Building a culture of experimentation has the potential to simplify your customer experiences and increase conversions...
However, it can also hurt you if you can’t reach statistically significant results.
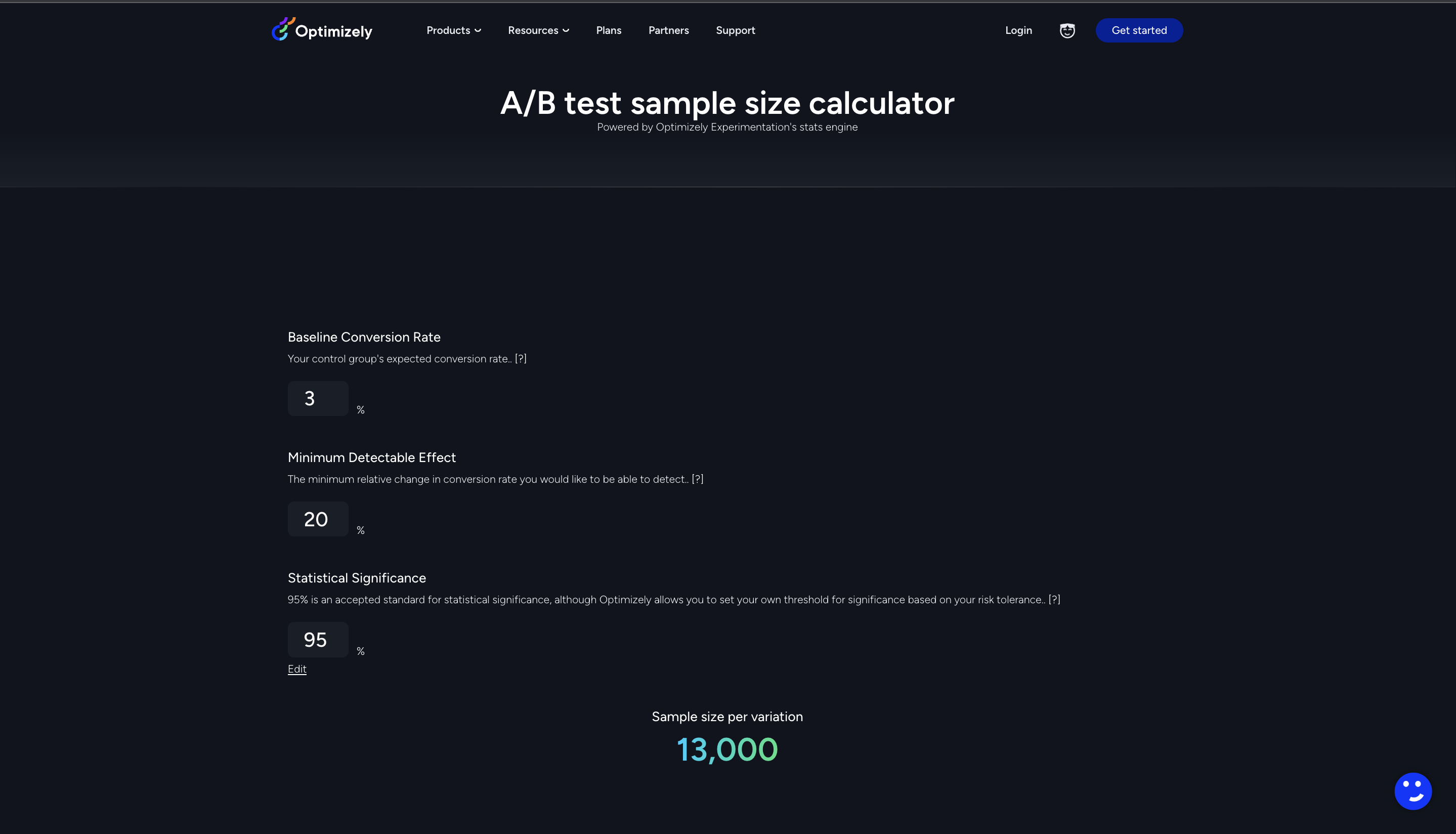
To start, you need an adequate sample size to run a test without any margin of error. Next, you run these tests for a period long enough to get statistically significant results.
As you’re running experiments and a/b tests, it’s better to stop a test only when your variations reach significance instead of a random sample size. If some of the variations have not reached significance, decide if you want to wait for the number of visitors to increase or a larger sample size.
In this article, see how to estimate experiment length in advance, measure results through market research, and calculate how much traffic you’ll need for your conversion rate experiments.