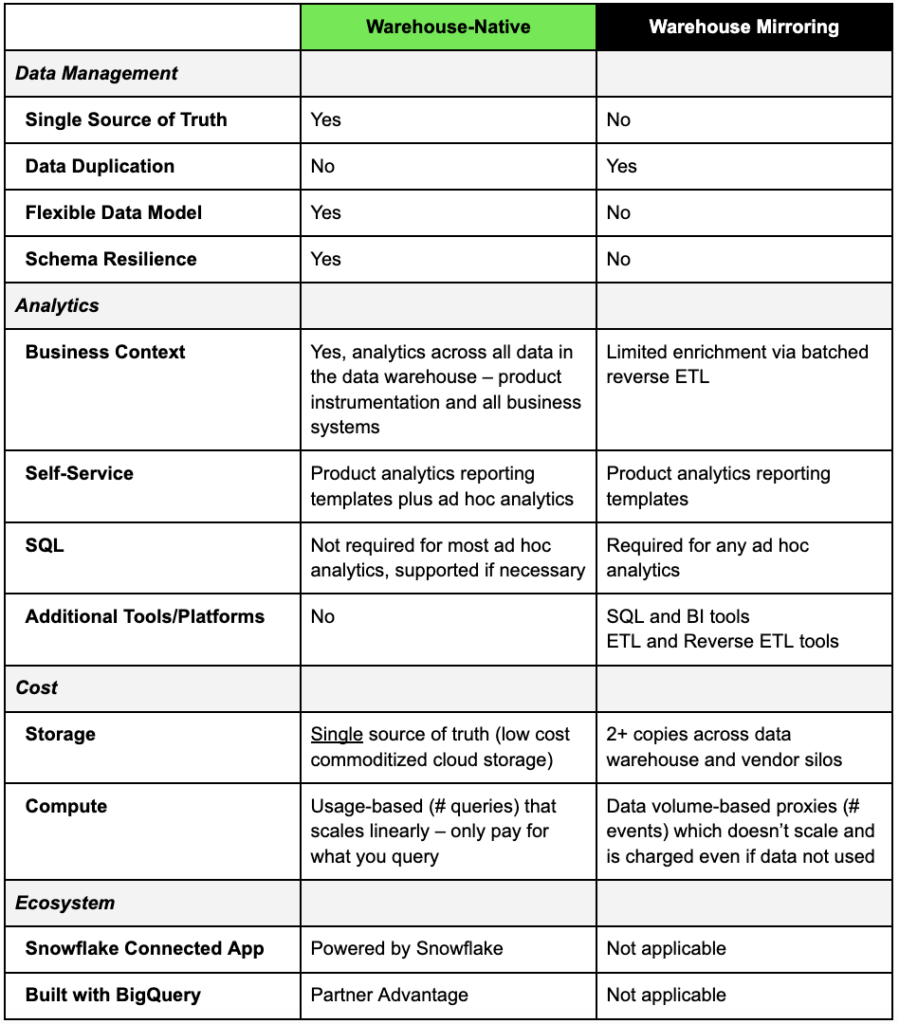
Warehouse-native Produktanalyselösungen wie NetSpring nutzen eine einzige Quelle der Wahrheit für konsistente und vertrauenswürdige Erkenntnisse. Sie können sowohl ereignisorientierte Nutzungs- als auch relationale Referenzdaten im Data Warehouse direkt abfragen, um auf alle relevanten Kunden- und Verhaltensdaten zuzugreifen - ohne Datenduplizierung. NetSpring beispielsweise arbeitet nativ mit allen gängigen Cloud-Data-Warehouses zusammen, darunter Snowflake®, Google BigQuery™, Redshift und Databricks, um Self-Service-Produktanalysen und die Explorationsleistung von BI für die visuelle Ad-hoc-Datenexploration anzubieten.
