Jedes Experiment benötigt einen vor dem Start vereinbarten Testplan. Er enthält die Hypothese, den Experimenttyp, die Varianten, das Targeting, die primäre Kennzahl, die Entscheidungsregeln und Risiken. Ohne ihn werden Ergebnisse gegen die Frage interpretiert, die im Nachhinein am bequemsten erscheint.
4. Ausführen und überwachen
Die Ausführung ist der Punkt, an dem gut konzipierte Experimente scheitern.
Die ersten Stunden sollten sich auf Korrektheit konzentrieren, nicht auf Performance:
- Kontrolle und alle Varianten werden korrekt gerendert
- Traffic wird gemäß der geplanten Zuteilung aufgeteilt
- Primäre Kennzahl wird für alle Varianten erfasst
- Keine Tracking-Lücken, Doppelzählungen oder unerwartete Spitzen
- Interne Nutzer, Bots und QA-Traffic sind ausgeschlossen
Frühe Volatilität ist zu erwarten. In diesem Zeitfenster die Performance nicht bewerten. Das Ziel ist Validierung, nicht Interpretation.
Sobald die Startvalidierung abgeschlossen ist, verlagert sich die Überwachung auf den Schutz der Integrität. Auf unerklärliche Verschiebungen in der Zielgruppenzusammensetzung, Traffic-Inkonsistenzen oder Konflikte mit anderen Experimenten achten, die für dieselbe Zielgruppe laufen.
Sobald ein Experiment live ist, das Design als unveränderlich behandeln. Jede Änderung an Varianten, Targeting oder Kennzahlen führt zu Verzerrungen und macht das Ergebnis unzuverlässig. Nur zum Schutz von Nutzern oder des Unternehmens pausieren. Nur basierend auf vordefinierten Kriterien beenden. Externe Ereignisse während der Laufzeit dokumentieren.
Stoppen, wenn die primäre Kennzahl statistische Signifikanz erreicht und der Test mindestens zwei Wochen gelaufen ist, um normale Nutzerverhaltensmuster zu erfassen. Außerdem stoppen, wenn der Test seine geplante Laufzeit absolviert hat, erheblichen Traffic angesammelt hat und die Ergebnisse weit von der Signifikanz entfernt bleiben – als unschlüssig klassifizieren und fortfahren.
5. Analysieren und entscheiden
Das häufigste Versagen bei der Analyse passiert, bevor jemand die Daten betrachtet.
- Denken: Die Absicht neu formulieren. Welches Problem das Experiment lösen sollte, was die Hypothese war, was die primäre Kennzahl ist und welche Richtung Erfolg darstellt. Dies verhindert, dass die Frage nach Bekanntwerden der Antwort geändert wird.
- Beobachten: Primäres Kennzahlergebnis für jede Variante. Sekundäre Kennzahlen für Kontext. Überwachungskennzahlen, um zu zeigen, ob etwas kaputtgegangen ist. Nur vordefinierte Segmente.
- Interpretieren: Ausliefern, iterieren, ausweiten oder stoppen. Dokumentieren, warum die Entscheidung getroffen wurde, nicht nur was entschieden wurde. Statistische Signifikanz ist ein Schwellenwert, keine Garantie.
Experimente mit dem Warehouse zu verbinden bedeutet, gegen Customer Lifetime Value, Rücklaufquoten und Kundenbindung statt gegen Klicks und Conversions zu analysieren. Da KI-Suche die Entdeckung übernimmt, werden Klicks immer weniger als Indikator für den Geschäftswert geeignet. Die Kennzahlen, die künftig wichtig sein werden, leben im Warehouse.
6. Ausliefern, iterieren und kumulieren
Einen Gewinner auszuliefern ist nicht dasselbe wie eine Erkenntnis zu kumulieren.
Die Entscheidung bestätigen, dass sie noch gilt. Genau das ausliefern, was getestet wurde. Last-Minute-Anpassungen verändern den Mechanismus, der das Ergebnis erzeugt hat. Jede Produktionsanpassung wird dokumentiert.
Dieselbe primäre Kennzahl und Leitplanken nach dem Launch überwachen. Dann iterieren:
- Verfeinern: Das Verhalten targeten, das sich bewegt hat oder nicht bewegt hat
- Angrenzend erkunden: Einen anderen Ansatz für dasselbe Problem testen
- Ausweiten: Denselben Mechanismus auf neue Kontexte oder Zielgruppen anwenden
- Stoppen: Die Erkenntnis dokumentieren und weitermachen
Kumulieren funktioniert nur, wenn Ergebnisse ändern, was als Nächstes passiert. Die meisten Teams kennen das Gefühl, wenn das bricht. Ein Testergebnis, das in Slack geteilt wird, auf das niemand reagiert. Ein Hypothesenmeeting, bei dem dieselbe Idee auftaucht, die jemand vor acht Monaten getestet hatte, nur erinnert sich niemand mehr an das Ergebnis. Das ist, was passiert, wenn ein Programm kein Gedächtnis hat.
