Hvert eksperiment trenger en testplan som er avtalt før lansering. Den inneholder hypotesen, eksperimenttypen, variasjonene, targeting, primær målindikator, beslutningsregler og risikoer. Uten den tolkes resultater mot det spørsmålet som virker mest praktisk etter at dataene er inne.
4. Utfør og overvåk
Utførelse er der godt utformede eksperimenter bryter sammen.
De første timene bør fokusere på korrekthet, ikke ytelse:
- Kontroll og alle varianter gjengis korrekt
- Trafikk fordeles i henhold til planlagt allokering
- Primær målindikator registreres for alle varianter
- Ingen sporingsmangler, dobbeltelling eller uventede topper
- Interne brukere, bots og QA-trafikk er ekskludert
Forvent tidlig volatilitet. Ikke evaluer ytelse i dette vinduet. Målet er validering, ikke tolkning.
Når lanseringsvalideringen er fullført, flyttes overvåkingen til å beskytte integriteten. Se etter uforklarlige skift i målgruppemiks, trafikkinkonsistenser eller konflikter med andre eksperimenter som kjøres mot samme målgruppe.
Når et eksperiment er live, behandles designet som fast. Enhver endring av varianter, targeting eller målindikatorer introduserer skjevhet og gjør resultatet upålitelig. Pause kun for å beskytte brukere eller virksomheten. Avslutt kun basert på forhåndsdefinerte kriterier. Dokumenter eventuelle eksterne hendelser som inntreffer under kjøring.
Stopp hvis den primære målindikatoren oppnår statistisk signifikans og testen har kjørt i minst to uker for å fange normale brukeratferdsmønstre. Stopp også hvis testen har kjørt planlagt varighet, samlet opp betydelig trafikk og resultatene forblir langt fra signifikans – klassifiser som uklar og gå videre.
5. Analyser og bestem
Den vanligste feilen i analyse skjer før noen ser på dataene.
- Tenk: Gjenta formålet. Hvilket problem eksperimentet var utformet for å løse, hva hypotesen var, hva den primære målindikatoren er og hvilken retning som utgjør suksess. Dette forhindrer at spørsmålet endres etter at svaret er sett.
- Observer: Primært målindikatorresultat for hver variant. Sekundære målindikatorer for kontekst. Overvåkingsmålindikatorer for å vise om noe gikk i stykker. Kun forhåndsdefinerte segmenter.
- Tolke: Lever, iterer, utvid eller stopp. Dokumenter hvorfor beslutningen ble tatt, ikke bare hva som ble bestemt. Statistisk signifikans er en terskel, ikke en garanti.
Å koble eksperimenter til lageret betyr å analysere mot customer lifetime value, returandeler og kundebevaring fremfor klikk og konverteringer. Etter hvert som KI-søk overtar oppdagelsen, blir klikk mindre prediktive for forretningsverdi. Måleindikatorene som vil ha betydning fremover, lever i lageret.
6. Lever, iterer og akkumuler
Å levere en vinner er ikke det samme som å akkumulere en læring.
Bekreft at beslutningen fortsatt holder. Lever nøyaktig det som ble testet. Siste-øyeblikks-justeringer endrer mekanismen som produserte resultatet. Enhver produksjonsjustering dokumenteres.
Overvåk den samme primære målindikatoren og sikkerhetsnettet etter lansering. Deretter iterer:
- Forfin: Target atferden som beveget seg eller ikke beveget seg
- Utforsk tilgrensende: Test en annen tilnærming til det samme problemet
- Utvid: Bruk den samme mekanismen på nye kontekster eller målgrupper
- Stopp: Dokumenter læringen og gå videre
Akkumulering fungerer bare hvis resultater endrer hva som skjer etterpå. De fleste team har kjent hva som bryter dette. Et testresultat delt i Slack som ingen handler på. Et hypotesemøte der den samme ideen dukker opp som noen hadde testet for åtte måneder siden, bortsett fra at ingen husket resultatet. Det er hva som skjer når et program ikke har hukommelse.
Struktur slår improvisasjon. Skriftlig slår muntlig. Bred innspill slår små grupper. Programmene som akkumulerer er de der alle kan finne hva som ble testet, hva som ble lært og hva som kommer neste.