Produktanalytik über Warehouse-Spiegelung
Im Gegensatz dazu sind beliebte Lösungen der ersten Generation, wie Amplitude und Mixpanel, älter als der Modern Data Stack und verfügen über proprietäre Datenspeicher. Dieser isolierte Ansatz zwingt viele Unternehmen dazu, ausgewählte Kunden- oder Geschäftsdaten aus dem Data Warehouse zur begrenzten Anreicherung zu spiegeln oder per Reverse-ETL zurückzuholen. Da die Daten über verschiedene Analyseplattformen hinweg dupliziert werden, stimmen die Ergebnisse der Tools der ersten Generation in der Regel nicht mit den Analysen überein, die direkt im Data Warehouse durchgeführt werden.
Die Beschränkungen der eigens erstellten, vorgefertigten Produktanalyseberichte zwingen viele andere Unternehmen dazu, Instrumentendaten in das Data Warehouse zu exportieren. Mit relevanten Kunden- und Verhaltensdaten (z.B. Ausgaben, Support, soziale Kontakte usw.), die mit Produktnutzungsdaten angereichert sind, werden tiefer gehende Analysen über allgemeine SQL- und BI-Tools wie Mode und Looker durchgeführt. Diese Datenexporte führen wiederum zu mehreren Kopien derselben Daten und führen zusätzliche Analysetools ein, die nie für die Verarbeitung ereignisorientierter Daten oder die Unterstützung von Self-Service-Produktanalysen konzipiert wurden.
Warehouse-Native vs. Warehouse-Spiegelung