Struktur schlägt Improvisation. Schriftliches schlägt Mündliches. Breiter Input schlägt kleine Gruppen. Die Programme, die kumulieren, sind jene, bei denen jeder finden kann, was getestet wurde, was gelernt wurde und was als Nächstes kommt.
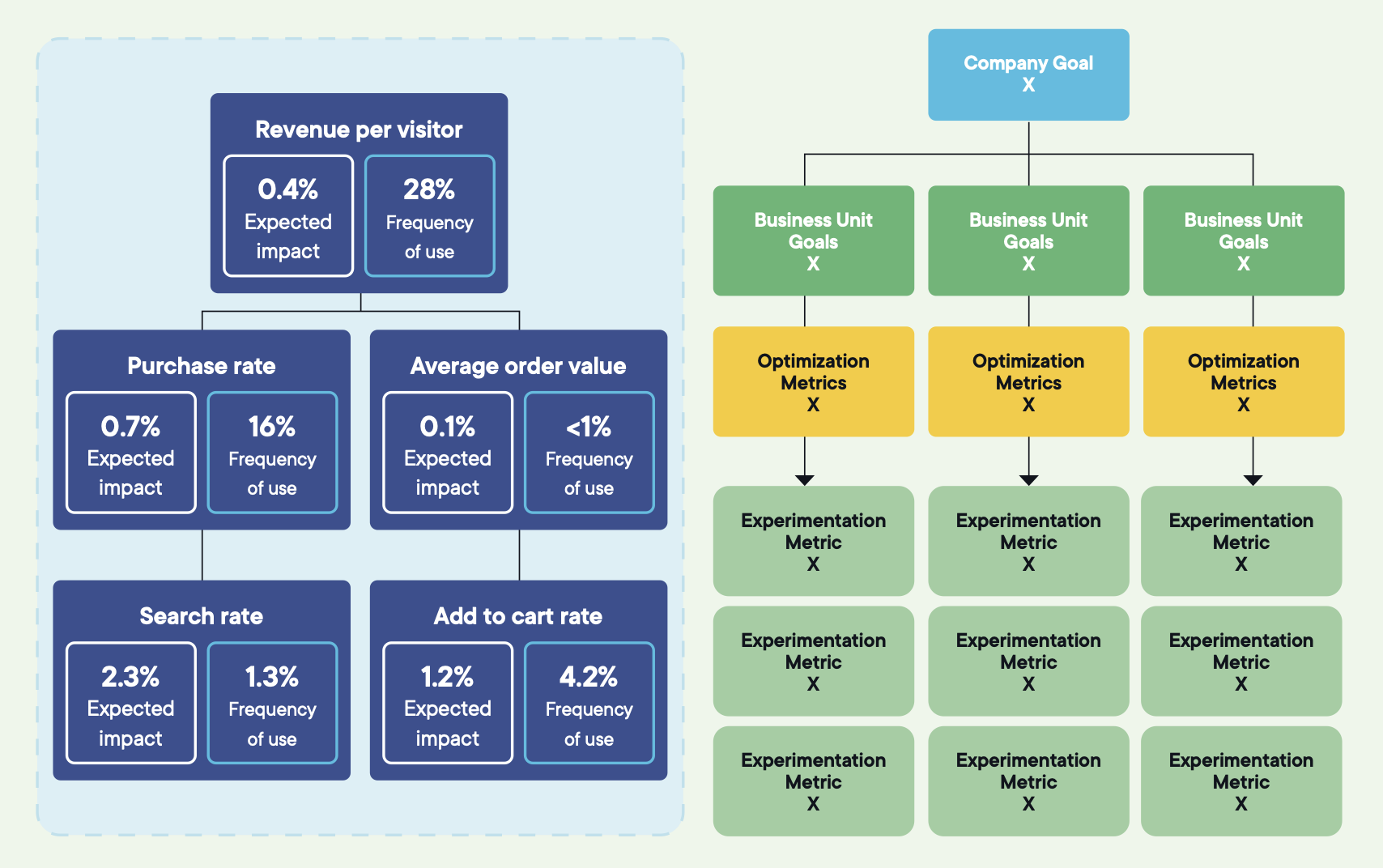
