1. Ein gewonnener Test ist nicht grundsätzlich besser als ein verlorener Test
Nur 12 % der Experimente erzielen eine statistisch signifikante Verbesserung der primären Metrik. Teams sehen mit etwa gleicher Wahrscheinlichkeit ein negatives wie ein positives Ergebnis.
Optimizely-Kunden erzielen mit jedem umsatzorientierten Experiment einen durchschnittlichen inkrementellen Uplift von 0,4 % beim digitalen Umsatz, wenn Ergebnisse angewandt, verfeinert und weiterentwickelt werden. Eine Gewinnrate von 12 % kombiniert mit einem Uplift von 0,4 % pro Gewinner, konsequent angewandt, führt über die Zeit zu kumulativer Verbesserung.
 Bildquelle: Optimizely
Bildquelle: Optimizely
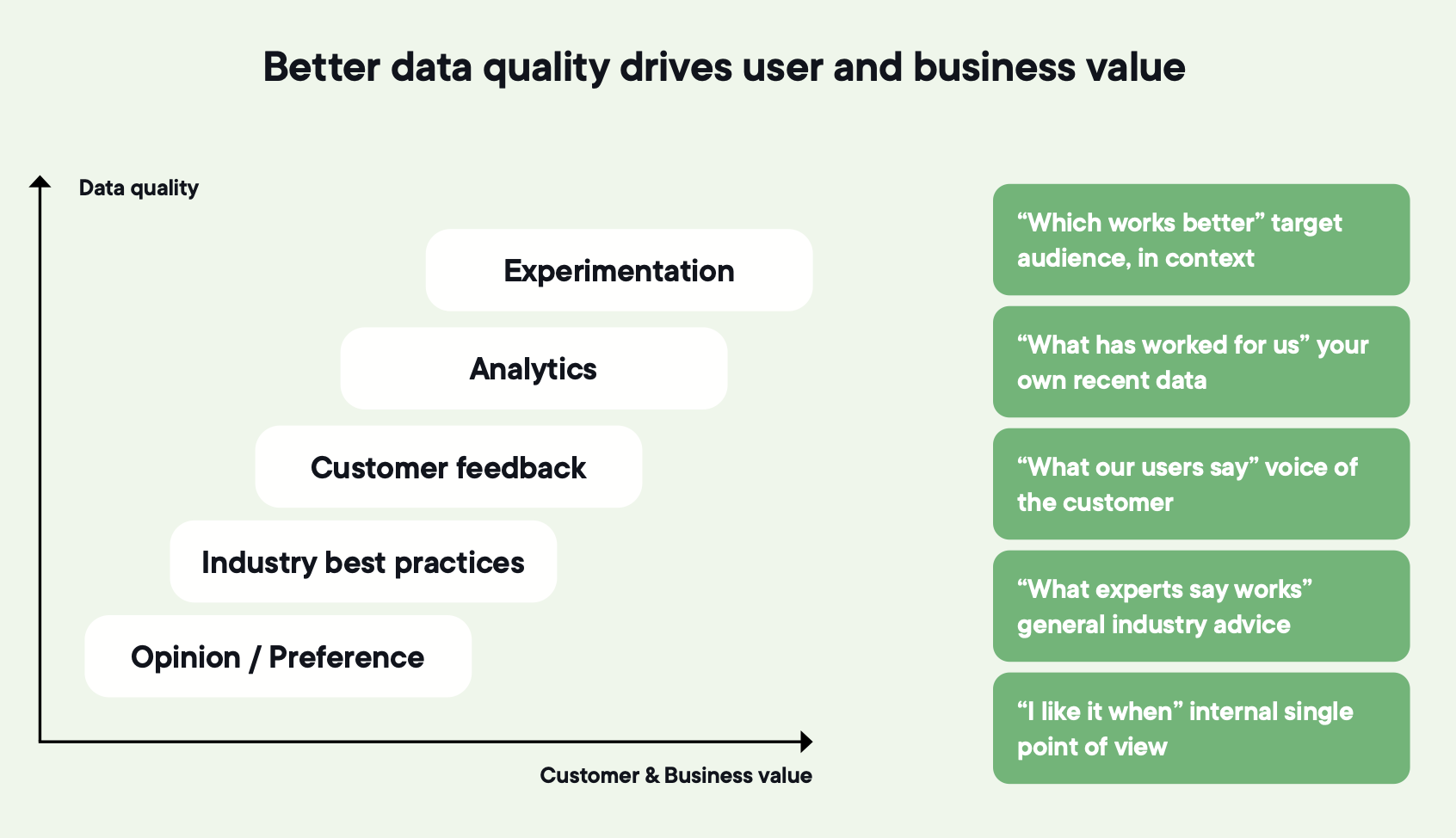
Wenn neun von zehn Ihrer Tests gewinnen, stimmt etwas nicht. Entweder ist die Kontrollvariante schwach, die Metrik zu ungenau oder Tests werden beendet, sobald sie grün werden. Die meisten Ideen bestehen den Kontakt mit den Nutzern nicht – und genau so sollte es sein.