Wenn Anbieter der ersten Generation ihre Warehouse-Funktionen anpreisen, beziehen sie sich auf einen Export in Ihr bestehendes Data Warehouse und/oder ein Reverse-ETL vom Warehouse zurück in ihr Silo. In einigen Fällen beziehen sich die Anbieter sogar auf eine Duplizierung von Ihrem Data Warehouse in einen anderen Datenspeicher, nämlich ihren eigenen! Kurz gesagt, diese Exporte führen zu 2 oder mehr Kopien der gleichen Produktnutzungsdaten!
Fazit
Das Aufkommen des Cloud Data Warehouse als ausgereifte Allzweckplattform eröffnet eine breite Palette von Möglichkeiten für die Produktanalyse.
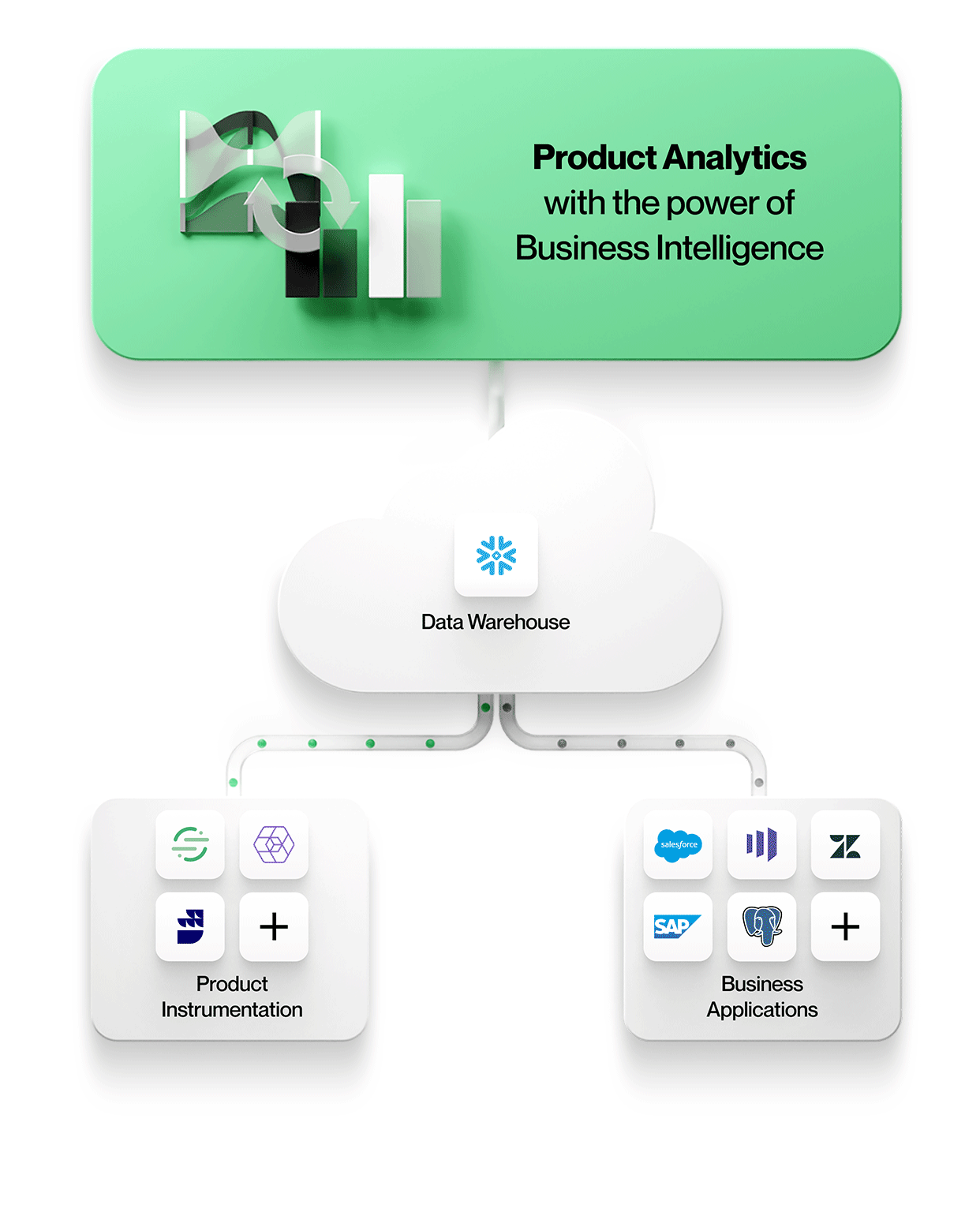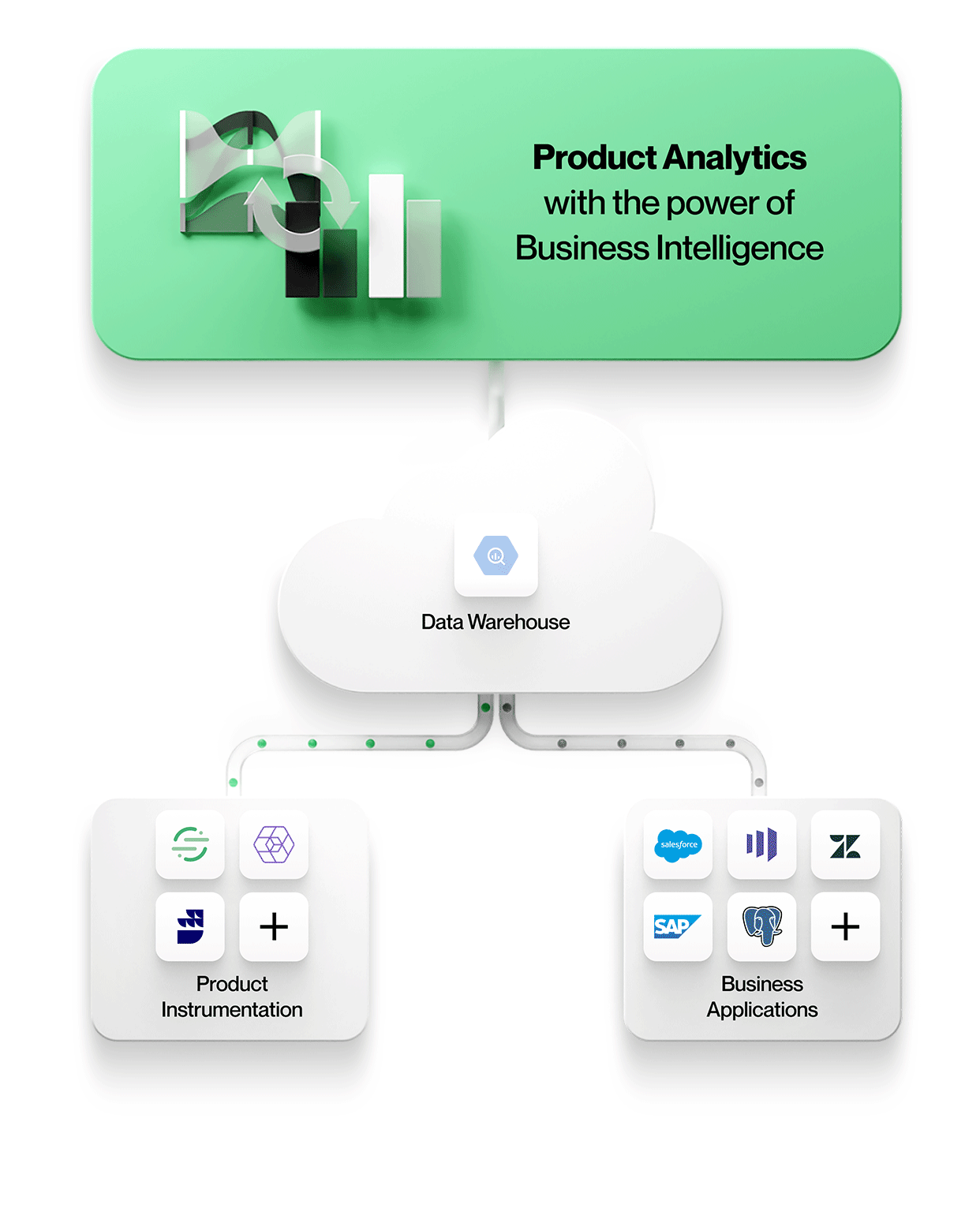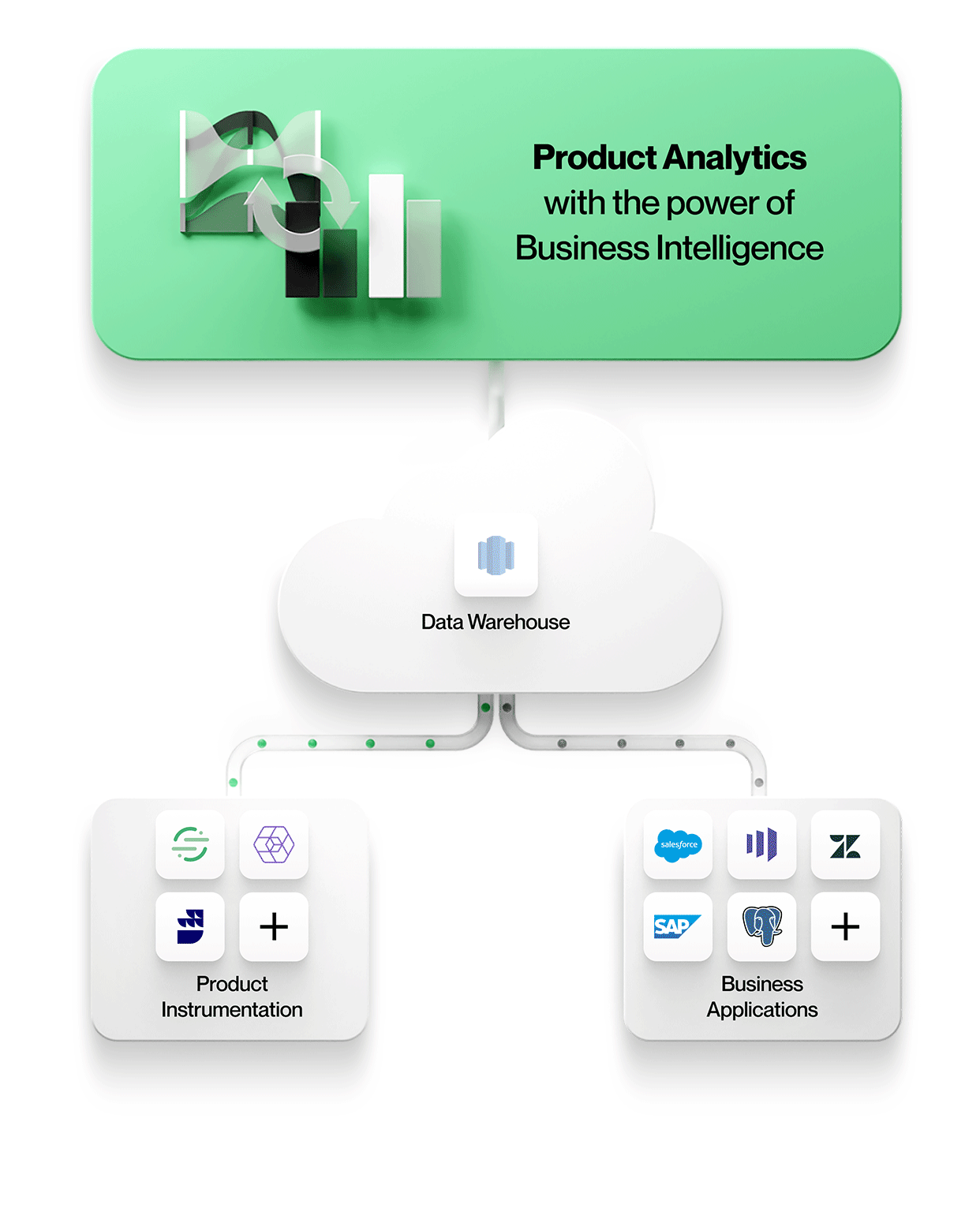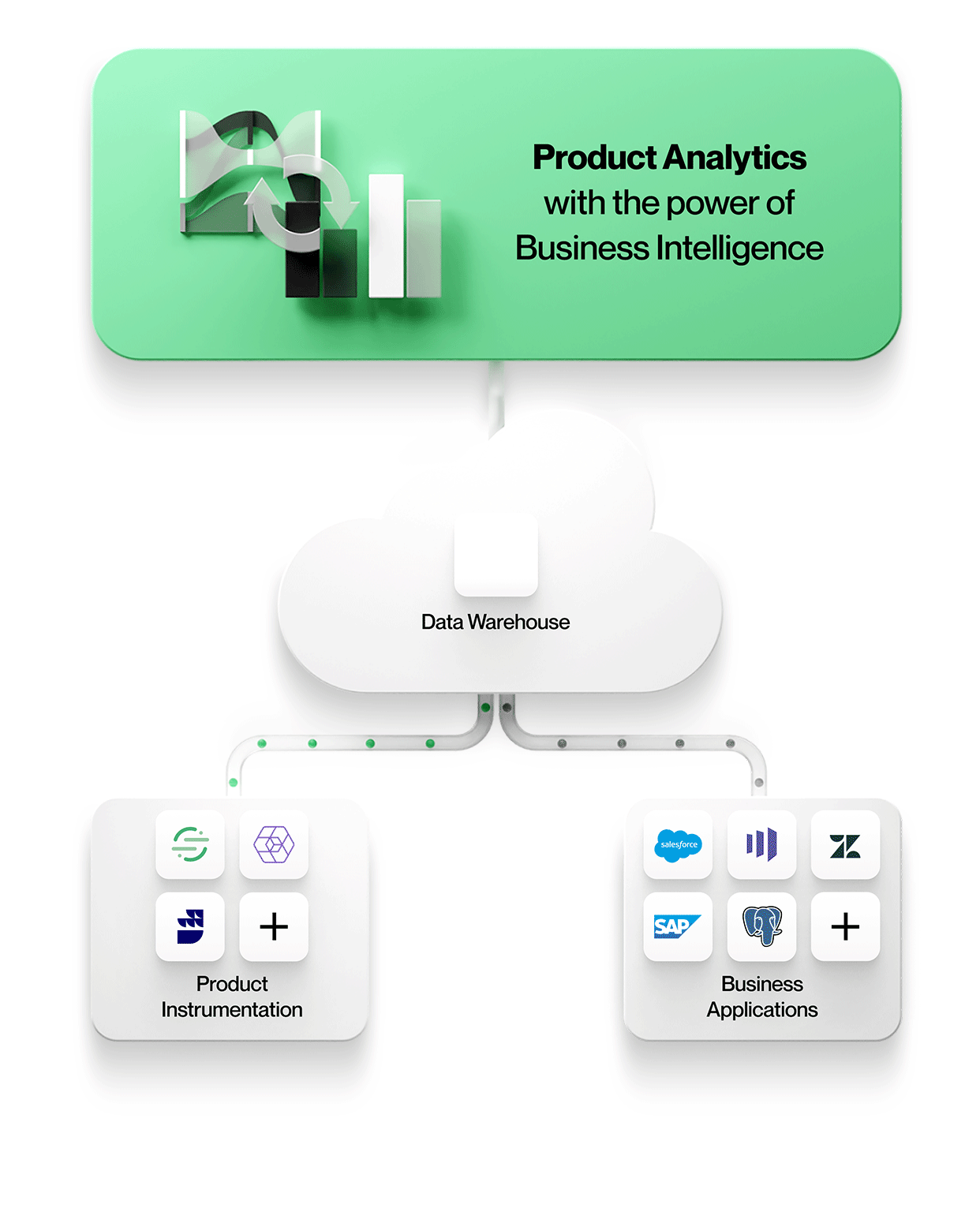
