From ideation to results: AI experimentation is changing how we run tests (for real)

Here is how experimentation used to work. You had an idea. It went to a developer. The developer had other priorities. Your idea waited.
By the time it shipped, weeks had passed. Sometimes more. And then, analysis waited on the one person who understood the data. Variations sat in a backlog behind three other releases. Results took so long to interpret that the next test was already overdue before anyone had acted on the last one.
AI does not change what good experimentation looks like. It removes what was getting in the way.
How does AI makes it easier to run more quality experiments?
58.74% of all Optimizely Opal agent usage is experimentation.
AI workflow agents now handle the work that used to involve waiting at every stage of the experimentation cycle.
Ideas get generated faster and grounded in what has actually worked before.
Test plans get structured in seconds, with the right metrics from the start. Variations get built without touching the dev queue. Results get summarized before the insight has a chance to go cold.
The result is a program where each stage feeds the next, and nothing stalls waiting for someone to have time.
Still, AI implementations are struggling because most AI tools have no memory of your program.
So, does AI even work reliably, at scale, and with accountability and governance?
To find an answer to this problem, we analyzed data across 47,000 Optimizely Opal interactions across 900 companies. What we found was that AI's impact is stuck at the individual level.
Here's the full AI experimentation benchmark report.
AI implementations are failing without context
Most AI tools give you a response. When your AI has no memory of your program, problems show up:
- Teams repeat tests they have already run because nothing connects past learnings to new ideas.
- It gets harder to step back and understand how the program is actually performing because there is no thread running through it.
- When teams do use AI for suggestions, they spend more time editing outputs to fit their context than they save generating them.
When AI understands your existing experiments, metrics, feature flags, and program history, ideas stop repeating work you have already done, test plans reflect what your program has actually learned, and when a test concludes, the next step builds on what you now know rather than starting over.
Experimentation ROI is not in more ideas. It is in the relevant ones. Not in more tests, but a program where every learning compounds.
Optimizely Opal understands your full experimentation program. It has:
- Program-level reporting: Which experiments launched or concluded in a given timeframe, which performed best, and how win rates are trending.
- Ideation based on past outcomes: What to test next, drawn from your experiment history rather than generic suggestions.
- Personalization campaign questions: Campaign setup, which campaigns were created, and when. This applies to standalone Personalization customers too.
Workflow agents execute across the full lifecycle and carry what came before into every step that follows.
AI agents across the experimentation workflow
Teams using agents across the full experimentation lifecycle are running 78.7% more experiments, launching 24.1% more personalization campaigns, and seeing win rates lift by 9.3%. More tests are reaching conclusions, too, not just getting started.
Experimentation is where the operational drag is highest and where workflow agents are creating the most value.
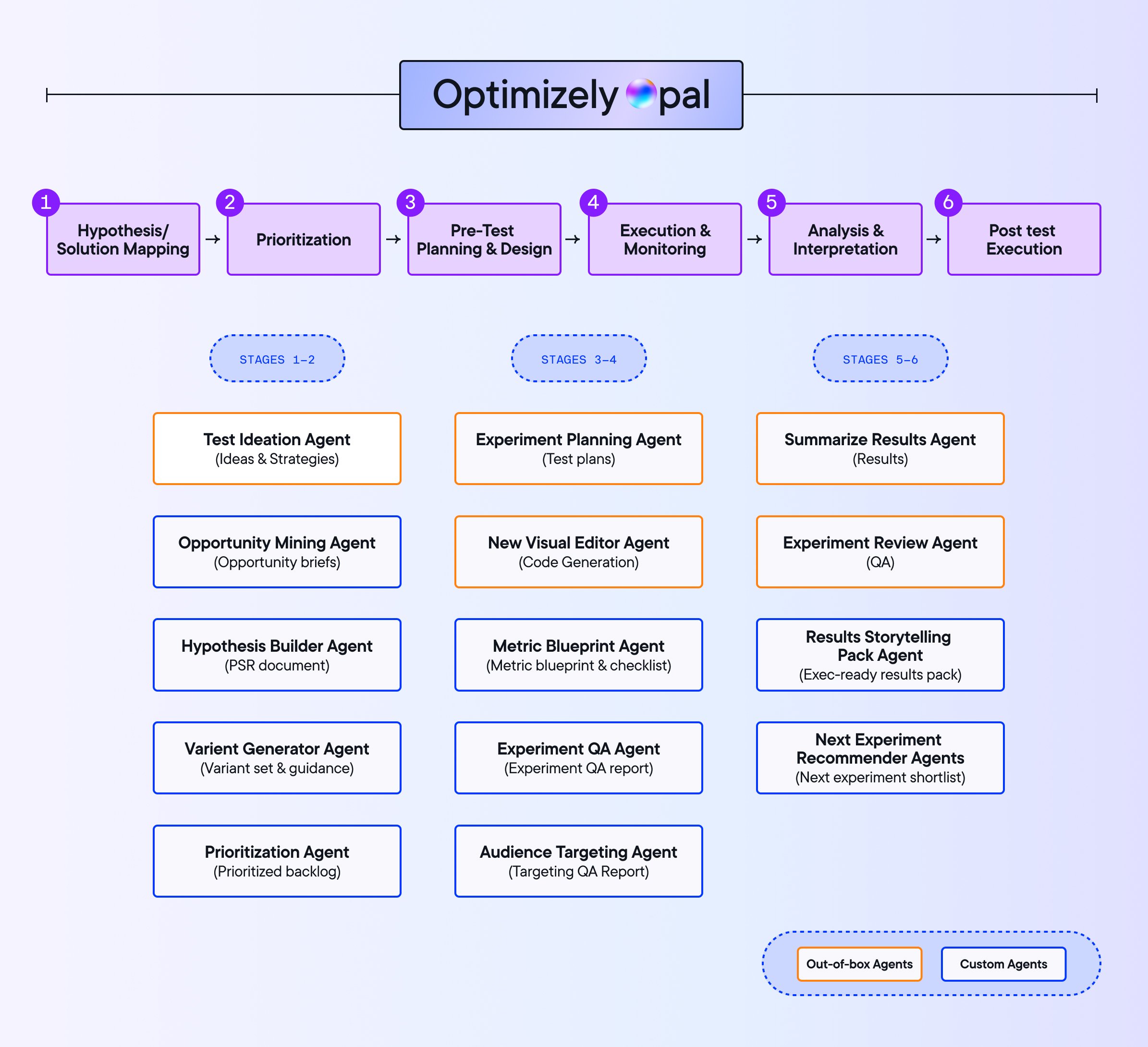
Image source: Optimizely
Optimizely Opal agents cover the full experimentation lifecycle from ideation through post-test execution. Out-of-the-box agents handle the most common stages. Teams can also build custom agents for workflows specific to their program.
1. Experiment ideation agent
Run more tests without adding headcount.
The Ideation Agent draws on patterns from your past learnings. Point it at a URL, share your goals, and it generates ideas. Because it knows what you have already tested, it is not recycling old ground.
Teams using it are seeing 18% more tests created and 33% faster run times.
2. Experiment planning agent
