In Zusammenarbeit mit einem Team von Statistikern der Stanford University haben wir Stats Engine entwickelt, ein neues statistisches Framework für A/B-Tests. Wir freuen uns, Ihnen mitteilen zu können, dass es ab dem 21. Januar 2015 die Ergebnisse für alle Optimizely-Kunden liefert.
Dieser Blogbeitrag ist etwas länger, denn wir möchten Ihnen transparent darlegen, warum wir diese Änderungen vornehmen, was genau diese Änderungen beinhalten und was dies für A/B-Tests im Allgemeinen bedeutet. Lesen Sie bis zum Ende, um mehr zu erfahren:
- Warum wir Stats Engine entwickelt haben:Das Internet ermöglicht es, Experimentergebnisse jederzeit einfach auszuwerten und Tests mit vielen Zielen und Variationen durchzuführen. In Kombination mit klassischer Statistik können diese intuitiven Vorgehensweisen die Wahrscheinlichkeit einer falschen Bestimmung einer Gewinn- oder Verlustvariante um mehr als das Fünffache erhöhen.
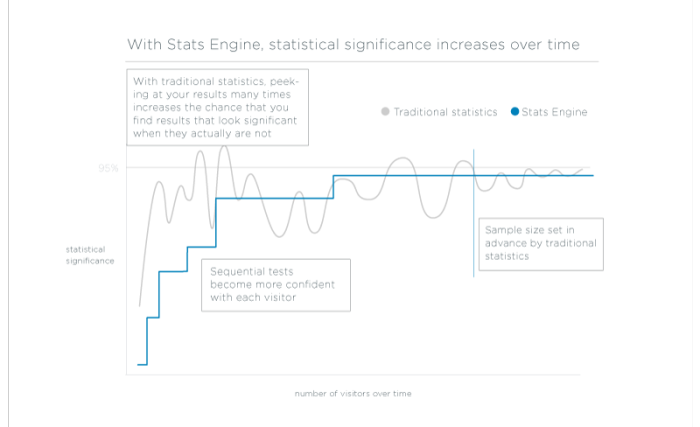
- So funktioniert es:Wir kombinieren sequentielles Testen und Kontrollen der Fehlentdeckungsrate, um Ergebnisse zu liefern, die unabhängig von der Stichprobengröße gültig sind und die von uns gemeldete Fehlerrate an die für Unternehmen relevante Fehlerquote anpassen.
- Warum es besser ist:Stats Engine kann die Wahrscheinlichkeit einer falschen Bestimmung einer Gewinn- oder Verlustvariante von 30 % auf 5 % reduzieren, ohne die Geschwindigkeit zu beeinträchtigen.
Warum wir eine neue Stats Engine entwickelt haben
Herkömmliche Statistik ist unintuitiv, leicht missbrauchbar und lässt Geld ungenutzt.
Tabelle. Um mit klassischen statistischen Methoden valide Ergebnisse aus A/B-Tests zu erhalten, befolgen sorgfältige Experimentatoren strenge Richtlinien: Sie legen im Voraus einen minimalen nachweisbaren Effekt und eine minimale Stichprobengröße fest, schauen nicht in die Ergebnisse hinein und testen nicht zu viele Ziele und Varianten gleichzeitig. Diese Richtlinien können aufwendig sein, und wenn sie nicht genau befolgt werden, können unbewusst Fehler in die Tests eingeschleust werden. Dies sind die Probleme dieser Richtlinien, die wir mit Stats Engine beheben wollen:- Die Festlegung eines messbaren Effekts und einer Stichprobengröße im Voraus ist ineffizient und nicht intuitiv.
- Ein Blick auf die Ergebnisse vor Erreichen dieser Stichprobengröße kann zu Fehlern führen, und Sie könnten auf vermeintliche Gewinner reagieren.
- Das gleichzeitige Testen zu vieler Ziele und Varianten erhöht die Fehlerrate aufgrund falscher Entdeckungen erheblich – eine Fehlerrate, die deutlich höher sein kann als die Rate falsch positiver Ergebnisse.
Die Festlegung einer Stichprobengröße und eines messbaren Effekts kann Ihren Prozess verlangsamen.
Die Festlegung einer Stichprobengröße vor Testbeginn hilft, Fehler bei traditionellen statistischen Methoden zu vermeiden. Um eine Stichprobengröße festzulegen, müssen Sie außerdem den minimal messbaren Effekt (MDE) oder die erwartete Steigerung der Konversionsrate abschätzen, die Sie in Ihrem Test erzielen möchten. Eine falsche Annahme kann die Testgeschwindigkeit erheblich beeinträchtigen.
Legt man einen kleinen Effekt fest, muss man auf eine große Stichprobe warten, um die Signifikanz der Ergebnisse zu überprüfen. Legt man einen größeren Effekt fest, riskiert man, kleinere Verbesserungen zu verpassen. Das ist nicht nur ineffizient, sondern auch unrealistisch. Die meisten führen Tests durch, weil sie nicht wissen, was passieren wird, und sich im Voraus auf eine hypothetische Verbesserung festzulegen, ist wenig sinnvoll.
Das ständige Überprüfen der Ergebnisse erhöht die Fehlerquote.
Wenn Daten in Echtzeit in Ihr Experiment fließen, ist es verlockend, die Ergebnisse ständig zu überprüfen.