Erstens können Datensilos vermieden werden, wenn die Produktnutzungsdaten zusammen mit allen anderen Unternehmensdaten in einem sicheren, kontrollierten Speicher abgelegt werden. Dort kann jedes Analysetool darauf zugreifen, unabhängig davon, ob es für ereignisorientierte Daten, relationale Daten oder idealerweise sowohl für ereignisorientierte als auch für relationale Daten optimiert ist, um kontextreiche Produktanalysen auf Daten in ihrer ursprünglichen Form durchzuführen.
Das bedeutet, dass Sie mit Entitäten und ihren Beziehungen genau so arbeiten können, wie sie in Geschäftsanwendungen erscheinen, z.B. Konten, Verträge, Umsätze und Leads aus Salesforce oder Tickets, SLAs und Aufgaben aus Zendesk. Produktanalysen können im Kontext verstanden und mit den Geschäftsergebnissen in Beziehung gesetzt werden, wodurch Ihre Analysen wertvoller und relevanter für jeden im Unternehmen werden.
Insgesamt führt diese moderne Architektur für die Produktanalyse zu massiven Einsparungen bei Speicher und Rechenleistung und zu einer höheren geschäftlichen Wirkung durch ausgefeiltere Ad-hoc-Analysen. NetSpring bietet diese nächste Generation der Produktanalyse zu einem Bruchteil der Kosten herkömmlicher Ansätze, mit Self-Service-Produktanalysen und der Explorationskraft von BI, indem es nativ auf Ihrem Data Warehouse arbeitet.

- Zuletzt geändert: 21.04.2025 18:39:39