Bewerten Sie den Nutzen des Experimentierens anhand des Uplifts über die Zeit, nicht anhand der Gewinne pro Quartal.
Die meisten Tests scheitern. Experimentieren funktioniert. Das ist das Paradoxon – und genau der Punkt.
2. Verknüpfen Sie jedes Experiment mit einem Geschäftsziel – oder erwarten Sie, dass es ignoriert wird
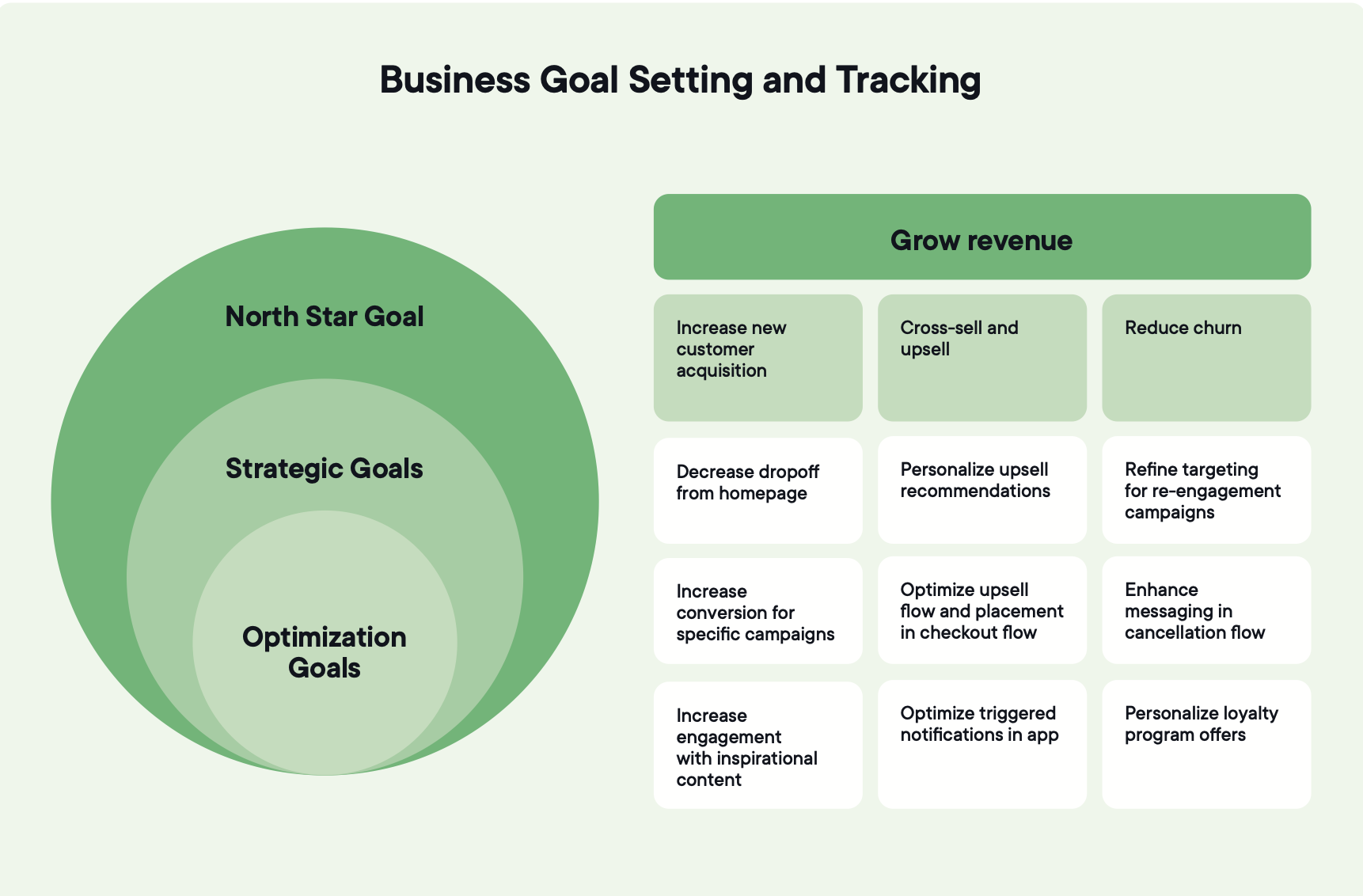
Programme in der Anfangsphase teilen in der Regel dieselben drei Probleme.