Sie möchten einen erfolgreichen Test so schnell wie möglich implementieren, um Ihr Unternehmen zu verbessern, oder einen ergebnislosen Test so früh wie möglich abbrechen, um weitere Hypothesen zu testen.Statistiker nennen dieses ständige Überprüfen „kontinuierliches Monitoring“. Dadurch erhöht sich die Wahrscheinlichkeit, ein positives Ergebnis zu finden, obwohl eigentlich keines existiert (kontinuierliches Monitoring ist natürlich nur dann problematisch, wenn Sie den Test vorzeitig abbrechen, aber Sie verstehen das Prinzip). Das Finden eines nicht signifikanten Gewinners wird als falsch-positiv oder Fehler 1. Art bezeichnet.
Jeder Test auf statistische Signifikanz birgt ein gewisses Fehlerrisiko.
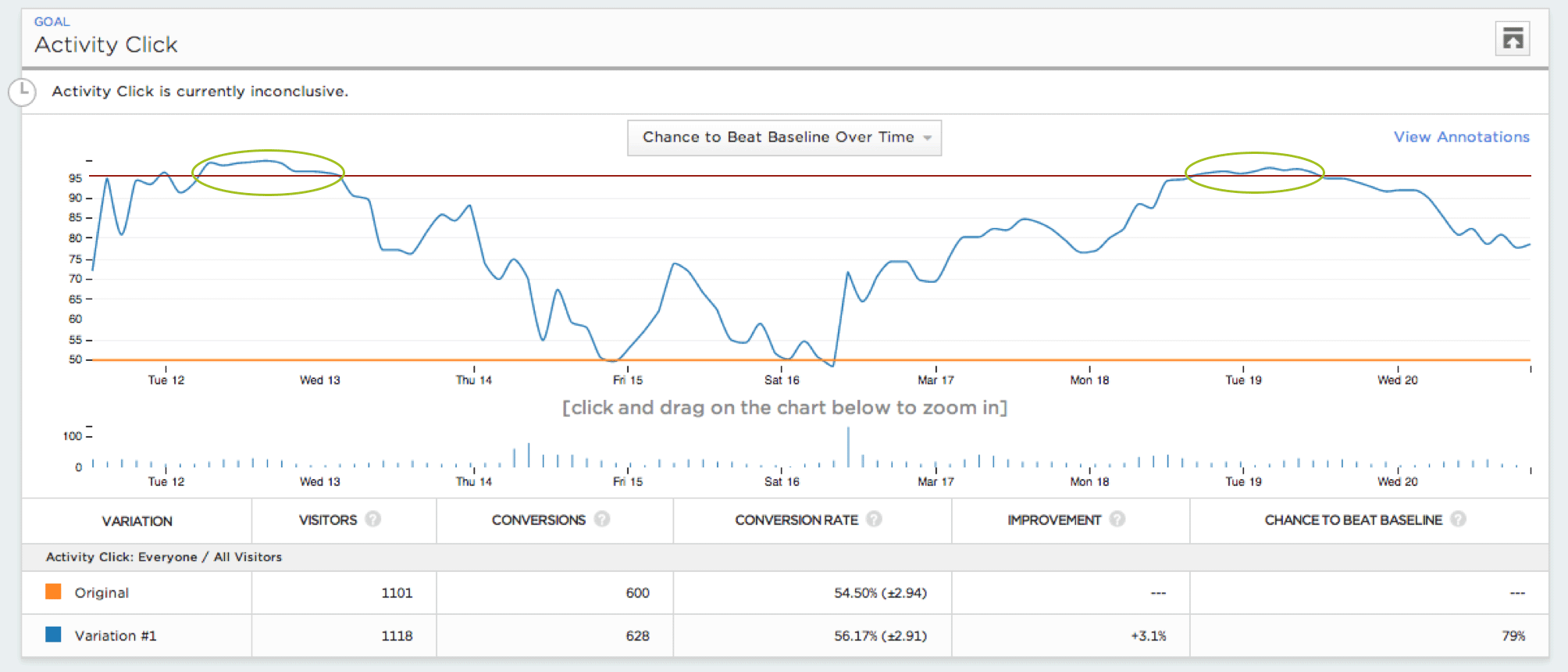
Einen Test mit einer statistischen Signifikanz von 95 % durchzuführen (also einen t-Test mit einem Alpha-Wert von 0,05) bedeutet, dass Sie eine Wahrscheinlichkeit von 5 % akzeptieren, dass ein A/A-Test ohne tatsächlichen Unterschied zwischen den Varianten ein signifikantes Ergebnis liefert.Um zu veranschaulichen, wie gefährlich kontinuierliches Monitoring sein kann, haben wir Millionen von A/A-Tests mit 5.000 Besuchern simuliert und die Fehlerwahrscheinlichkeit unter verschiedenen Strategien für kontinuierliches Monitoring bewertet. Wir stellten fest, dass selbst konservative Strategien die Fehlerrate von einem Zielwert von 5 % auf über 25 % erhöhen können.
In unserer Untersuchung haben mehr als 57 % der simulierten A/A-Tests mindestens einmal fälschlicherweise einen Gewinner oder Verlierer ermittelt, wenn auch nur kurz. Mit anderen Worten: Hätten Sie diese Tests beobachtet, hätten Sie sich möglicherweise gewundert, warum Ihr A/A-Test einen Gewinner ausgerufen hat. Der Anstieg der Fehlerrate ist auch dann signifikant, wenn man nicht jeden Besucher einzeln überprüft. Bei einer Überprüfung alle 500 Besucher steigt die Wahrscheinlichkeit einer falschen Angabe auf 26 %, bei einer Überprüfung alle 1000 Besucher auf 20 %.