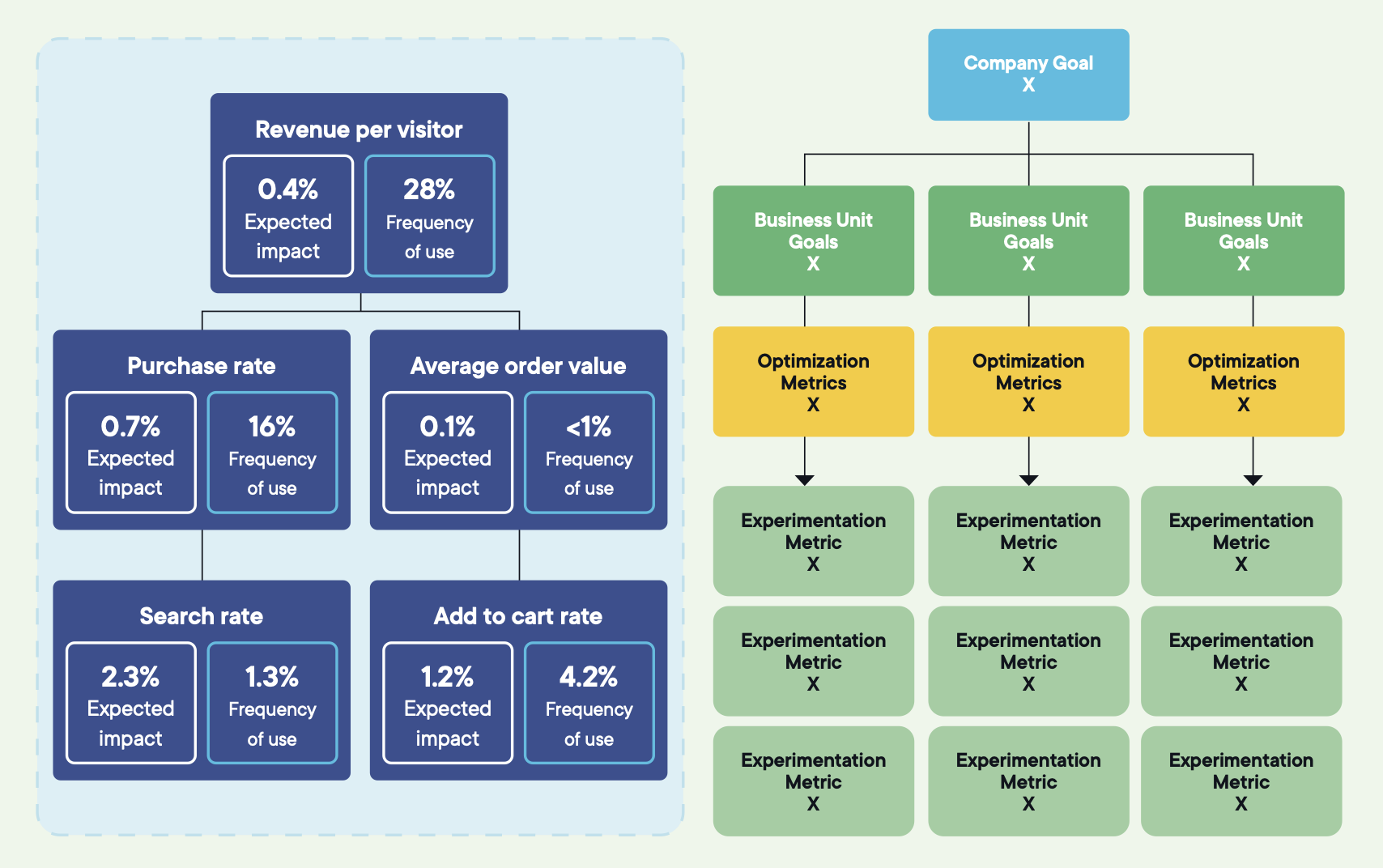
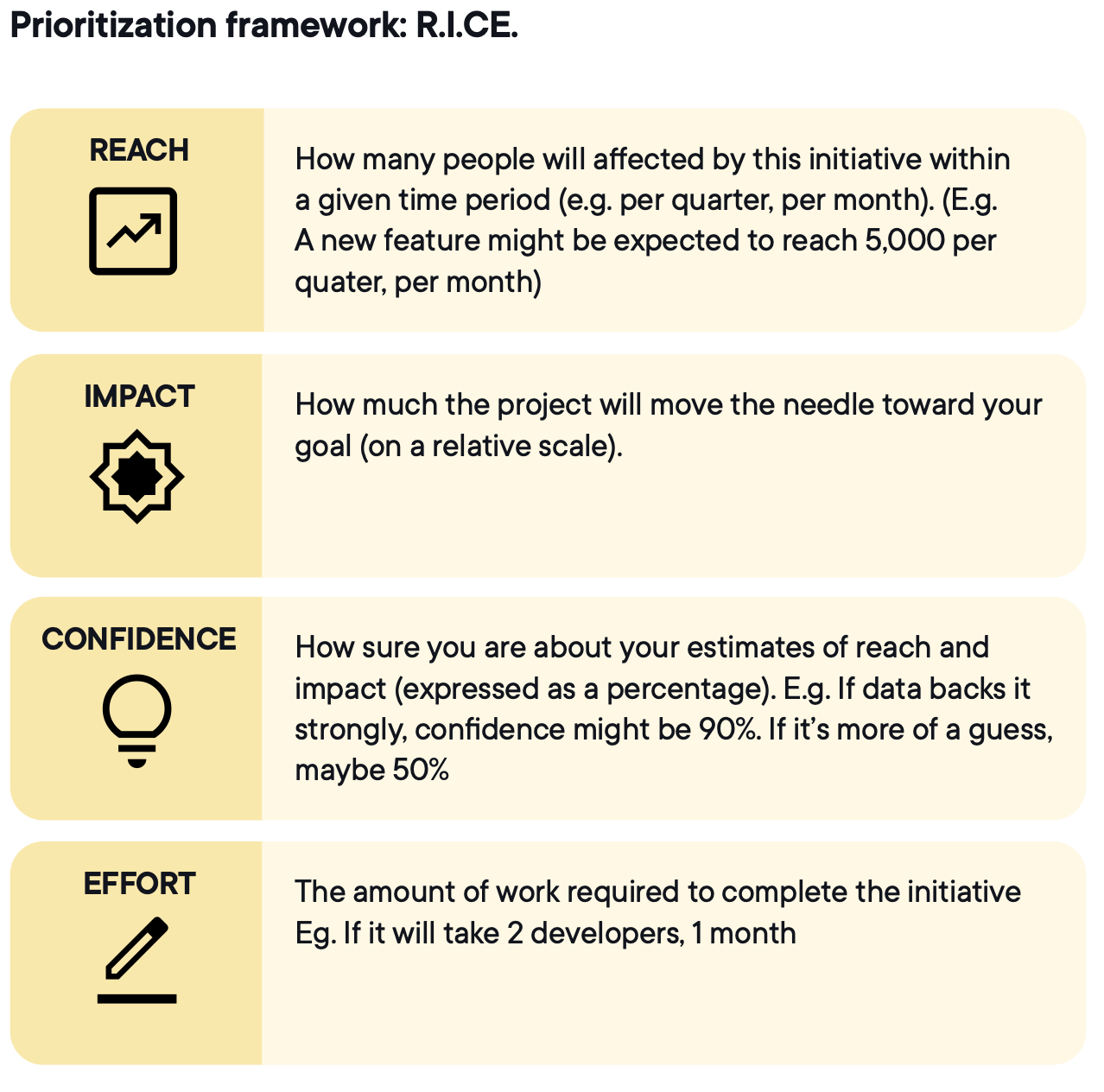