Experimente, die seitenbezogene Metriken bewegen, die von der Führungsebene nie betrachtet werden; Ergebnisse, die diskutiert, aber nie umgesetzt werden; und eine Wertschöpfungsgeschichte, die sich nicht kommunizieren lässt – sodass Erfolge isoliert bleiben, statt Dynamik aufzubauen.
Die Lösung besteht darin, die Verknüpfung explizit zu machen. Jedes Experiment wird an ein Ziel geknüpft, das dem Unternehmen bereits wichtig ist. Ergebnisse werden konsistent gemessen. Experimentieren wird als Entscheidungssystem behandelt, nicht als Nebenprojekt.
 Bildquelle: Optimizely
Bildquelle: Optimizely
Sie können statistisch einwandfreie Experimente durchführen und trotzdem Schwierigkeiten haben zu erklären, warum sie relevant sind. Genau so verlieren Programme ihre Finanzierung – selbst wenn die Arbeit gut ist.
3. Definieren Sie, was Erfolg für das Programm bedeutet – nicht nur für den einzelnen Test
Die meisten Teams messen einzelne Experimente und gehen davon aus, dass das Programm gesund ist, solange genug Tests laufen. Das ist es nicht.
Ein funktionierendes Programm braucht eigene Erfolgskriterien, unabhängig von einem einzelnen Ergebnis:
- Testen Sie häufig genug?
- Testen Sie gut?
- Sind die Änderungen bedeutend genug, um das Geschäft voranzubringen?
- Teilen Sie Ihre Erkenntnisse so, dass andere darauf aufbauen können?
Diese vier Fragen stehen über der Frage, ob ein einzelner Test gewonnen hat – und die Programme, die sie beantworten können, behalten ihren Platz am Tisch, wenn Budgets gekürzt werden.
4. Wenn Sie einen Test nicht auf den Nordstern zurückführen können, fehlt die Ausrichtung
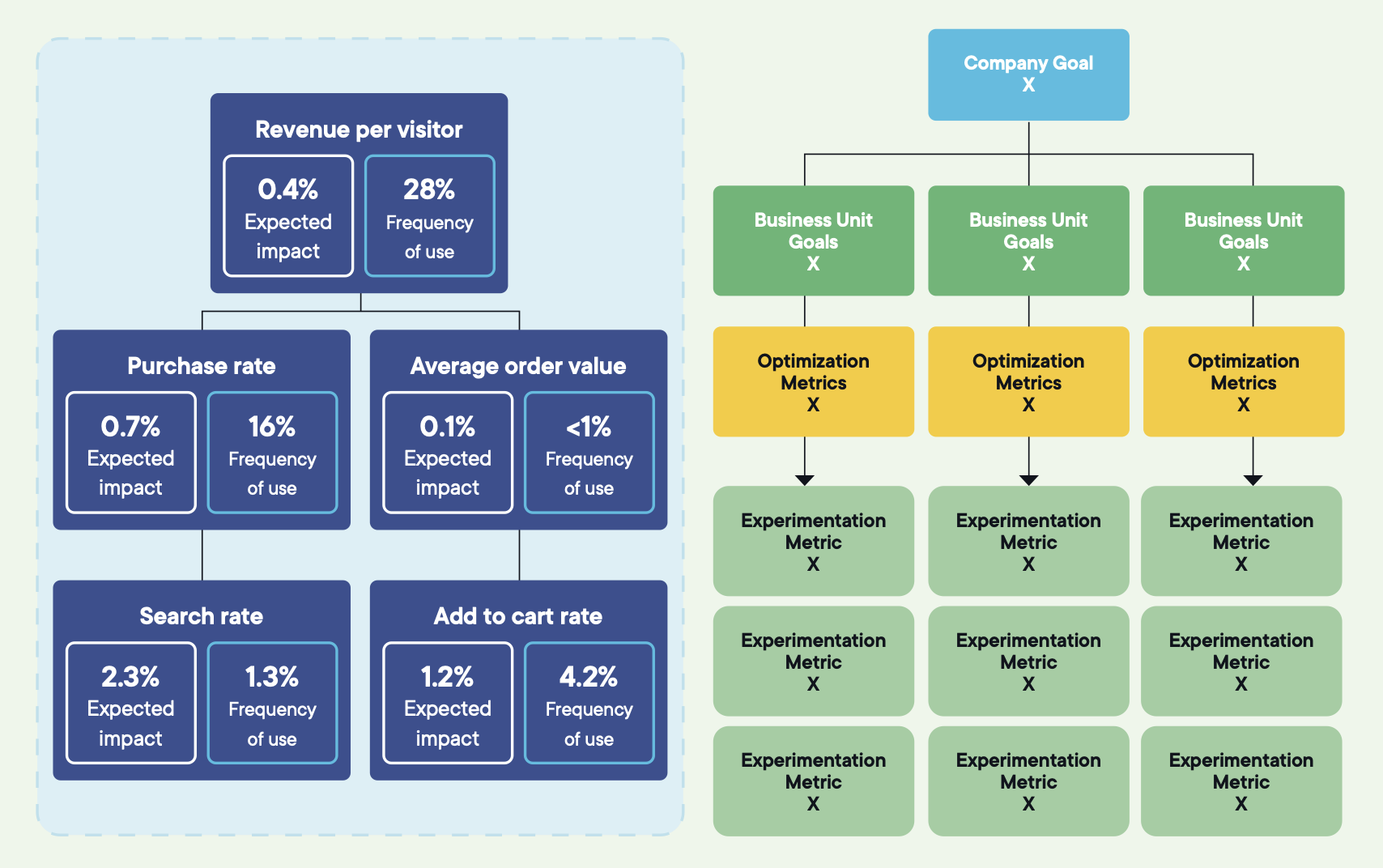
Starke Programme nutzen eine dreistufige Hierarchie.
