Klassiska statistiska tekniker, som t-testet, är grunden för optimeringsbranschen och hjälper företag att fatta datadrivna beslut. I takt med att online-experiment har exploderat är det nu tydligt att dessa traditionella statistiska metoder inte är rätt lösning för digital data: Att tillämpa klassisk statistik på A/B-testning kan leda till felfrekvenser som är mycket högre än vad de flesta experimentörer förväntar sig.
Både branschen och akademiska experter har vänt sig till utbildning som lösningen. Titta inte! Använd en urvalsstorlekskalkylator! Undvik att testa för många mål och variationer samtidigt!
Men vi har dragit slutsatsen att det är dags att statistik, inte kunder, förändras. Säg adjö till det klassiska t-testet. Det är dags för statistik som är enkel att använda och fungerar med hur företag faktiskt fungerar.
I samarbete med ett team av statistiker från Stanford utvecklade vi Stats Engine, ett nytt statistiskt ramverk för A/B-testning. Vi är glada att kunna meddela att det från och med den 21 januari 2015 driver resultat för alla Optimizely-kunder.
Det här blogginlägget är långt, eftersom vi vill vara helt transparenta om varför vi gör dessa ändringar, vad ändringarna faktiskt är och vad det betyder för A/B-testning i stort. Håll utkik efter oss till slutet, du kommer att lära dig:
- Varför vi skapade Stats Engine:Internet gör det enkelt att utvärdera experimentresultat när som helst och köra tester med många mål och variationer. I kombination med klassisk statistik kan dessa intuitiva åtgärder öka risken för att felaktigt deklarera en vinnande eller förlorande variant med över 5 gånger.
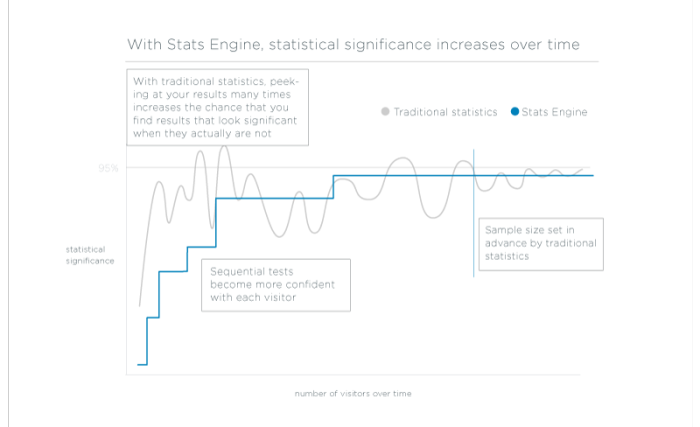
- Hur det fungerar: Vi kombinerar sekventiell testning och kontroller av falsk upptäcktsfrekvens för att leverera resultat som är giltiga oavsett urvalsstorlek och matchar den felfrekvens vi rapporterar med de fel som företag bryr sig om.
- Varför det är bättre: Stats Engine kan minska risken för att felaktigt deklarera en vinnande eller förlorande variant från 30 % till 5 % utan att offra hastighet.
Varför vi skapade en ny Stats Engine
Traditionell statistik är ointuitiv, lätt att missbruka och ger pengar på bordet.
För att få giltiga resultat från A/B-tester som körs med klassisk statistik följer noggranna experimentatorer en strikt uppsättning riktlinjer: Sätt en minsta detekterbar effekt och urvalsstorlek i förväg, titta inte på resultaten, testa inte för många mål och variationer samtidigt.
Dessa riktlinjer kan vara besvärliga, och om du inte följer dem noggrant kan du omedvetet introducera fel i dina tester. Det här är problemen med dessa riktlinjer som vi försökte åtgärda med Stats Engine:
- Att bestämma sig för en detekterbar effekt och urvalsstorlek i förväg är ineffektivt och inte intuitivt.
- Att titta på resultat innan man når den urvalsstorleken kan introducera fel i resultaten, och du kan vidta åtgärder mot falska vinnare.
- Att testa för många mål och variationer samtidigt ökar fel på grund av falska upptäckter avsevärt – en felfrekvens som kan vara mycket större än den falska positiva frekvensen.
Att bestämma sig för en urvalsstorlek och detekterbar effekt kan sakta ner dig.
Att ställa in en urvalsstorlek innan man kör ett test hjälper till att undvika att göra misstag med traditionella statistiska metoder. För att ställa in en urvalsstorlek måste du också gissa om den minsta detekterbara effekten (MDE), eller förväntad konverteringsfrekvens, som du vill se från ditt test. Om du gissar fel kan det få stora konsekvenser för din testhastighet.
Ange en liten effekt, så måste du vänta på ett stort urval för att veta om dina resultat är signifikanta. Ange en större effekt, så riskerar du att missa mindre förbättringar. Detta är inte bara ineffektivt, det är inte heller realistiskt. De flesta kör tester eftersom de inte vet vad som kan hända, och att i förväg förbinda sig till en hypotetisk ökning är helt enkelt inte särskilt vettigt.
Att kika på dina resultat ökar dina felfrekvenser.
