KI übernimmt den ersten Kontaktpunkt.
Käufer vergleichen Optionen in KI-Tools. Wenn jemand auf Ihrer Website landet, ist er bereits informiert. Bereit zu kaufen.
Deshalb zählt jede Experience, denn immer weniger Suchanfragen enden mit einem Klick.
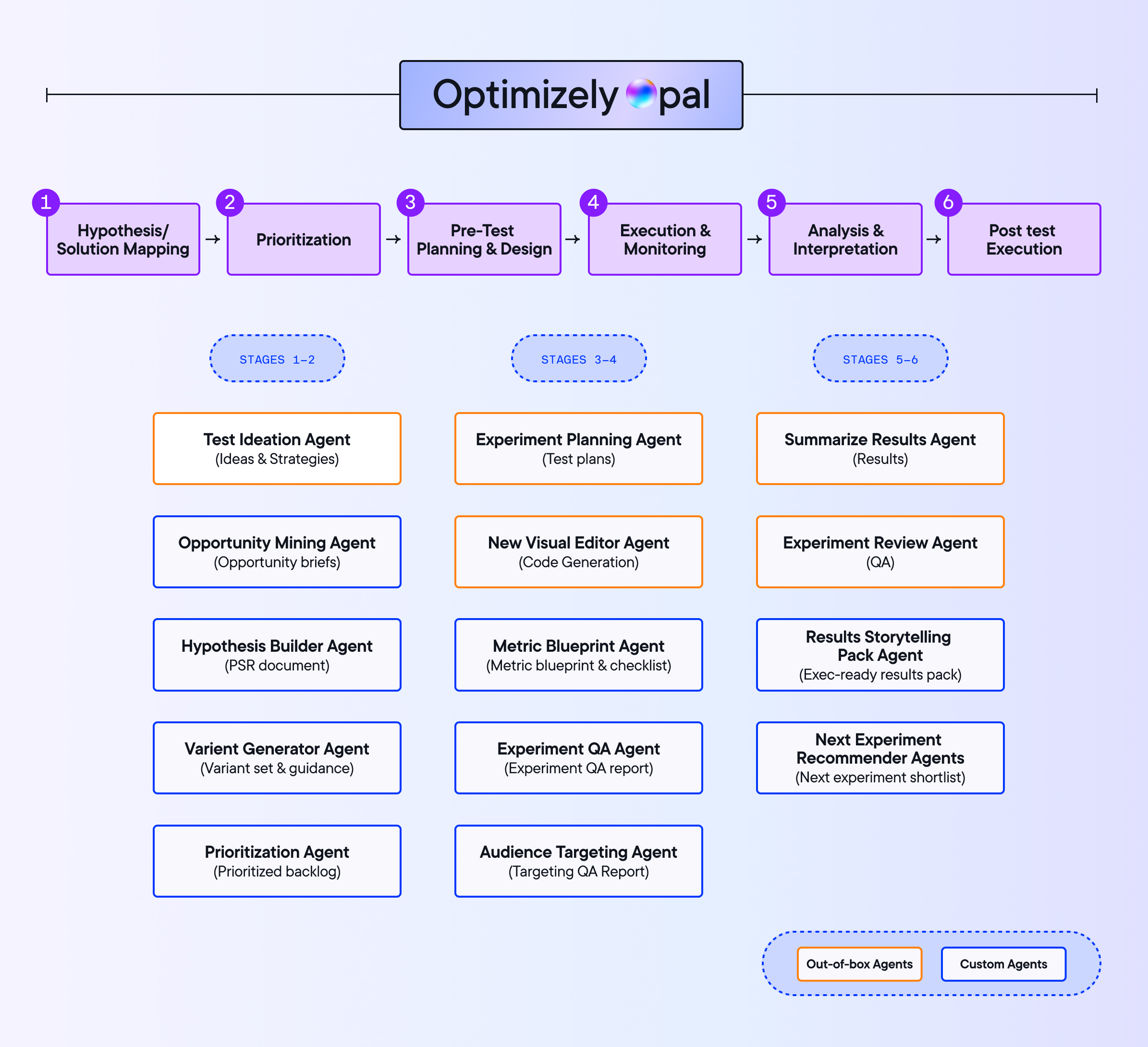
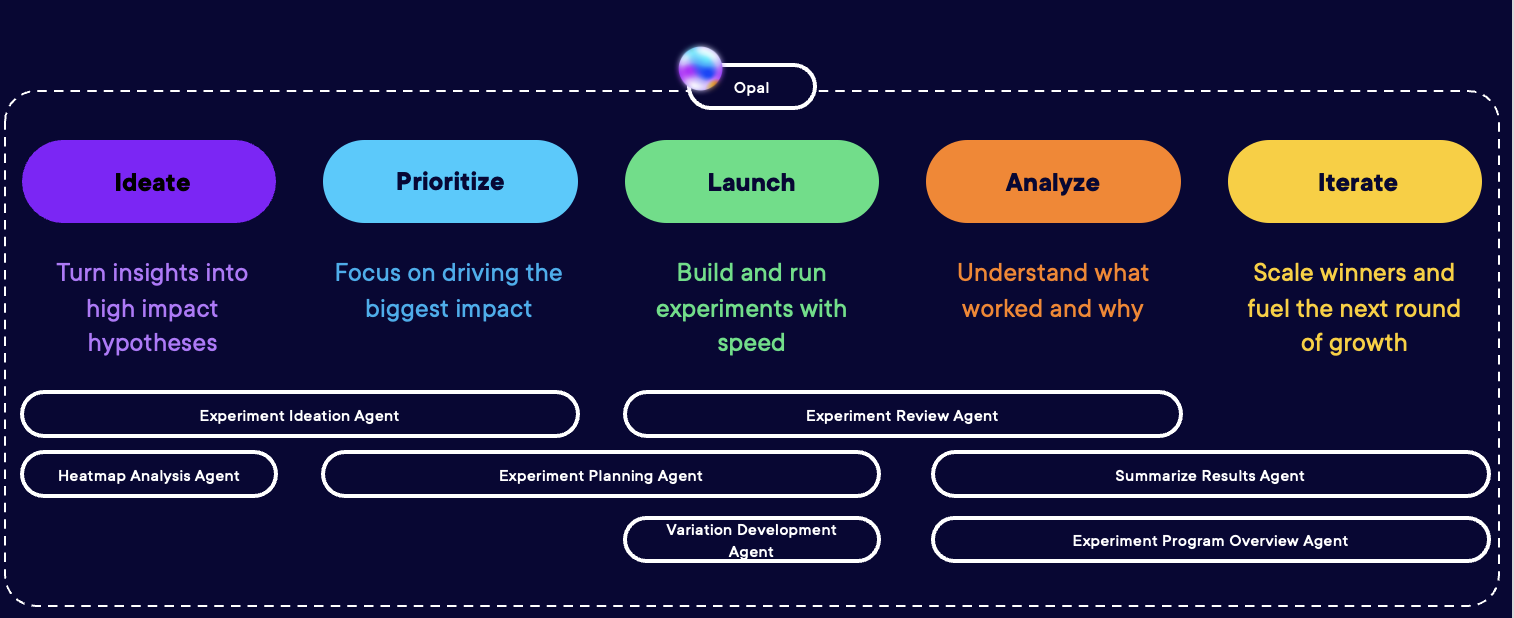
Aber die Verbesserung dieser Experiences erfordert Aufwand. Jedes Experiment benötigt Recherche, Hypothesenvalidierung, Variationsentwicklung, Durchführung, Monitoring und Analyse. Jeder Schritt wartet auf jemanden.
Also machen Sie Kompromisse. Testen Sie nur die größten Ideen. Lassen Sie kleinere Chancen sich ansammeln. Warten Sie auf eindeutige Ergebnisse.
KI kann helfen ist keine Neuigkeit. Sie haben jedoch KI ausprobiert und sind wahrscheinlich auf eine Herausforderung gestoßen, die wir bei Marken immer wieder sehen:
Wie lässt sich KI zuverlässig, skalierbar und mit Verantwortlichkeit und Governance einsetzen?
Um eine Antwort auf dieses Problem der Skalierung mit KI zu finden, haben wir Daten aus 47.000 Optimizely Opal-Interaktionen und 900 Unternehmen analysiert.