-
Ein einziger Nordstern an der Spitze: das Ergebnis, auf das das Unternehmen letztlich hinarbeitet – wie Umsatz, Kundenbindung oder Customer Lifetime Value. Er gibt die Richtung vor, ist aber nicht die Metrik, gegen die Sie testen. Wenn jedes Experiment diese Metrik direkt bewegen soll, wird der Nordstern falsch eingesetzt.
-
Drei bis fünf strategische Metriken in der Mitte: die Hebel, die die Führungsebene bereits zur Leistungsbewertung nutzt. Conversion Rate, Akquisitionseffizienz, durchschnittlicher Bestellwert, Feature-Adoption.
-
Optimierungsziele am unteren Ende: die Nutzerverhalten, die ein einzelnes Experiment direkt beeinflussen kann. Warenkorb-Rate, Abbruchrate bei der Lieferung, Abschluss der Registrierung.
Jedes Experiment sollte sauber von einem Optimierungsziel über eine strategische Metrik bis zum Nordstern führen.
 Bildquelle: Optimizely
Bildquelle: Optimizely
Nehmen Sie ein beliebiges aktives Experiment und fragen Sie die verantwortliche Person, welche strategische Metrik es unterstützt und wie. Wenn die Antwort vage ist, erfüllt der Zielbaum seinen Zweck nicht.
5. Geschwindigkeit, Qualität und Umfang – messen Sie alle drei
Geschwindigkeit ist vor allem am Anfang wichtig, wenn die Kadenz der limitierende Faktor ist und das Team noch lernt, Tests zuverlässig auszuliefern.
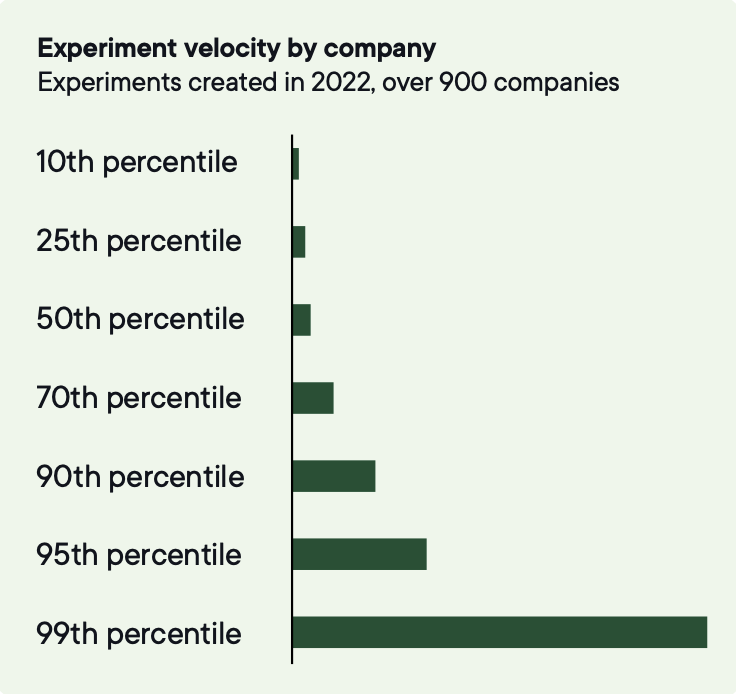
Das Medianunternehmen führt 34 Experimente pro Jahr durch. Die Top 3 % kommen auf über 500.
 Bildquelle: Optimizely
Bildquelle: Optimizely
Um zu den Top 10 % bei der Experiment-Geschwindigkeit zu gehören, müssen Unternehmen rund 200 Tests pro Jahr durchführen.
