AI tar det første kontaktpunktet.
Kjøpere sammenligner alternativer i AI-verktøy. Når noen lander på nettstedet ditt, er de allerede informerte. Klare til å kjøpe.
Det er grunnen til at hver opplevelse teller – stadig færre søk ender med et klikk.
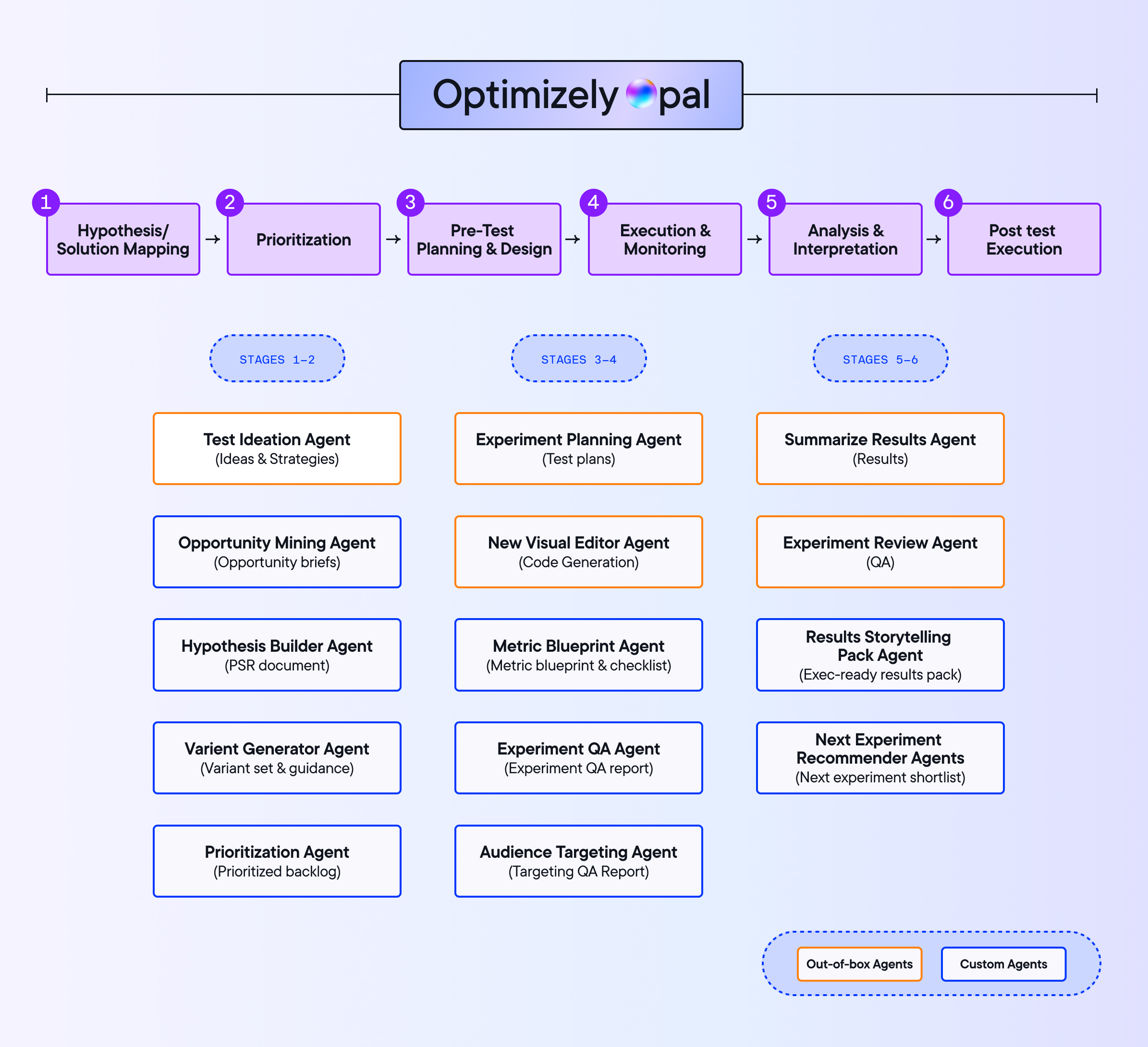
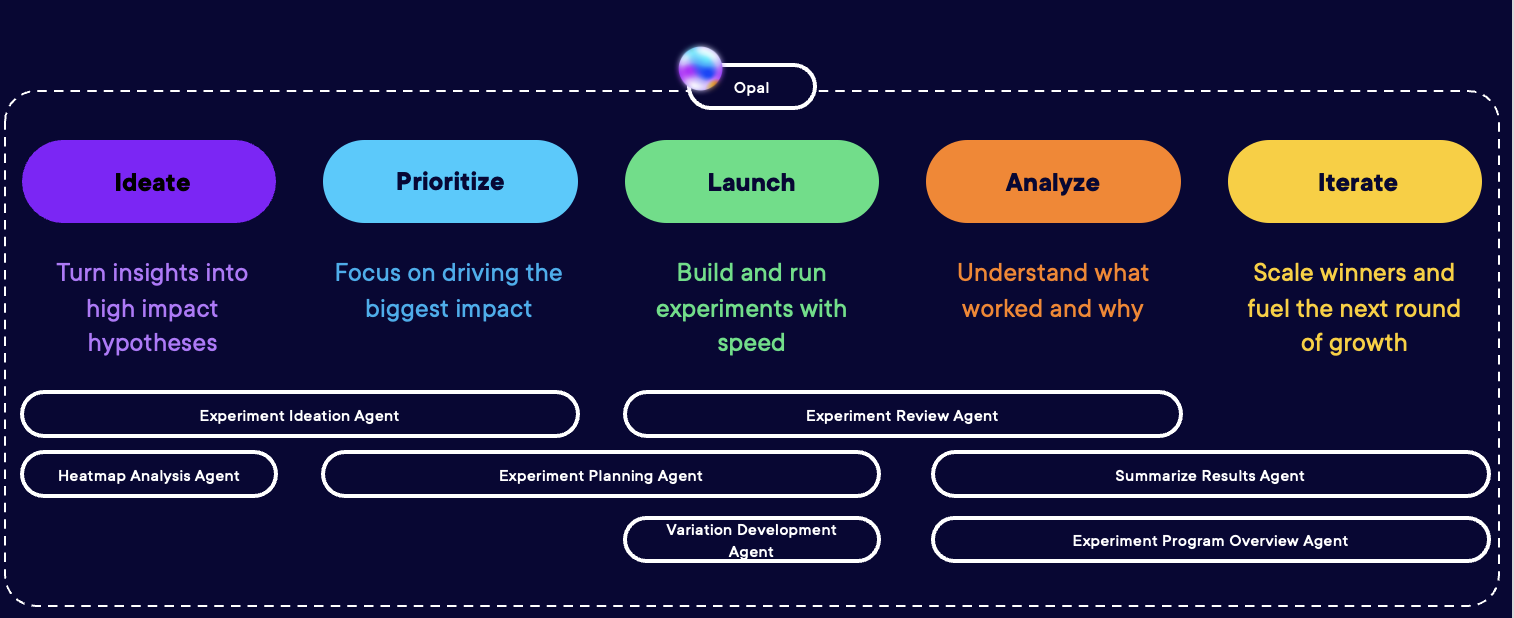
Men å forbedre disse opplevelsene krever arbeid. Hvert eksperiment trenger research, hypotesevalidering, variasjonsutvikling, gjennomføring, overvåking og analyse. Hvert steg venter på noen.
Så du gjør kompromisser. Tester bare de største ideene. Lar mindre muligheter hope seg opp. Venter på entydige resultater.
At AI kan hjelpe er ingen nyhet. Men du har prøvd AI og har sannsynligvis støtt på en utfordring vi ser på tvers av merkevarer:
Hvordan få AI til å fungere pålitelig, i stor skala og med ansvarlighet og styring?
For å finne et svar på dette problemet med å skalere med AI analyserte vi data fra 47 000 Optimizely Opal-interaksjoner og 900 selskaper.