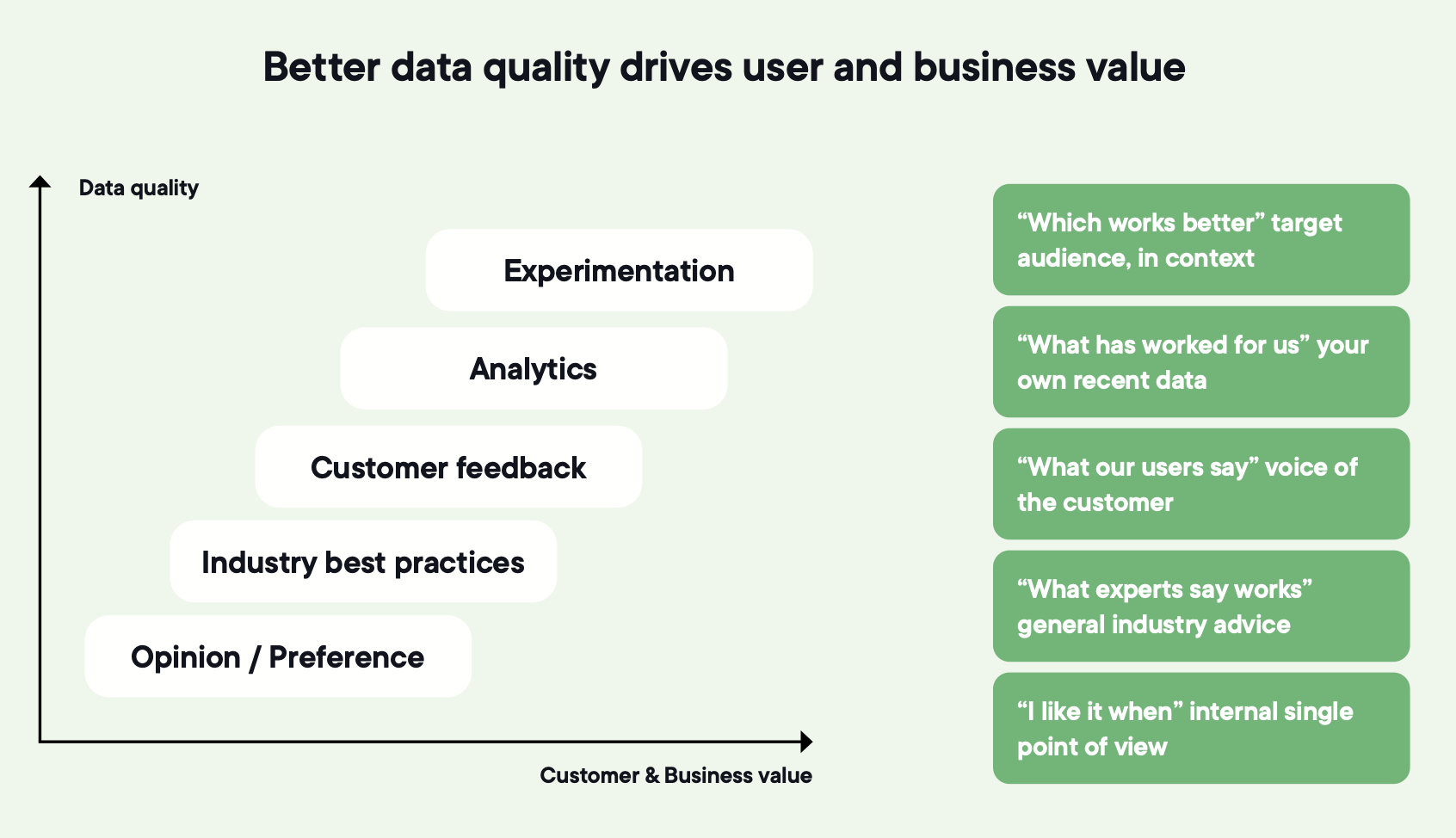
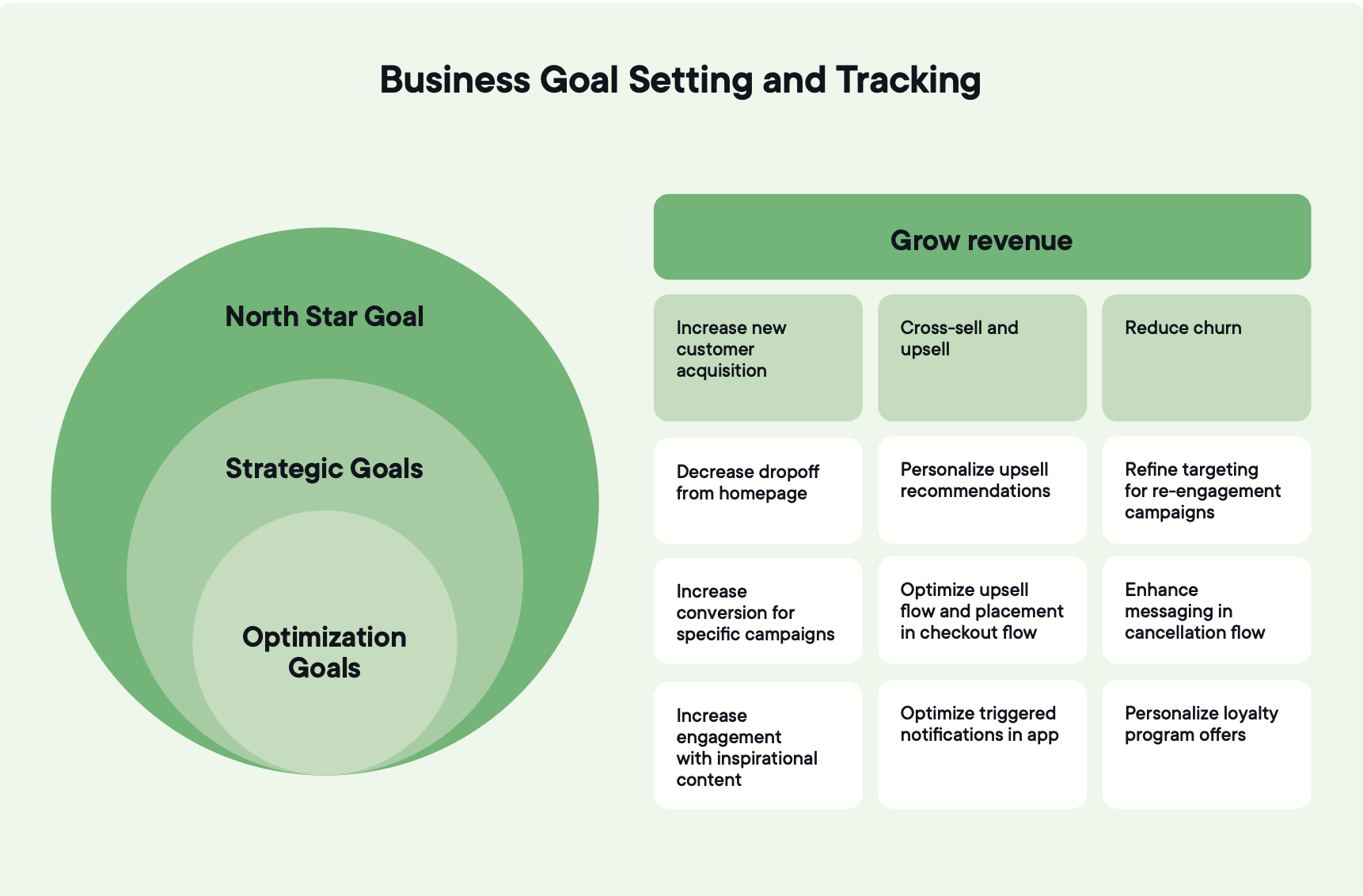
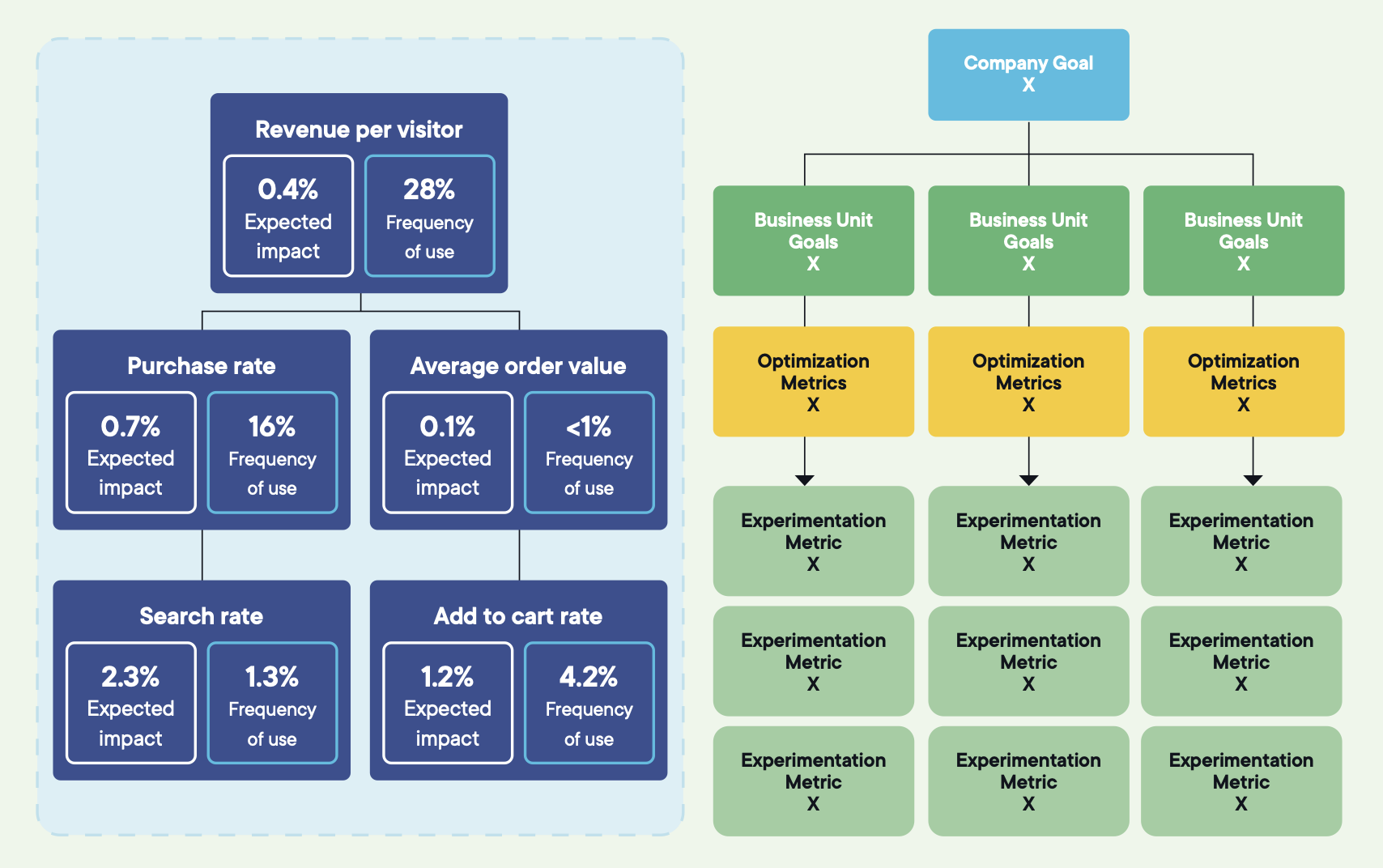
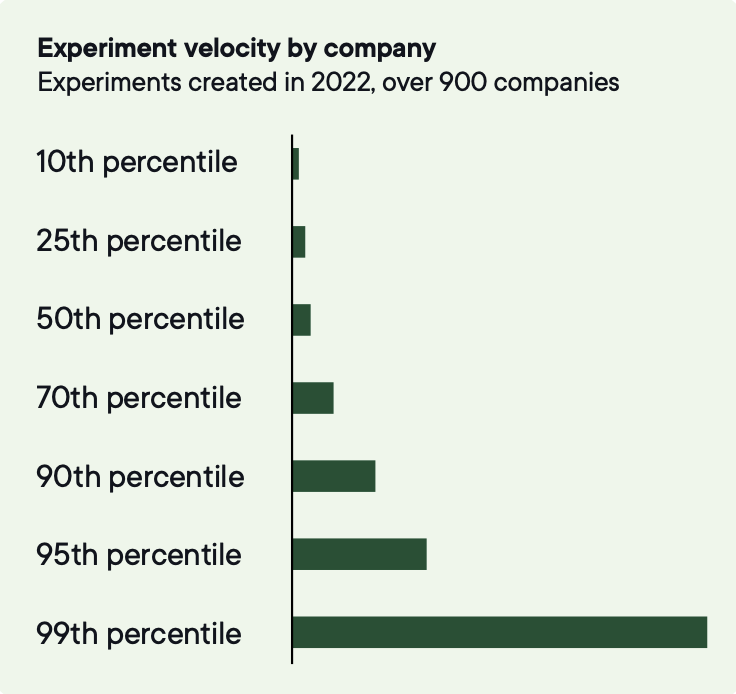
Image source: Optimizely
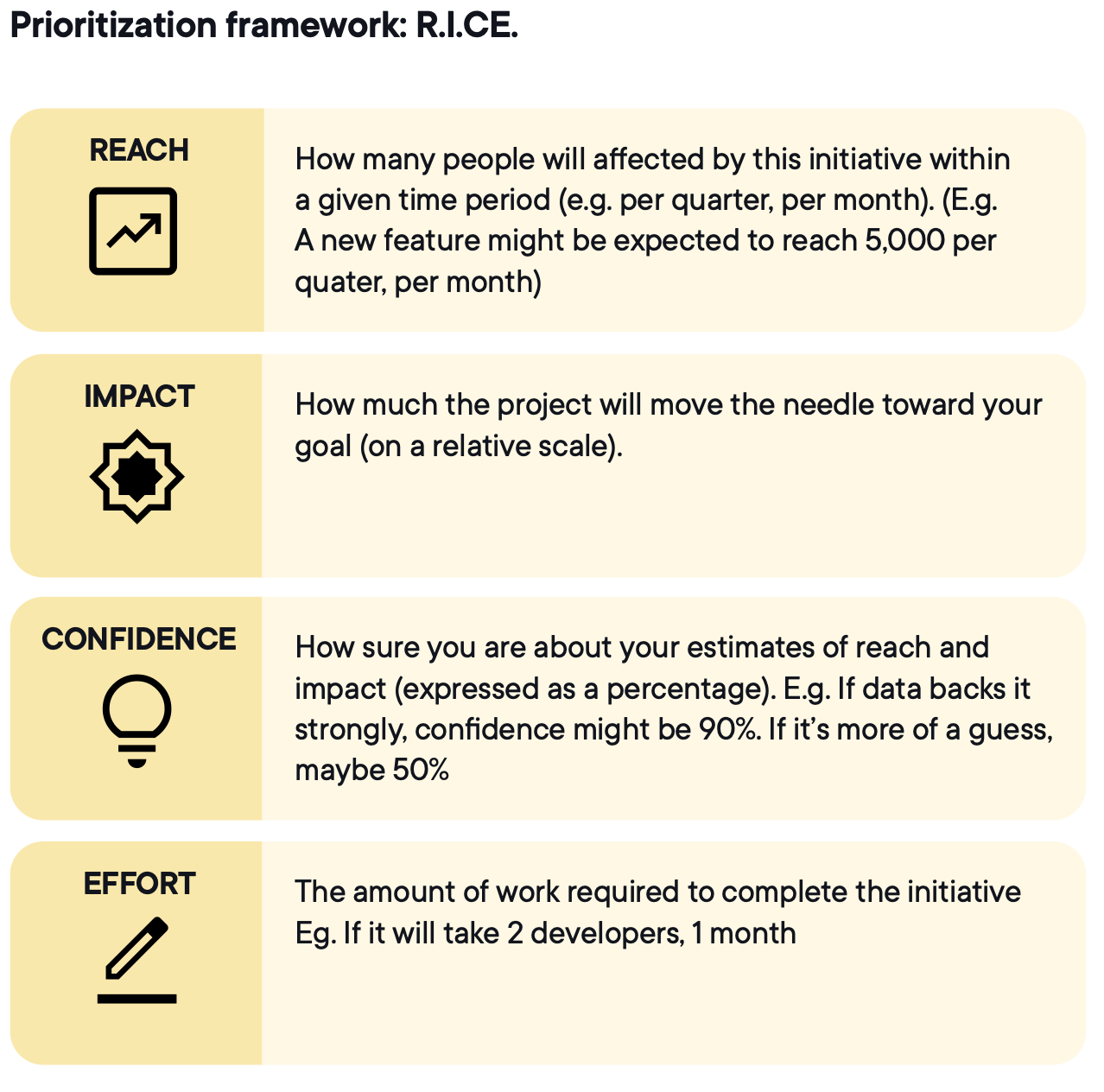
A checkout flow test might score high on reach and impact but require weeks of engineering. A pricing-page copy test might score lower on impact but higher on confidence and far lower on effort. RICE makes the trade-off explicit, so prioritization is driven by shared criteria rather than urgency or hierarchy.