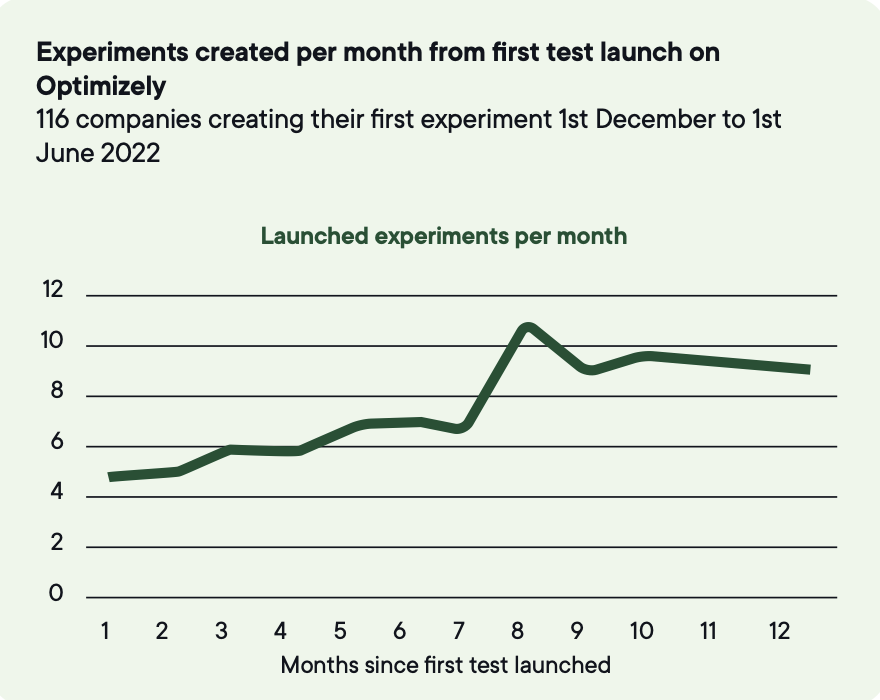 Bildquelle: Optimizely
Bildquelle: Optimizely
Volumen ist der Weg, um unvorhersehbare Einzelergebnisse in zuverlässige Verbesserung auf Programmebene umzuwandeln – denn die meisten Experimente erzielen keinen statistisch signifikanten Gewinn und Fortschritt entsteht erst, wenn häufig genug getestet wird, damit Gewinne entstehen können.
Doch Geschwindigkeit allein liefert denselben geschäftlichen Impact bei doppelten Kosten, sobald ein Programm skaliert. Die Teams, die weiter wachsen, messen zwei weitere Dimensionen.
Qualität zeigt, ob Sie über einzelne A/B-Tests hinausgehen und komplexere Ansätze verfolgen. Experimente mit vier Varianten liefern den 3,5-fachen erwarteten Impact eines typischen A/B-Tests. Programme, die nie über A/B-Testing hinausgehen, verschenken dieses Potenzial.
Umfang zeigt, ob Sie Änderungen testen, die bedeutend genug sind, um das Nutzerverhalten tatsächlich zu beeinflussen. Leicht erreichbare Ergebnisse sind schnell ausgeschöpft. Nachhaltiger Impact erfordert Tests über mehr Seiten, mehr Journeys und mehr Arten von Änderungen. Experimente, die drei oder mehr Änderungstypen kombinieren, erzielen die stärksten Ergebnisse.
Wenn Ihr Volumen steigt, aber die meisten Tests immer noch A gegen B auf derselben Handvoll Seiten vergleichen, wird das Programm geschäftiger, ohne besser zu werden.
6. Ein Programm ist ein Lebenszyklus, keine Warteschlange
Die meisten Programme laufen wie eine Warteschlange. Ideen werden eingereicht, Tests werden erstellt, Ergebnisse werden abgelegt und neue Ideen werden eingereicht. Die Arbeit geht weiter – und zwischen den Phasen gibt es keine Verbindung.
Ein Lebenszyklus hat sechs Phasen, und jede speist die nächste.
