Model A/B testing: The objective measure of business impact
The assumption that "more powerful equals better" is often wrong in AI. GPT-4o might be superior for creative reasoning, but Claude 3.5 Sonnet might outperform it on cost-efficiency for your specific use case. Without a way to compare in real-world production environments, you're just guessing.
Optimizely FX enables Model A/B Testing at the code level, and it's the only objective way to measure the true business impact of LLM-driven capabilities. By using flag variables, you can bucket users into different model configurations concurrently and measure what actually moves the needle: revenue per user, task completion rate, and conversion. Not "chat accuracy."
The model is no longer the product. The configuration is. A single flag can control the entire AI stack:
This means AI Engineers can experiment on how a model is instructed, constrained, and equipped, not just which model runs. That's where FX stops being a deployment tool and starts being a full AI control plane.
Managing risk: Guardrails and progressive rollouts
The biggest fear for any CTO or VP of Product is the AI hallucination that goes viral. Feature flags address this at two levels: alerting and rollout control.
Tiered alerting means you don't wait for a crisis. Well-instrumented AI deployments fire notifications at three severity levels before you ever touch the kill switch:
- Informational: A slight uptick in latency or token usage. Monitor closely.
- Warning: Hallucination rate crossing a threshold, CSAT dipping. Investigate.
- Critical: Conversion drop, error spike, model failing silently. Act now.
This connects directly to your observability tooling. When your LLM starts negatively impacting user experience, you need to know before your users do.
The kill switch remains your last line of defence. If an AI feature starts behaving unexpectedly, you flip the switch in the Optimizely UI to revert to a stable version or disable the feature entirely. No emergency PR required.
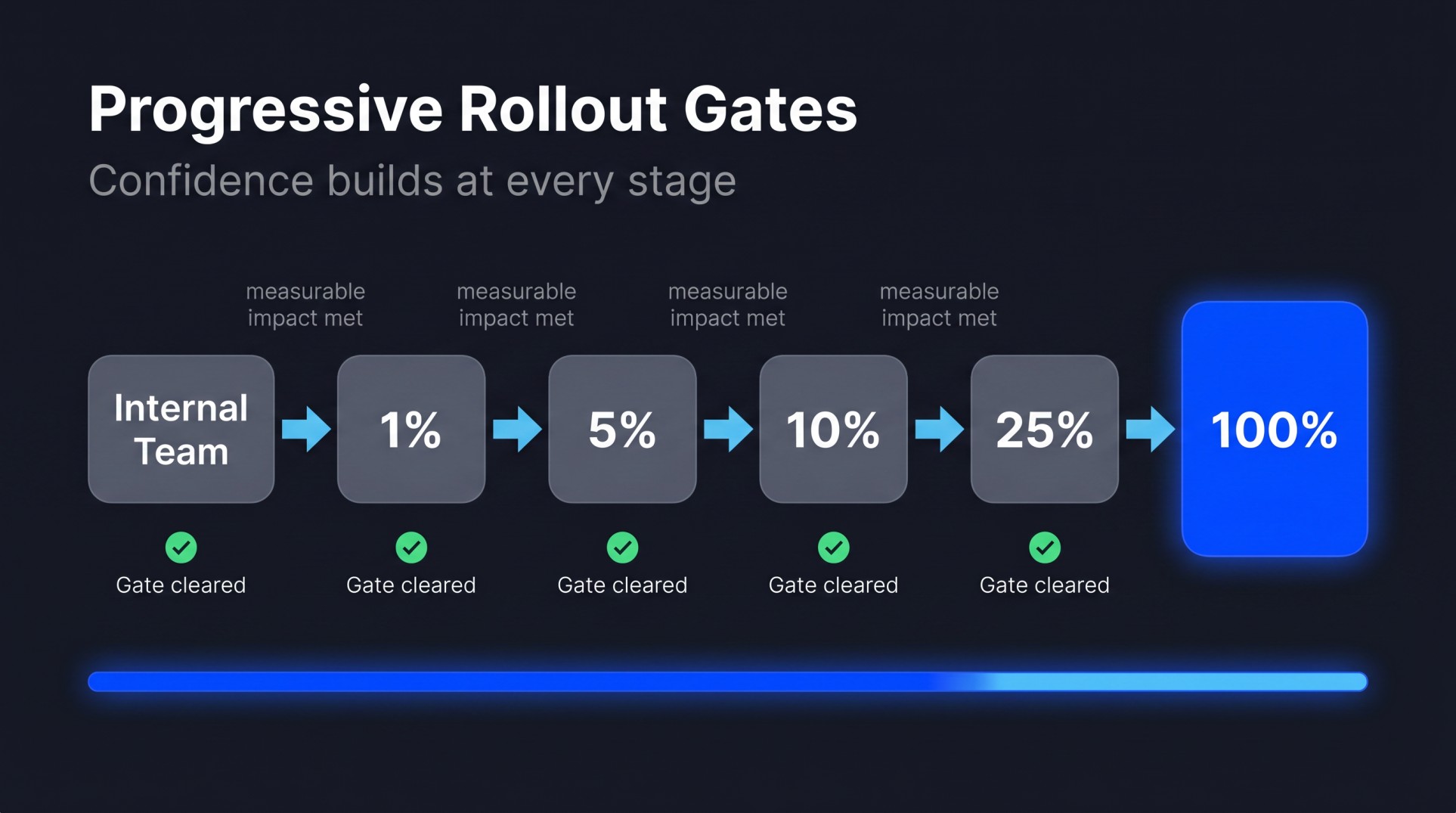
Progressive rollouts give you the confidence to move fast without breaking things. Rather than binary on/off, each stage is a gate: internal team first, then 1%, 5%, 10%, 25%, 100%.