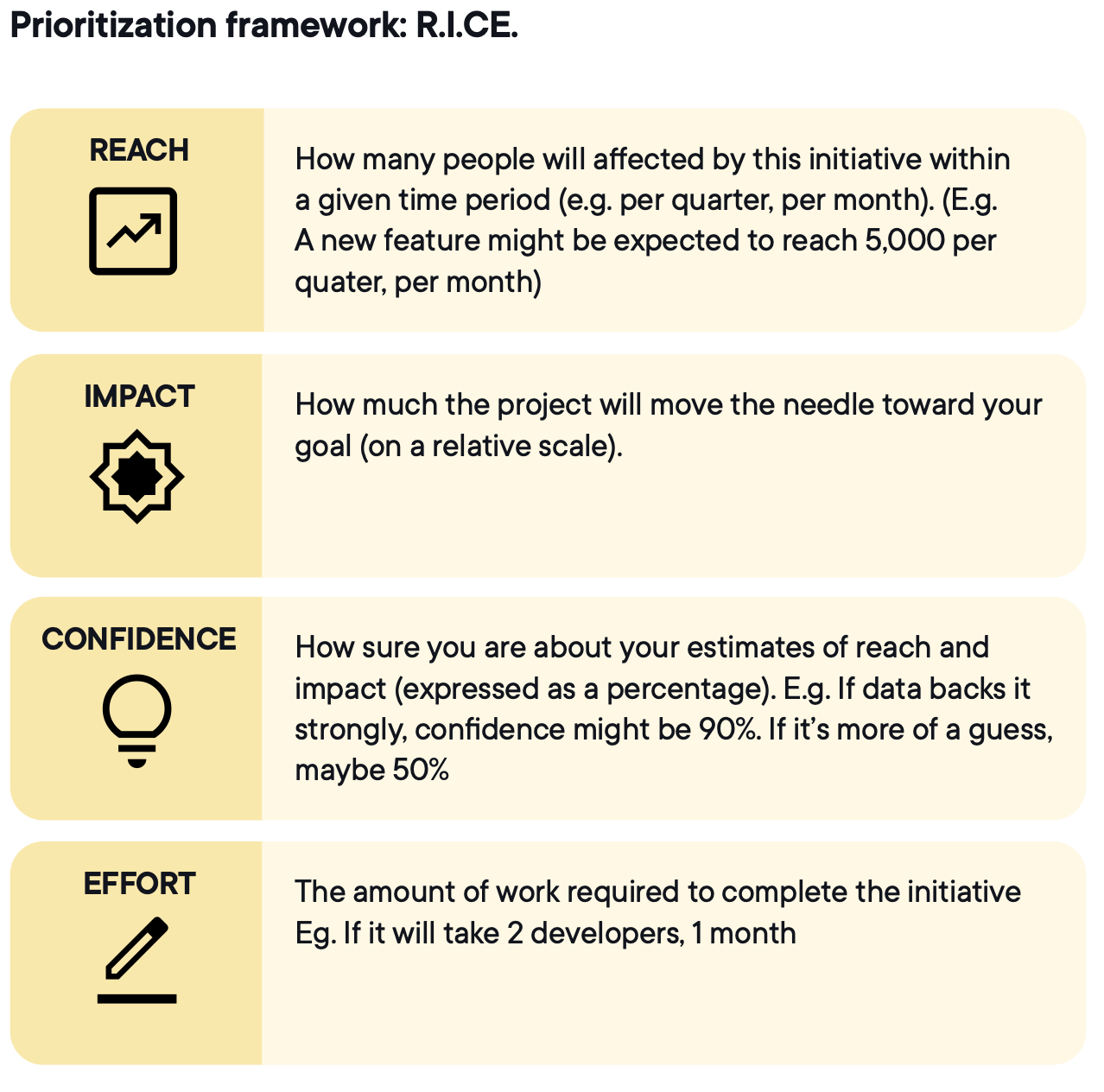
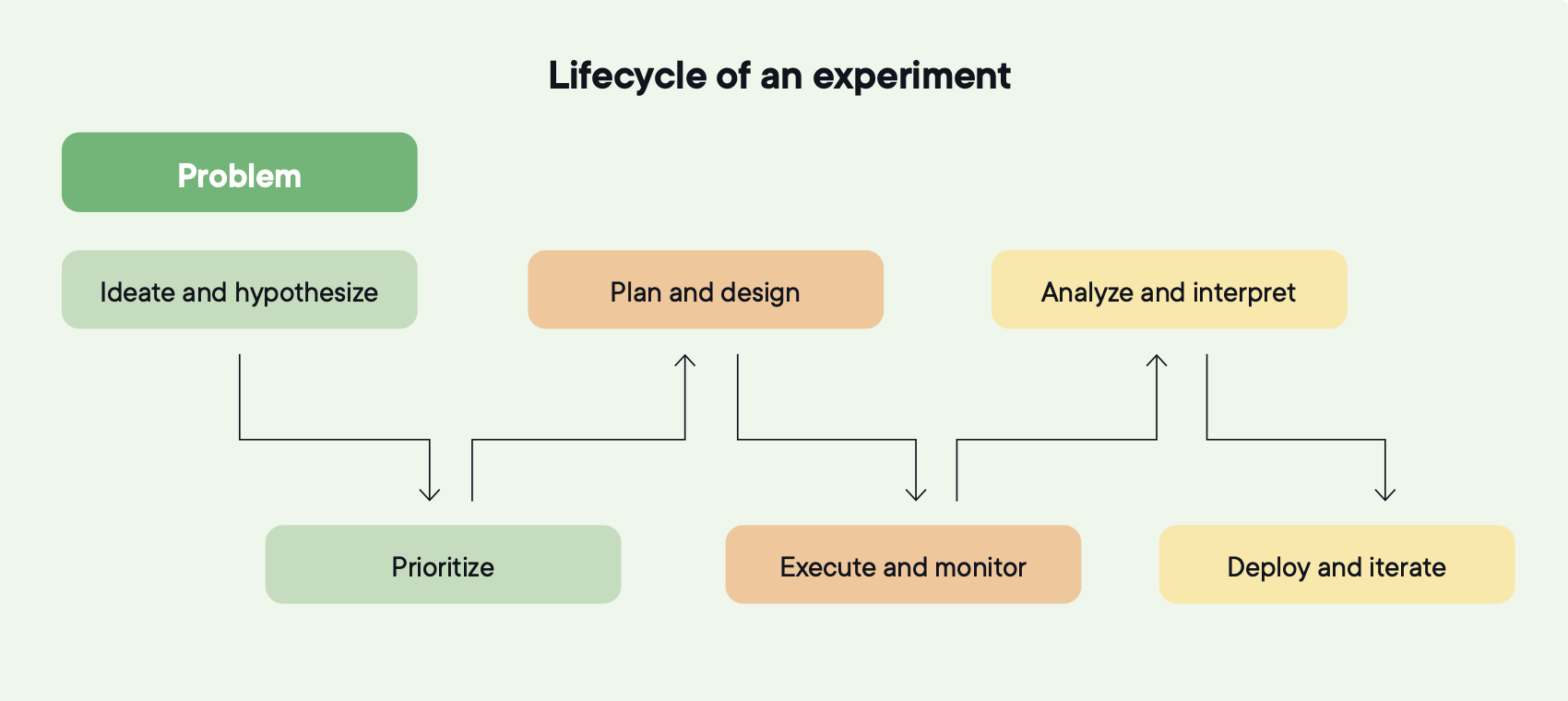
 Bildquelle: Optimizely
Bildquelle: Optimizely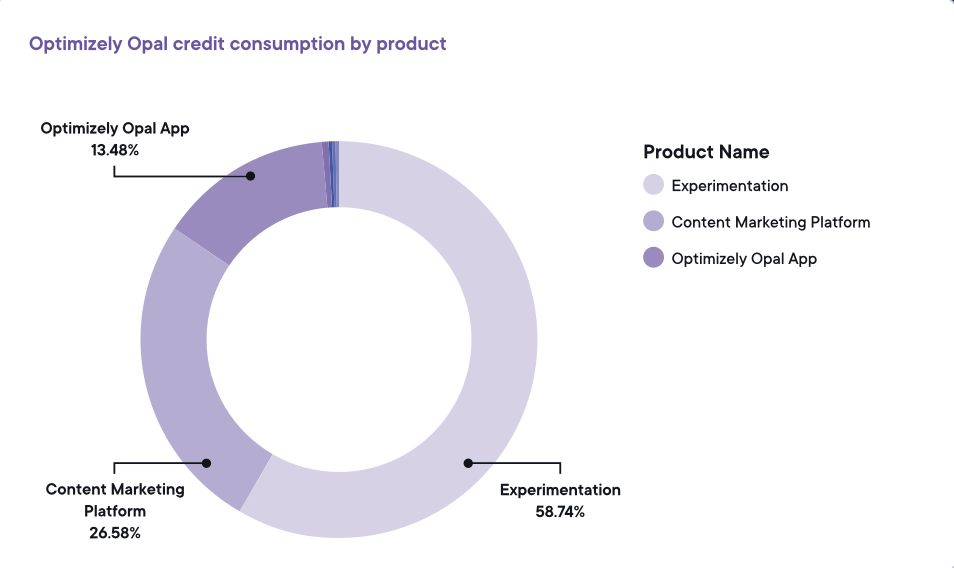 