- Hypothesenentwicklung
- Priorisierung
- Planung und Design
- Durchführung und Monitoring
- Analyse und Interpretation
- Deployment und Iteration
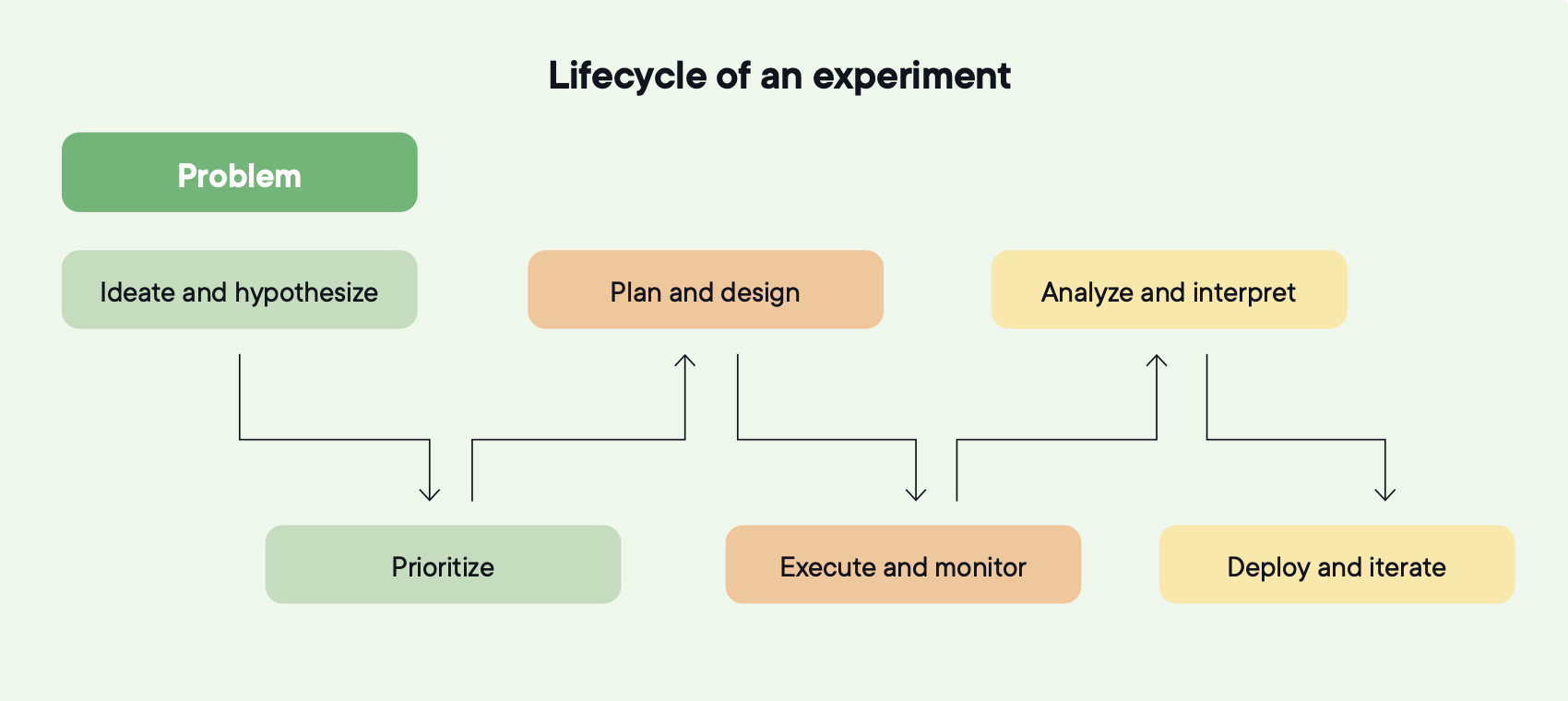 Bildquelle: Optimizely
Bildquelle: Optimizely
Die Analyse des letzten Quartals formt die Hypothesen des aktuellen Quartals. Die Priorisierung verschiebt sich, wenn ein Checkout-Test dem Team etwas über Liefergebühren beibringt. Das Deployment wird zum Input für das nächste Experiment – nicht zum Ende des aktuellen.
So hört ein Team auf, einfach Experimente durchzuführen, und beginnt, eine Experimentation-Funktion aufzubauen. Die Mechanik eines einzelnen Tests ist weniger wichtig als die Frage, ob der Kreislauf geschlossen wird.
7. Starten Sie mit dem Problem, nicht mit der Idee
Die meisten Experimente scheitern bereits in der Hypothesenphase – lange vor der Durchführung oder Analyse.
„Wir sollten eine längere Überschrift ausprobieren" ist eine Lösung auf der Suche nach einem Problem.
„Nutzer verstehen erst im letzten Checkout-Schritt, wie Liefergebühren funktionieren, und 25 % der befragten Nutzer geben dies als Grund für ihren Abbruch an" ist ein Problem, das spezifisch genug ist, um einen Test darauf aufzubauen.
Das Problem-Solution-Result-Framework (PSR) sichert diese Disziplin: ein validiertes Nutzer- oder Geschäftsproblem, eine vorgeschlagene Änderung zur Lösung und ein messbares Ergebnis, das den Erfolg anzeigen würde.