Hypothesis to launch-ready plan in seconds
The planning agent sets up experiments with the right metrics, audience size, and run time from the start.
It flags when a chosen metric will take too long to reach statistical significance and suggests alternatives. Advanced techniques like CUPED are surfaced where relevant.
Teams using it are seeing experiments start 19% faster and reach statistical significance 25% faster.
3. Variation development agent
No queue, no dependency.
The biggest bottleneck in experimentation is getting ideas built.
Tests that make a real impact usually need custom code. That means a dev ticket, a queue, a sprint cycle, and a lead time just to get prioritized.
The variation development agent lets marketing and product teams build experiment variations themselves, inside the Visual Editor, without writing code.
Two examples of what that looks like:
- Adding a button across an entire page: You describe what you want. The agent applies a consistent change across every product page in seconds, no dev ticket needed.
- Adding a new section to a page: Ask Optimizely Opal to introduce a value proposition block or a trust signal. It generates the section, places it correctly, and keeps branding consistent.
The agent checks for conflicts automatically, cutting QA time and reducing failed builds.
Our analysis of 127,000 experiments found that teams achieve the highest impact at under 10 tests per engineer. The Variation Development Agent is what makes that ratio sustainable as programs scale.
4. Experiment summary agent
Points directly to the next test worth running
The summary agent reviews your metrics when a test concludes, generates a plain-language summary, and recommends what to do next. It surfaces patterns teams would otherwise miss.
6.8% of experiments are already being summarized by agents. 19.54% of follow-up tests are driven by agent recommendations.
What is our approach to AI governance?
The questions we hear most from teams adopting Opal are not about whether AI works. They are about control.
How do we make sure AI-generated content does not go live without our team checking it first?
Who actually has access to launch these tests?
Without answers to those questions, things go sideways.
Different teams run overlapping tests on the same audience without realizing it. AI outputs ship without anyone checking them against brand standards. Leadership has no visibility into what is actually running. And when something goes wrong, nobody knows where to start.
Optimizely Opal is built with governance in mind:
- Risk mitigation and brand safety: AI generates quickly. Governance ensures what goes live reflects your standards, not just what the model produced.
- Cross-functional alignment: Defined roles and processes keep experiments coordinated. No two teams accidentally testing the same audience with conflicting variants.
- Single source of truth: How does your organization define a winning experiment? Governance answers that question once, consistently, so programs can scale without revisiting it every time.
- Future-proofing AI adoption: When roles like Admin, User, and Agent Builder are clearly defined and documented, the AI black box stops feeling like a black box. Leadership builds confidence. Adoption follows.
Still got more questions? We got them covered.
Frequently asked questions about governance in AI
Wrapping up
The potential of AI in experimentation is clear through accelerated workflows and more time for strategic thinking. But what excites us most at Optimizely isn't just AI assistance, it's the evolution toward true AI partnership.
We're building an ecosystem where AI agents work proactively across your entire marketing and experimentation ecosystem, from surfacing test opportunities to ensuring brand compliance and connecting cross-product insights.
Whether you're personalizing customer experiences in retail or optimizing feature rollouts in software, AI-powered experimentation gives you the edge to lead the change.
Frequently asked questions about AI experimentation

Yes, a marketer and a copywriter... but more lame than most. I try to use AI and here to be a thinker rather than just a publisher, but really just think with my...


- Last modified: 3/12/2026 1:45:19 PM