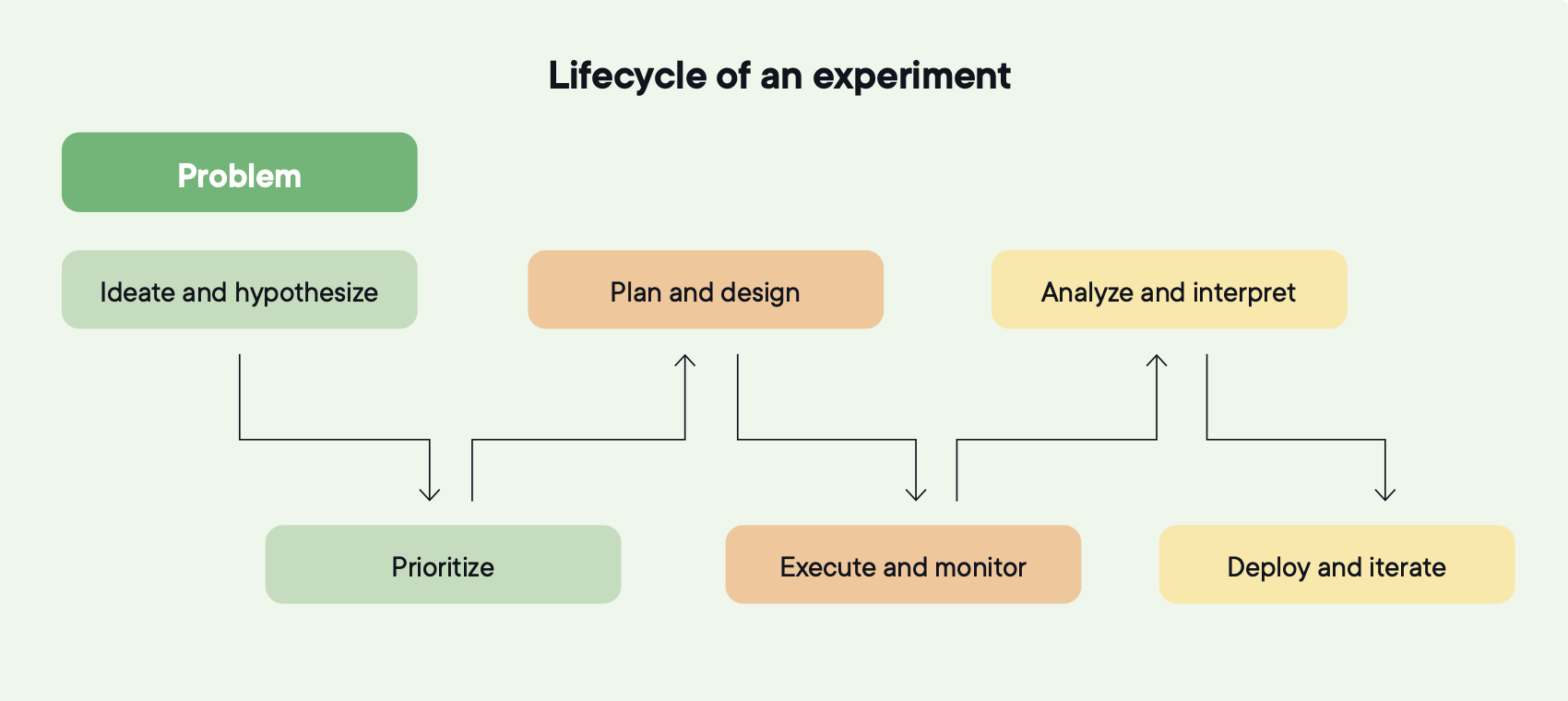
 Bildekilde: Optimizely
Bildekilde: Optimizely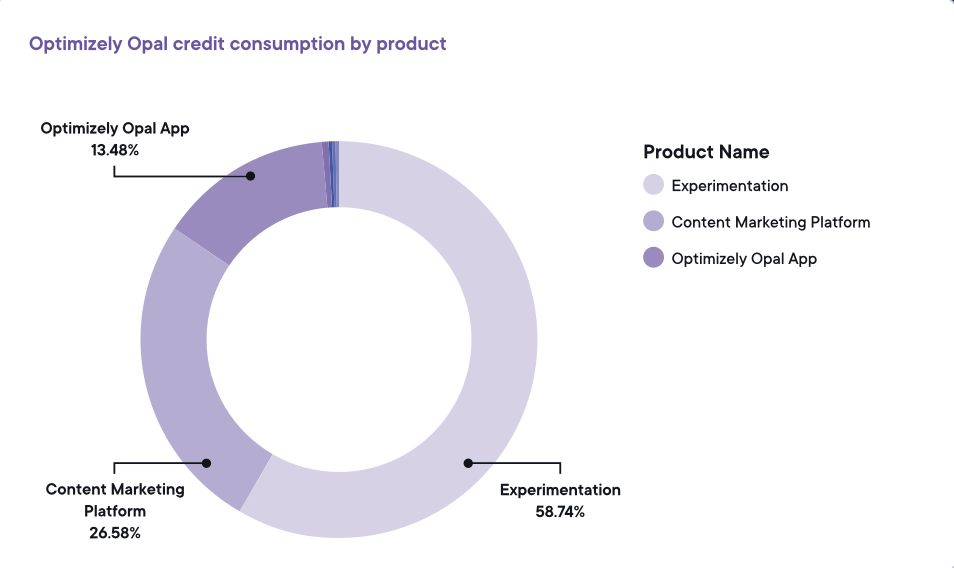 Bildekilde: Optimizely
Bildekilde: Optimizely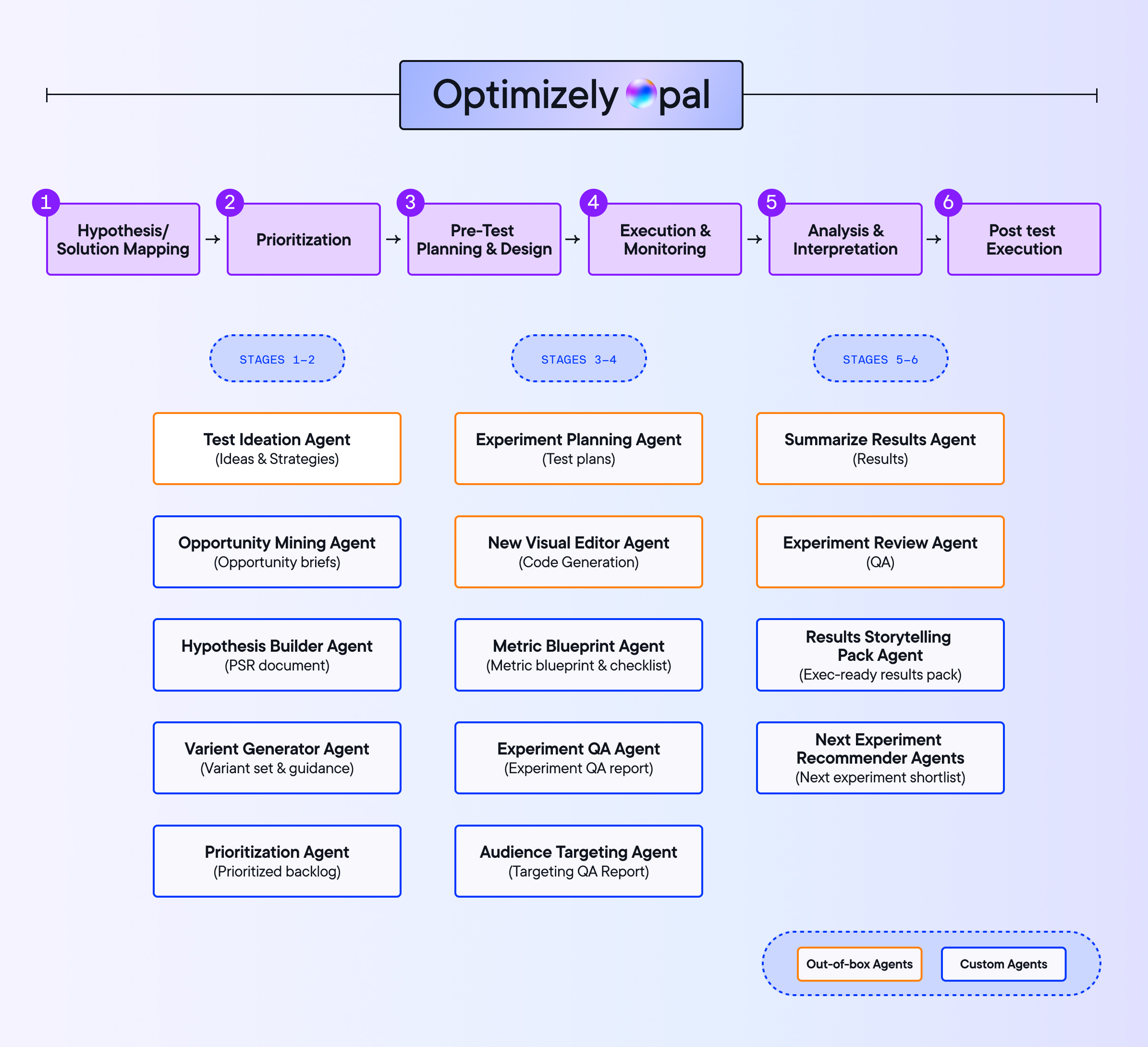 Bildekilde: Optimizely
Bildekilde: Optimizely