 Bildquelle: Optimizely
Bildquelle: Optimizely
Ein starkes Problem-Statement ist nutzerzentriert, evidenzbasiert, spezifisch – aber nicht präskriptiv hinsichtlich der Lösung – und aktuell relevant. Überspringen Sie diesen Schritt, testen Sie Meinungen.
8. Testen Sie drei bis fünf Lösungen pro Problem, nicht nur eine
Ein Team, das A gegen die Kontrollvariante testet, setzt pro Problem auf eine einzige Lösung. Ein Team, das drei bis fünf Varianten testet, prüft, ob einer von mehreren Ansätzen das Problem löst.
Das verbessert nicht nur Ihre Chancen. Es verändert die Arbeitsweise des Teams. Die Risikobereitschaft steigt, weil sicherere Optionen abgedeckt sind. Die Beteiligung wächst, weil mehr Beitragende ihre Ideen getestet sehen. Das Team erkundet mehrere Richtungen gleichzeitig, statt sich auf einen Weg festzulegen und wochenlang auf die Erkenntnis zu warten, dass er falsch war.
Das Testen von 4+ Varianten verändert das Teamverhalten:
- Die Risikobereitschaft steigt, weil sichere Optionen abgedeckt sind.
- Die Beteiligung wächst, weil mehr Beitragende ihre Ideen getestet sehen.
- Die Agilität verbessert sich, weil Teams mehrere Richtungen gleichzeitig erkunden.
9. Ihr Backlog ist Ihr Priorisierungsinstrument – oder Ihre Entschuldigung
Jedes Programm hat mehr Ideen als Kapazität. Ohne ein gemeinsames Priorisierungsmodell gewinnt der lauteste Stakeholder – und das Backlog beginnt, dem Organigramm zu ähneln.
RICE (Reach, Impact, Confidence, Effort) ist die gängige Wahl, weil es vier Abwägungen in einen vergleichbaren Score überführt.
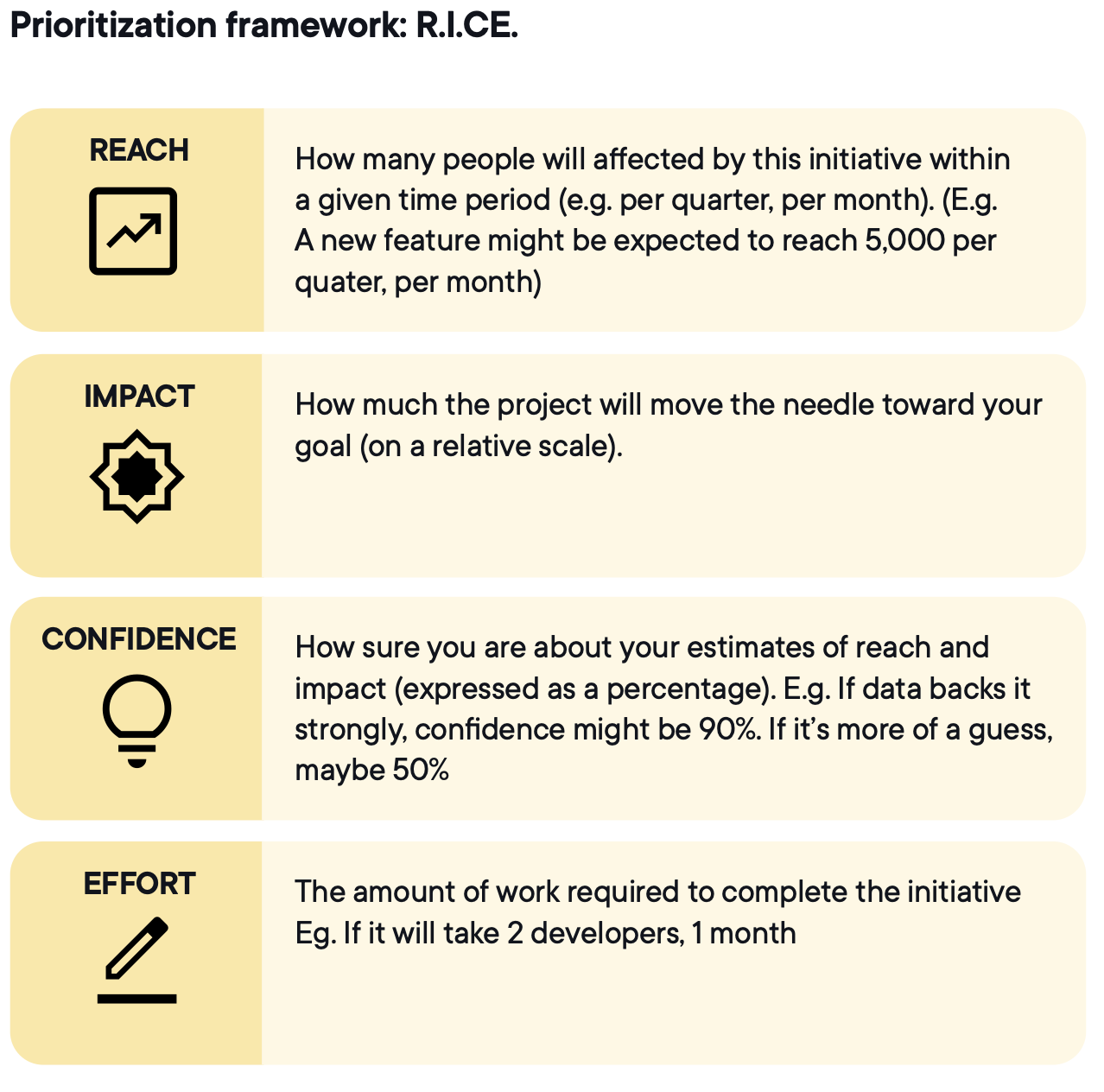 Bildquelle: Optimizely
Bildquelle: Optimizely
Ein Checkout-Flow-Test könnte bei Reach und Impact hoch abschneiden, aber Wochen an Engineering erfordern. Ein Copy-Test auf der Pricing-Seite hat möglicherweise einen niedrigeren Impact-Score, aber höhere Confidence und deutlich weniger Aufwand. RICE macht den Trade-off explizit, sodass die Priorisierung auf gemeinsamen Kriterien basiert statt auf Dringlichkeit oder Hierarchie.
Der Score soll die Diskussion starten, nicht beenden. Wenn dasselbe Team Ideen über die Zeit hinweg konsistent bewertet, wird das Backlog zu einer lebendigen Sicht auf die Experimentation-Strategie. Was gerade getestet wird, was als Nächstes kommt und welche Unsicherheiten die Organisation in welcher Reihenfolge zu klären beschlossen hat.