När data flödar in i ditt experiment i realtid är det frestande att ständigt kontrollera dina resultat. Du vill implementera en vinnare så snart som möjligt för att förbättra din verksamhet, eller stoppa ett ofullständigt eller förlorande test så tidigt som möjligt så att du kan gå vidare till att testa fler hypoteser.
Statistiker kallar detta konstanta kikarresultat för "kontinuerlig övervakning", och det ökar chansen att du hittar ett vinnande resultat när inget faktiskt existerar (naturligtvis är kontinuerlig övervakning bara problematiskt när du faktiskt stoppar testet tidigt, men du förstår poängen.) Att hitta en obetydlig vinnare kallas ett falskt positivt fel, eller typ I-fel.
Alla tester för statistisk signifikans som du kör kommer att ha en viss risk för fel. Att köra ett test med 95 % statistisk signifikans (med andra ord, ett t-test med ett alfavärde på 0,05) innebär att du accepterar en 5 % chans att, om detta vore ett A/A-test utan någon faktisk skillnad mellan variationerna, skulle testet visa ett signifikant resultat.
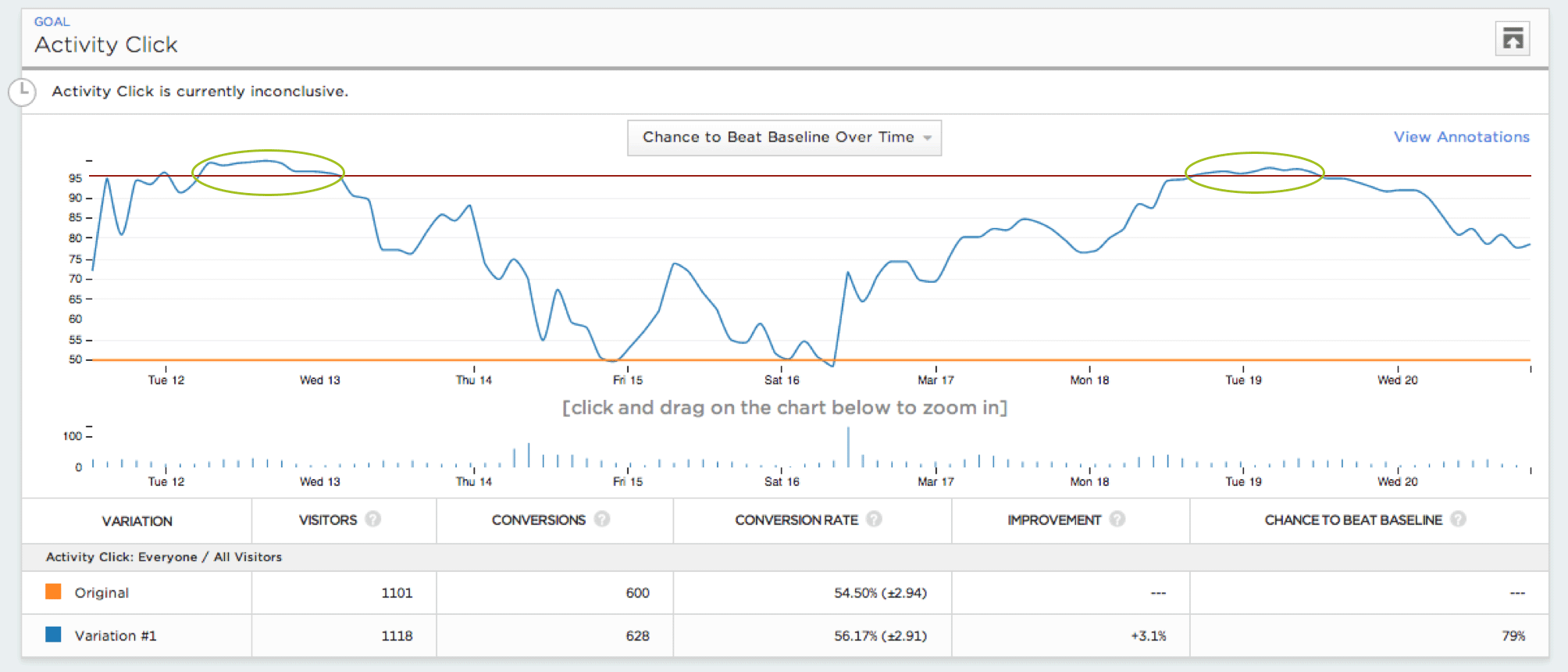
För att illustrera hur farlig kontinuerlig övervakning kan vara simulerade vi miljontals A/A-tester med 5 000 besökare och utvärderade risken för att göra ett fel under olika typer av kontinuerliga övervakningspolicyer. Vi fann att även konservativa policyer kan öka felfrekvensen från ett mål på 5 % till över 25 %.
I vår undersökning deklarerade mer än 57 % av de simulerade A/A-testerna felaktigt en vinnare eller förlorare minst en gång under sin tid, även om det bara var kort. Med andra ord, om du hade tittat på dessa tester kanske du undrat varför dina A/A-testresultat deklarerade en vinnare. Ökningen i felfrekvensen är fortfarande betydande även om du inte tittar på varje besökare. Om du tittar på var 500:e besökare ökar risken för att göra en falsk deklaration till 26 %, medan en sökning på var 1000:e besökare ökar samma risk till 20 %.