The score is meant to start the conversation, not end it. When the same team scores ideas the same way over time, the backlog becomes a living view of the experimentation strategy. What's being tested now, what's coming next, and which uncertainties the organization has chosen to resolve in what order.
Five things to avoid:
- Inflating impact to push ideas through
- Treating confidence as intuition rather than evidence
- Ignoring reach constraints
- Underestimating effort by leaving out QA and analytics work
- Treating the score as the final answer instead of a ranked starting point
10. Every experiment should make the next one smarter
A program compounds when results actively shape future decisions. Proven mechanisms get reused, disproven assumptions stop getting retested, and confidence is earned through evidence rather than reset to intuition each cycle. Past experiments get referenced during ideation and planning, not only in the quarterly readout.
When that loop is working, experimentation becomes a shared, evidence-based understanding of how users behave that informs every decision, not just the ones being tested. When it isn't working, experimentation produces records instead of progress.
Two things have to be true:
1. Inconclusive results have to be treated as learning
A healthy program has a 35–40% conclusive rate, which means roughly 60% of tests don't produce a clear win or loss. The useful question after an inconclusive test is what went wrong with the detection rather than the idea.
- Was the sample size too small?
- Was the metric too far downstream from the change?
- Was the contrast between variations too thin?
2. Learning has to be findable
Most teams can't sustain this manually as test volume grows. Insights get buried, and different teams retest the same hypothesis without realizing it. Inside Optimizely, 58.74% of all Opal agent usage is now experimentation, and 19.54% of follow-up tests are driven by agent recommendations grounded in prior results. Agents reference the team's experiments, results, and flags, and surface what's been tried before a new hypothesis gets written.
If you can't clearly state what the last experiment taught you and what new question the next one is meant to answer, you're not iterating. You're just changing things.