Fünf Dinge, die Sie vermeiden sollten:
- Impact aufblähen, um Ideen durchzusetzen
- Confidence als Intuition statt als Evidenz behandeln
- Reach-Einschränkungen ignorieren
- Aufwand unterschätzen, indem QA- und Analytics-Arbeit nicht berücksichtigt wird
- Den Score als endgültige Antwort behandeln statt als gerankte Ausgangsbasis
10. Jedes Experiment sollte das nächste klüger machen
Ein Programm entfaltet kumulative Wirkung, wenn Ergebnisse aktiv zukünftige Entscheidungen prägen. Bewährte Mechanismen werden wiederverwendet, widerlegte Annahmen nicht erneut getestet und Vertrauen wird durch Evidenz aufgebaut statt in jedem Zyklus auf Intuition zurückgesetzt. Vergangene Experimente werden bei der Ideenfindung und Planung herangezogen – nicht nur im Quartalsreport.
Wenn dieser Kreislauf funktioniert, wird Experimentieren zu einem gemeinsamen, evidenzbasierten Verständnis des Nutzerverhaltens, das jede Entscheidung beeinflusst – nicht nur die, die gerade getestet werden. Wenn er nicht funktioniert, produziert Experimentieren Aufzeichnungen statt Fortschritt.
Zwei Voraussetzungen müssen erfüllt sein:
1. Nicht-signifikante Ergebnisse müssen als Lernchance behandelt werden
Ein gesundes Programm hat eine Schlussfolgerungsrate von 35–40 %, was bedeutet, dass rund 60 % der Tests keinen klaren Gewinn oder Verlust hervorbringen. Die nützliche Frage nach einem nicht-signifikanten Test ist, was bei der Erkennung schiefgelaufen ist – nicht bei der Idee.
- War die Stichprobengröße zu klein?
- War die Metrik zu weit von der Änderung entfernt?
- War der Unterschied zwischen den Varianten zu gering?
2. Erkenntnisse müssen auffindbar sein
Die meisten Teams können dies nicht manuell aufrechterhalten, wenn das Testvolumen wächst. Erkenntnisse gehen unter, und verschiedene Teams testen dieselbe Hypothese erneut, ohne es zu wissen. Innerhalb von Optimizely entfallen inzwischen 58,74 % der gesamten Opal-Agent-Nutzung auf Experimentieren, und 19,54 % der Folgetests werden durch Agent-Empfehlungen auf Basis früherer Ergebnisse angestoßen. Agents greifen auf die Experimente, Ergebnisse und Flags des Teams zu und zeigen an, was bereits getestet wurde, bevor eine neue Hypothese formuliert wird.
Wenn Sie nicht klar benennen können, was das letzte Experiment gelehrt hat und welche neue Frage das nächste beantworten soll, iterieren Sie nicht. Sie ändern einfach nur Dinge.