Bildquelle: Optimizely
Bildquelle: Optimizely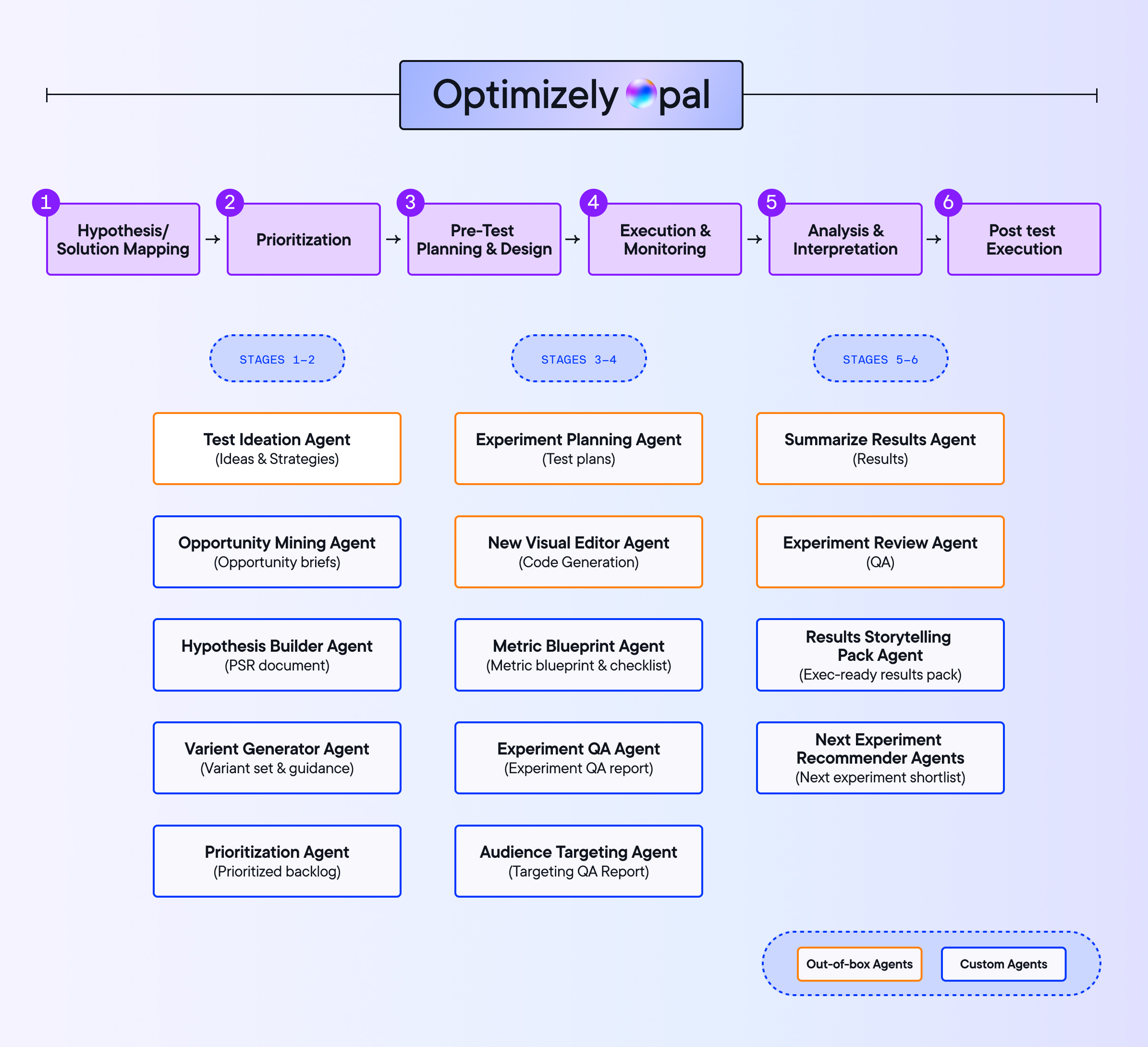 Bildquelle: Optimizely
Bildquelle: Optimizely